语音智能体概述

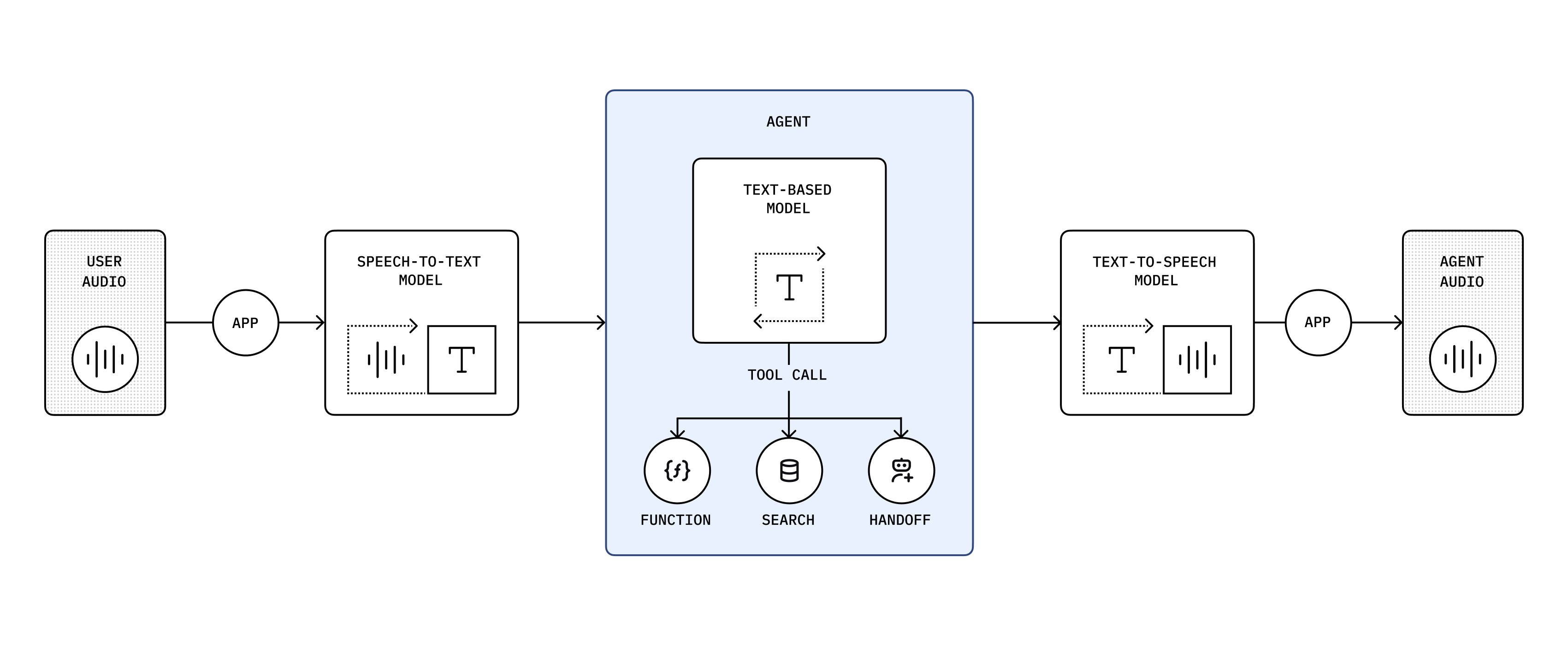
语音智能体让你可以基于 OpenAI 语音到语音模型构建低延迟的语音交互界面。SDK 保留了 Realtime API 的心智模型,同时用 RealtimeAgent、RealtimeSession 和传输辅助工具封装原始事件流,让工具、护栏、交接和会话历史更易使用。
在底层,官方基于 WebRTC 的 Realtime API、Realtime 对话和语音活动检测指南中的相同 Realtime 概念仍然适用。Voice Agents SDK 在该 API 之上添加了一个 TypeScript 优先层,让你可以专注于产品逻辑,而无需从零开始重建传输和事件处理。
快速开始 使用 OpenAI Agents SDK,在几分钟内构建你的第一个实时语音助手。
构建语音智能体 了解 SDK 中的会话生命周期、VAD、中断、多模态输入、工具和历史记录如何工作。
传输机制 在 WebRTC、WebSocket、SIP 或自定义传输之间做选择,并了解何时需要下探到原始事件。
SDK 新增内容
Section titled “SDK 新增内容”- 面向浏览器优先的 WebRTC 设置,支持临时客户端令牌。
- 服务器端 WebSocket 和 SIP 传输选项。
- 自动中断处理和本地对话历史更新。
- 通过实时交接实现多智能体编排。
- 函数工具、托管 MCP 工具、审批和委派模式。
- 面向实时语音交互的输出护栏和追踪支持。
| 如果你需要… | 前往这里 |
|---|---|
| 使用 WebRTC 和临时令牌安全地连接浏览器客户端 | 快速开始 |
| 了解会话生命周期、VAD、中断、图像输入、工具和历史记录 | 构建语音智能体 |
| 在 WebRTC、WebSocket、SIP 和自定义传输之间做选择 | 传输机制 |
| 在 Twilio 上运行电话或电信体验 | Twilio 上的实时智能体 |
| 从 Cloudflare Workers 或其他 workerd 运行时连接 | Cloudflare 上的实时智能体 |
语音到语音的优势
Section titled “语音到语音的优势”语音到语音模型会直接处理用户音频,因此你不必为每一轮对话构建单独的语音转文本、文本推理和文本转语音链路。这可以降低延迟,并让实时应用中的中断、文本与语音混合输入以及工具调用感觉自然得多。