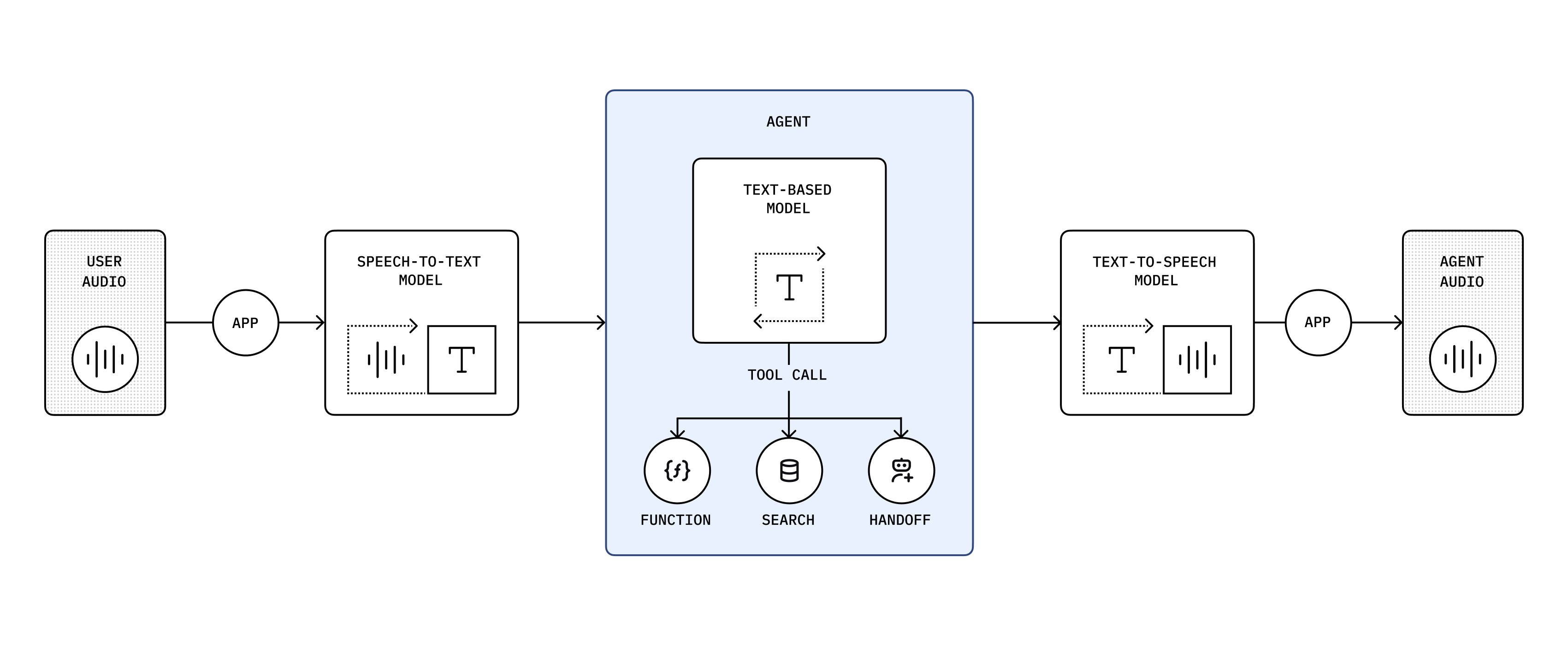
音声エージェントの概要

音声エージェントを使うと、OpenAI の speech-to-speech モデル上に低レイテンシの音声インターフェイスを構築できます。SDK は Realtime API の考え方をそのまま保ちながら、元のイベントフローを RealtimeAgent、RealtimeSession、トランスポートヘルパーでラップし、ツール、ガードレール、ハンドオフ、セッション履歴を扱いやすくします。
内部では、公式の WebRTC を用いた Realtime API、Realtime 会話、音声活動検出 ガイドで説明されている同じ Realtime のコンセプトが引き続き適用されます。Voice Agents SDK は、その API の上に TypeScript ファーストのレイヤーを追加するため、トランスポートやイベント処理をゼロから作り直すのではなく、プロダクトロジックに集中できます。
ここから開始
Section titled “ここから開始” クイックスタート OpenAI Agents SDK を使って、ほんの数分で最初のリアルタイム音声アシスタントを構築します。
音声エージェントの構築 SDK におけるセッションライフサイクル、VAD、割り込み、マルチモーダル入力、ツール、履歴の仕組みを学びます。
リアルタイムトランスポート WebRTC、WebSocket、SIP、カスタムトランスポートから選択し、いつ元のイベントまで下りるべきかを理解します。
SDK による追加要素
Section titled “SDK による追加要素”- ブラウザファーストの WebRTC セットアップと一時的なクライアントトークン
- サーバー側の WebSocket および SIP トランスポートオプション
- 自動的な割り込み処理とローカルの会話履歴更新
- リアルタイムハンドオフによるマルチエージェントオーケストレーション
- 関数ツール、ホスト型 MCP ツール、承認、委任パターン
- ライブ音声インタラクション向けの出力ガードレールとトレーシング対応
次のページの選択
Section titled “次のページの選択”| したいこと | 参照先 |
|---|---|
| WebRTC と一時的なトークンでブラウザクライアントを安全に接続する | クイックスタート |
| セッションライフサイクル、VAD、割り込み、画像入力、ツール、履歴を理解する | 音声エージェントの構築 |
| WebRTC、WebSocket、SIP、カスタムトランスポートのどれを使うか判断する | リアルタイムトランスポート |
| Twilio で電話またはテレフォニー体験を実行する | Twilio 上の Realtime Agent |
| Cloudflare Workers またはその他の workerd ランタイムから接続する | Cloudflare 上の Realtime Agent |
Speech-to-speech の利点
Section titled “Speech-to-speech の利点”Speech-to-speech モデルはユーザーの音声を直接処理するため、ターンごとに個別の音声認識、テキスト推論、音声合成のチェーンを構築する必要がありません。これによりレイテンシを抑えられ、リアルタイムアプリケーションでの割り込み、テキストと音声が混在する入力、ツール呼び出しがより自然に感じられます。