音声エージェントの構築
セッションのセットアップ
Section titled “セッションのセットアップ”デフォルトの OpenAIRealtimeWebRTC のような一部のトランスポート層では、音声入力と出力が自動的に処理されます。OpenAIRealtimeWebSocket のような他のトランスポート機構では、セッションの音声を自分で処理する必要があります:
import { RealtimeAgent, RealtimeSession, TransportLayerAudio,} from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'My agent' });const session = new RealtimeSession(agent);const newlyRecordedAudio = new ArrayBuffer(0);
session.on('audio', (event: TransportLayerAudio) => { // play your audio});
// send new audio to the agentsession.sendAudio(newlyRecordedAudio);基礎となるトランスポートが対応している場合、session.muted は現在のミュート状態を報告し、session.mute(true | false) はマイクキャプチャを切り替えます。OpenAIRealtimeWebSocket はミュート機能を実装していません。session.muted は null を返し、session.mute() は例外をスローします。そのため WebSocket 構成では、マイクを再びライブにするまで、自分の側でキャプチャを一時停止し、sendAudio() の呼び出しを停止してください。
セッション設定
Section titled “セッション設定”RealtimeSession を作成するときに、通常は model オプションと config オブジェクトを通じて、セッション自体を設定します。connect(...) は任意のセッションフィールドではなく、認証情報、エンドポイント URL、SIP コールのアタッチメントなど、接続時の事項のためのものです。
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'Greeter', instructions: 'Greet the user with cheer and answer questions.',});
const session = new RealtimeSession(agent, { model: 'gpt-realtime-2.1', config: { outputModalities: ['audio'], reasoning: { effort: 'low', }, parallelToolCalls: true, audio: { input: { format: 'pcm16', transcription: { model: 'gpt-4o-mini-transcribe', }, }, output: { format: 'pcm16', }, }, },});内部では、SDK がこの設定を Realtime session.update の形式に正規化します。RealtimeSessionConfig に対応するプロパティがない元のセッションフィールドが必要な場合は、providerData を使用するか、session.transport.sendEvent(...) で元の session.update を送信してください。
新しい SDK 設定形式である outputModalities、audio.input、audio.output を優先してください。modalities、inputAudioFormat、outputAudioFormat、inputAudioTranscription、turnDetection などの古い SDK エイリアスも後方互換性のために正規化されますが、新しいコードではここに示すネストされた audio 構造を使用してください。
gpt-realtime-2.1 などの推論対応 Realtime モデルでは、セッション設定で reasoning.effort を設定します。推論 effort を高くすると、レイテンシとトークン使用量が増える可能性があります。モデルが複数のツールを並列に呼び出せるかどうかを制御したい場合は、parallelToolCalls も設定できます。
音声対音声セッションでは、通常の選択肢は outputModalities: ['audio'] で、音声出力に加えてトランスクリプトが得られます。テキストのみの応答が必要な場合にのみ ['text'] に切り替えてください。
新しく追加されたパラメーターで RealtimeSessionConfig に対応するパラメーターがないものについては、providerData を使用できます。providerData に渡されたものはすべて、元の session オブジェクトの一部として転送されます。
構築時に設定できる追加の RealtimeSession オプション:
| オプション | 型 | 目的 |
|---|---|---|
context | TContext | セッションコンテキストにマージされる追加のローカルコンテキスト |
historyStoreAudio | boolean | ローカル履歴スナップショットに音声データを保存(デフォルトでは無効) |
outputGuardrails | RealtimeOutputGuardrail[] | セッションの出力ガードレール(ガードレール を参照) |
outputGuardrailSettings | { debounceTextLength?: number } | ガードレールの実行間隔。デフォルトは 100。完全なテキストが利用可能になった時点で 1 回だけ実行するには -1 を使用 |
tracingDisabled | boolean | セッションのトレーシングを無効化 |
groupId | string | セッション間またはバックエンド実行間でトレースをグループ化。workflowName が必要 |
traceMetadata | Record<string, any> | セッショントレースに添付するカスタムメタデータ。workflowName が必要 |
workflowName | string | トレースワークフローのわかりやすい名前 |
automaticallyTriggerResponseForMcpToolCalls | boolean | MCP ツール呼び出しが完了したときにモデル応答を自動トリガー(デフォルト: true) |
toolErrorFormatter | ToolErrorFormatter | モデルに返すツール承認拒否メッセージをカスタマイズ |
toolExecution | RealtimeToolExecutionConfig | ローカル Realtime 関数ツールの SDK 側実行設定。承認待ちリクエストの前に入力ガードレールを実行するには preApprovalInputGuardrails: true を設定 |
connect(...) オプション:
| オプション | 型 | 目的 |
|---|---|---|
apiKey | string | (() => string | Promise<string>) | この接続で使用する API キー(または遅延ローダー) |
model | OpenAIRealtimeModels | string | トランスポートレベルのオプション型に存在します。RealtimeSession ではコンストラクターでモデルを設定します。元のトランスポートでは接続時にモデルも使用できます |
url | string | 任意のカスタム Realtime エンドポイント URL |
callId | string | 既存の SIP 開始コール/セッションにアタッチ |
会話ライフサイクル
Section titled “会話ライフサイクル”RealtimeSession は長期間維持される Realtime 接続の上に位置します。会話履歴のローカルコピーを保持し、トランスポートイベントをリッスンし、ツールと出力ガードレールを実行し、アクティブなエージェント設定をトランスポートと同期された状態に保ちます。
基礎となる API の挙動も重要です:
- 正常に接続すると
session.createdイベントで開始し、その後の設定変更によってsession.updatedが生成されます。 - ほとんどのセッションプロパティは時間の経過に伴って変更できますが、
modelは会話中に変更できず、voiceはセッションが音声出力を生成する前にのみ変更できます。また、Realtime API では有効化後にトレーシングを変更できないため、トレーシングは最初に決めておく必要があります。 - 現在 Realtime API は、単一セッションを 60 分に制限しています。
- 入力音声の文字起こしは非同期なので、最新の発話のトランスクリプトは、応答生成がすでに開始された後に届くことがあります。
SDK レイヤーでは、await session.connect() は「トランスポートが会話を開始できる程度に準備できた」ことを意味しますが、正確な時点はトランスポートによって異なります:
- デフォルトのブラウザー WebRTC トランスポートでは、SDK はデータチャネルが開くとすぐに最初の
session.updateを送信し、connect()を解決する前に対応するsession.updatedイベントを待とうとします。これは、instructions、tools、modalities が適用される前に音声がサーバーに届くのを避けるためです。その確認応答が届かない場合、connect()は短いタイムアウト後に解決するフォールバックを行います。 - デフォルトのサーバー側 WebSocket トランスポートでは、ソケットが開き、初期設定が送信されると
connect()が解決します。したがって、対応するsession.updatedイベントはconnect()がすでに解決した後に届く可能性があります。
元のイベントモデルが必要な場合は、このページとあわせて公式の Realtime conversations ガイド を参照してください。
インタラクションフロー
Section titled “インタラクションフロー”ターン検出と音声アクティビティ検出
Section titled “ターン検出と音声アクティビティ検出”デフォルトでは、Realtime セッションは組み込みの音声アクティビティ検出(VAD)を使用するため、API はユーザーがいつ話し始め/話し終えたか、いつ応答を作成するかを判断できます。SDK はこれを audio.input.turnDetection を通じて公開します。
import { RealtimeSession } from '@openai/agents/realtime';import { agent } from './agent';
const session = new RealtimeSession(agent, { model: 'gpt-realtime-2.1', config: { audio: { input: { turnDetection: { type: 'semantic_vad', eagerness: 'medium', createResponse: true, interruptResponse: true, }, }, }, },});一般的なモードは 2 つあります:
semantic_vadは、より自然なターン境界を目指し、ユーザーがまだ話し終えていないように聞こえる場合には少し長く待つことがあります。server_vadは、よりしきい値駆動で、threshold、prefixPaddingMs、silenceDurationMs、idleTimeoutMsなどの設定を公開します。
ターン境界を自分で管理したい場合は、audio.input.turnDetection を null に設定します。公式の 音声アクティビティ検出ガイド と Realtime conversations ガイド では、基礎となる挙動についてさらに詳しく説明されています。
VAD が有効な場合、エージェントの発話中に話しかけると、現在の応答を割り込めます。WebSocket トランスポートでは、SDK は input_audio_buffer.speech_started をリッスンし、ユーザーが実際に聞いたところまでアシスタント音声を切り詰め、audio_interrupted イベントを発行します。このイベントは、WebSocket 構成で再生を自分で管理する場合に特に便利です。
import { session } from './agent';
session.on('audio_interrupted', () => { // handle local playback interruption});手動停止ボタンを公開したい場合は、自分で interrupt() を呼び出します:
import { session } from './agent';
session.interrupt();// This still triggers `audio_interrupted` so your UI can stop playbackWebRTC と WebSocket はどちらも進行中の応答を停止しますが、低レベルの仕組みはトランスポートによって異なります。WebRTC はバッファ済みの出力音声を自動でクリアします。WebSocket 構成では、引き続きローカル再生を自分で停止する必要があり、対応する切り詰めイベントと会話イベントがトランスポートから戻るとローカル履歴が更新されます。
テキスト入力
Section titled “テキスト入力”ライブ会話に入力テキストや追加の構造化されたユーザーコンテンツを送信したい場合は、sendMessage() を使用します。
import { RealtimeSession, RealtimeAgent } from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'Assistant',});
const session = new RealtimeSession(agent, { model: 'gpt-realtime-2.1',});
session.sendMessage('Hello, how are you?');これは、テキストと音声が混在する UI、アウトオブバンドのコンテキスト注入、または音声入力に明示的なテキスト補足を組み合わせる場合に便利です。
Realtime の音声対音声セッションでは画像も含めることができます。SDK では、addImage() を使用して現在の会話に画像を添付します。
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'Assistant',});
const session = new RealtimeSession(agent, { model: 'gpt-realtime-2.1',});
const imageDataUrl = 'data:image/png;base64,...';
session.addImage(imageDataUrl, { triggerResponse: false });session.sendMessage('Describe what is in this image.');triggerResponse: false を渡すと、モデルに応答を求める前に、後続のテキストまたは音声ターンと画像をまとめることができます。これは公式の Realtime conversations の画像入力ガイダンス と一致します。
手動応答制御
Section titled “手動応答制御”上位の SDK レイヤーでは、sendMessage() と addImage() はデフォルトで応答をトリガーします。手動応答制御が重要になるのは、元のトランスポートイベント、プッシュトゥトークフロー、またはカスタムのモデレーション/検証ステップを扱う場合です。
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'Greeter', instructions: 'Greet the user with cheer and answer questions.',});
const session = new RealtimeSession(agent, { model: 'gpt-realtime-2.1',});
session.transport.on('*', (event) => { // Event received from the underlying Realtime transport});
// Send any valid client event, for example, to trigger a new responsesession.transport.sendEvent({ type: 'response.create', // ...});一般的なケースは 2 つあります:
audio.input.turnDetection = nullで VAD を完全に無効にした場合、音声ターンをコミットしてからresponse.createを送信する責任があります。- VAD を有効のままにしつつ、
turnDetection.interruptResponse = falseとturnDetection.createResponse = falseを設定した場合、API は引き続きターンを検出しますが、応答作成はあなたに委ねます。
2 つ目のパターンは、モデルが応答する前にユーザー入力を確認またはモデレーションしたい場合に便利です。これは公式の 自動応答の無効化に関する Realtime conversations ガイダンス と一致します。
エージェント機能
Section titled “エージェント機能”通常のエージェントと同様に、ハンドオフを使用してエージェントを複数のエージェントに分割し、それらの間をオーケストレーションすることで、パフォーマンスを改善し、問題のスコープをより適切に限定できます。
import { RealtimeAgent } from '@openai/agents/realtime';
const mathTutorAgent = new RealtimeAgent({ name: 'Math Tutor', handoffDescription: 'Specialist agent for math questions', instructions: 'You provide help with math problems. Explain your reasoning at each step and include examples',});
const agent = new RealtimeAgent({ name: 'Greeter', instructions: 'Greet the user with cheer and answer questions.', handoffs: [mathTutorAgent],});通常のエージェントとは異なり、リアルタイムエージェントではハンドオフの挙動が少し異なります。ハンドオフが実行されると、進行中のセッションが新しいエージェント設定に置き換わる形で更新されます。このため、新しいエージェントは進行中の会話履歴に自動的にアクセスでき、入力フィルターは現在適用されません。
セッションはライブのままなので、そのセッションのモデルはハンドオフ中に変更されません。音声変更は基礎となる Realtime API のルールに従います。セッションが音声出力を生成する前にのみ機能します。Realtime ハンドオフは主に、同じセッション上で RealtimeAgent 設定を切り替えるためのものです。別のモデル、たとえば gpt-5.4 のような推論モデルを使用する必要がある場合や、非リアルタイムのバックエンドエージェントに委任する必要がある場合は、ツールによる委任 を使用してください。
通常のエージェントと同様に、リアルタイムエージェントはツールを呼び出してアクションを実行できます。Realtime は 関数ツール (ローカルで実行)と リモート MCP サーバーツール (Realtime API によってリモートで実行)をサポートします。通常のエージェントで使うものと同じ tool() ヘルパーを使って、関数ツールを定義できます。
import { tool, RealtimeAgent } from '@openai/agents/realtime';import { z } from 'zod';
const getWeather = tool({ name: 'get_weather', description: 'Return the weather for a city.', parameters: z.object({ city: z.string() }), async execute({ city }) { return `The weather in ${city} is sunny.`; },});
const weatherAgent = new RealtimeAgent({ name: 'Weather assistant', instructions: 'Answer weather questions.', tools: [getWeather],});関数ツールは RealtimeSession と同じ環境で実行されます。つまり、セッションをブラウザーで実行している場合、ツールはブラウザーで実行されます。機密性の高いアクションを実行する必要がある場合は、ツール内からバックエンドを呼び出し、特権的な処理はサーバーに実行させてください。
これにより、ブラウザー側ツールをサーバー側ロジックへの薄いバックチャネルとして機能させることができます。たとえば、examples/realtime-next は、ブラウザー内で refundBackchannel ツールを定義し、リクエストと現在の会話履歴をサーバー上の handleRefundRequest(...) に転送します。そこでは別の Runner が異なるエージェントまたはモデルを使用して返金を評価し、その結果を音声セッションに返すことができます。
リモート MCP サーバーツール
Section titled “リモート MCP サーバーツール”リモート MCP サーバーツールは hostedMcpTool で設定でき、リモートで実行されます。MCP ツールの利用可能状況が変わると、セッションは mcp_tools_changed を発行します。MCP ツール呼び出しの完了後にセッションがモデル応答を自動トリガーしないようにするには、automaticallyTriggerResponseForMcpToolCalls: false を設定します。
現在のフィルター済み MCP ツールリストは session.availableMcpTools としても利用できます。このプロパティと mcp_tools_changed イベントはどちらも、エージェント設定の allowed_tools フィルターを適用した後の、アクティブなエージェントで有効になっているリモート MCP サーバーのみを反映します。
リモート MCP サーバーツールのセットアップは、セキュアなサーバー選択、ヘッダー、承認を接続前設定として扱うと最も理解しやすくなります。RealtimeSession.connect() がトランスポートを開く前に、SDK はアクティブなエージェントのリモート MCP サーバーツール定義を解決し、Realtime API に送信する初期セッション設定にサポートされている MCP フィールドを含めます。
このタイミングは、ブラウザー WebRTC アプリで特に重要です。一時的なクライアントシークレットは常にサーバーで発行されるため、秘密に保つ必要のあるリモート MCP 認証情報やカスタム headers は、初期 session ペイロードの一部として、サーバー側の POST /v1/realtime/client_secrets リクエストに添付する必要があります。長期有効な認証情報をブラウザーコードに置いたり、connect() 開始後に後から追加する前提にしたりしないでください。
Realtime API レベルでは、その後の session.update 呼び出しでもツールやその他の変更可能なセッションフィールドを変更できます。また SDK 自体も、アクティブなエージェントが変わると session.update を送信します。ただしブラウザーアプリでは、セキュアなリモート MCP サーバーツールの初期化をサーバー側の接続前事項として扱い、ブラウザー側の RealtimeSession 設定を、サーバーが発行した内容と整合させておく必要があります。
バックグラウンド結果
Section titled “バックグラウンド結果”ツールの実行中、エージェントはユーザーからの新しいリクエストを処理できません。体験を改善する 1 つの方法は、ツールを実行しようとしていることをエージェントに告知させる、またはツールを実行する時間を稼ぐために特定のフレーズを言わせることです。
関数ツールが別のモデル応答をすぐにトリガーせずに終了すべき場合は、@openai/agents/realtime から backgroundResult(output) を返します。これにより、ツール出力をセッションに返しつつ、応答トリガーは自分で制御できます。
タイムアウト
Section titled “タイムアウト”関数ツールのタイムアウトオプション(timeoutMs、timeoutBehavior、timeoutErrorFunction)は Realtime セッションでも同じように機能します。デフォルトの error_as_result では、タイムアウトメッセージがツール出力として送信されます。raise_exception では、セッションは ToolTimeoutError を含む error イベントを発行し、その呼び出しのツール出力は送信しません。
会話履歴へのアクセス
Section titled “会話履歴へのアクセス”エージェントが特定のツールを呼び出した際の引数に加えて、Realtime セッションが追跡している現在の会話履歴のスナップショットにもアクセスできます。これは、会話の現在の状態に基づいてより複雑なアクションを実行する必要がある場合や、委任のためのツール を使用する予定がある場合に便利です。
import { tool, RealtimeContextData, RealtimeItem,} from '@openai/agents/realtime';import { z } from 'zod';
const parameters = z.object({ request: z.string(),});
const refundTool = tool<typeof parameters, RealtimeContextData>({ name: 'Refund Expert', description: 'Evaluate a refund', parameters, execute: async ({ request }, details) => { // The history might not be available const history: RealtimeItem[] = details?.context?.history ?? []; // Call your backend to process the refund request },});ツール実行前の承認
Section titled “ツール実行前の承認”ツールを needsApproval: true で定義すると、エージェントはツール実行前に tool_approval_requested イベントを発行します。
このイベントをリッスンすることで、ツール呼び出しを承認または拒否するための UI をユーザーに表示できます。
リクエストは await session.approve(request.approvalItem) または await session.reject(request.approvalItem) で解決します。関数ツールでは、{ alwaysApprove: true } または { alwaysReject: true } を渡して、セッションの残りの間に繰り返される呼び出しに同じ判断を再利用できます。また、その特定の呼び出しについてモデルにカスタム拒否メッセージを返すには、session.reject(request.approvalItem, { message: '...' }) を使用できます。リモート MCP サーバーツールの承認では、固定の承認/拒否はサポートされません。代わりに、リモート MCP の allowedTools 設定でそれらのツールを制限してください。
呼び出しごとの拒否 message を渡さない場合、セッションは(設定されていれば)toolErrorFormatter にフォールバックし、その後 SDK デフォルトの拒否テキストにフォールバックします。
デフォルトでは、関数ツール入力ガードレールは承認後、ツール実行直前に実行されます。new RealtimeSession(...) に toolExecution: { preApprovalInputGuardrails: true } を渡すと、ローカル関数ツール入力ガードレールは、セッションが tool_approval_requested を発行する前にも実行されます。ガードレールによる拒否は、拒否メッセージをツール出力として返し、承認イベントをスキップします。ガードレールが呼び出しを許可した場合でも承認イベントは発行され、session.approve(...) の後、実行前にガードレールが再度実行されます。
import { session } from './agent';
session.on('tool_approval_requested', (_context, _agent, request) => { // Show a UI to let the user approve or reject the tool call // Then resolve the request with `session.approve(...)` or `session.reject(...)`
session.approve(request.approvalItem);});ガードレール
Section titled “ガードレール”ガードレールは、エージェントの発言が一連のルールに違反したかどうかを監視し、応答を即座に打ち切る方法を提供します。これらのチェックは、エージェント応答のトランスクリプトストリームに対して実行されます。音声セッションでは、SDK は出力音声トランスクリプトとトランスクリプト差分を使用するため、重要な前提条件は別個のテキスト出力モダリティではなく、トランスクリプトが利用可能であることです。
提供したガードレールはモデル応答が返されるときに非同期で実行され、たとえば「特定の禁止語に言及した」など、事前定義された分類トリガーに基づいて応答を打ち切ることができます。
ガードレールに抵触すると、セッションは guardrail_tripped イベントを発行します。このイベントは、ガードレールをトリガーした itemId を含む details オブジェクトも提供します。
import { RealtimeOutputGuardrail, RealtimeAgent, RealtimeSession,} from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'Greeter', instructions: 'Greet the user with cheer and answer questions.',});
const guardrails: RealtimeOutputGuardrail[] = [ { name: 'No mention of Dom', async execute({ agentOutput }) { const domInOutput = agentOutput.includes('Dom'); return { tripwireTriggered: domInOutput, outputInfo: { domInOutput }, }; }, },];
const guardedSession = new RealtimeSession(agent, { outputGuardrails: guardrails,});デフォルトでは、ガードレールは 100 文字ごと、および最終トランスクリプトが利用可能になった時点でもう一度実行されます。テキストの発話には通常、トランスクリプトの生成より時間がかかるため、多くの場合、ユーザーがそれを聞く前にガードレールが安全でない出力を打ち切れます。
この挙動を変更したい場合は、outputGuardrailSettings オブジェクトをセッションに渡せます。
完全に生成されたトランスクリプトを応答の最後に 1 回だけ評価したい場合は、debounceTextLength: -1 を設定します。
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'Greeter', instructions: 'Greet the user with cheer and answer questions.',});
const guardedSession = new RealtimeSession(agent, { outputGuardrails: [ /*...*/ ], outputGuardrailSettings: { debounceTextLength: 500, // run guardrail every 500 characters or set it to -1 to run it only at the end },});会話状態と委任
Section titled “会話状態と委任”会話履歴管理
Section titled “会話履歴管理”RealtimeSession は、ユーザーメッセージ、アシスタント出力、ツール呼び出し、切り詰め状態を追跡するローカルの history スナップショットを自動的に維持します。UI にレンダリングしたり、ツール内で検査したり、項目を修正または削除する必要があるときに更新したりできます。
会話が変化すると、セッションは history_updated を発行します。履歴変更をリクエストする必要がある場合は、updateHistory() を使用します。これは現在の履歴との差分を計算して必要な削除/作成イベントを送信するようトランスポートに要求します。対応する会話イベントが戻ってくると、ローカルの session.history ビューが更新されます。
import { RealtimeSession, RealtimeAgent } from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'Assistant',});
const session = new RealtimeSession(agent, { model: 'gpt-realtime-2.1',});
await session.connect({ apiKey: '<client-api-key>' });
// listening to the history_updated eventsession.on('history_updated', (history) => { // returns the full history of the session console.log(history);});
// Option 1: explicit settingsession.updateHistory([ /* specific history */]);
// Option 2: override based on current state like removing all agent messagessession.updateHistory((currentHistory) => { return currentHistory.filter( (item) => !(item.type === 'message' && item.role === 'assistant'), );});- 現時点では、後から関数ツール呼び出しを編集することはできません。
- 履歴内のアシスタントテキストは、
output_audio.transcriptを含む利用可能なトランスクリプトに依存します。 - 割り込みによって切り詰められた応答は、最終トランスクリプトを保持しません。
- 入力音声の文字起こしは、モデルが音声をどのように解釈したかの正確なコピーではなく、ユーザーが言った内容の大まかな手がかりとして扱うのが最適です。
ツールによる委任
Section titled “ツールによる委任”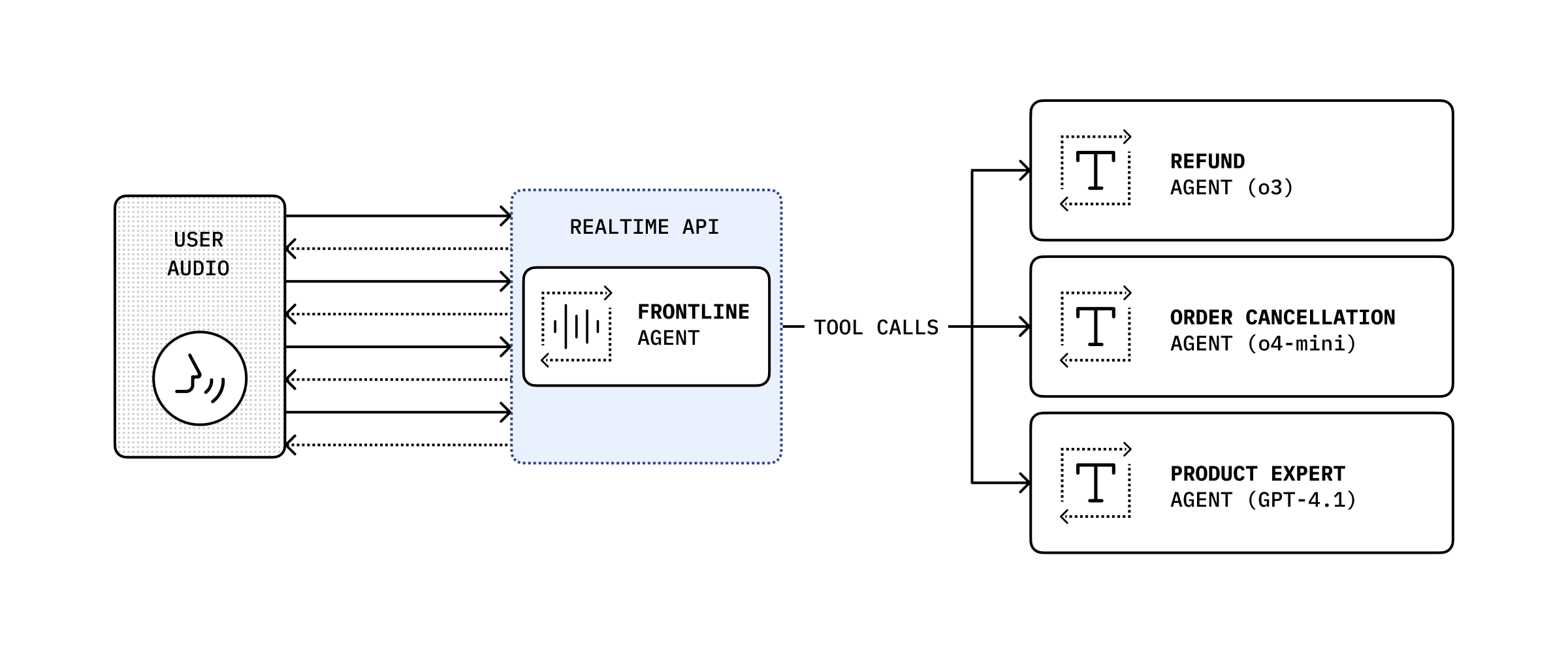
会話履歴とツール呼び出しを組み合わせることで、より複雑なアクションを実行するために会話を別のバックエンドエージェントへ委任し、その結果をユーザーに返すことができます。
import { RealtimeAgent, RealtimeContextData, tool,} from '@openai/agents/realtime';import { handleRefundRequest } from './serverAgent';import z from 'zod';
const refundSupervisorParameters = z.object({ request: z.string(),});
const refundSupervisor = tool< typeof refundSupervisorParameters, RealtimeContextData>({ name: 'escalateToRefundSupervisor', description: 'Escalate a refund request to the refund supervisor', parameters: refundSupervisorParameters, execute: async ({ request }, details) => { // This will execute on the server return handleRefundRequest(request, details?.context?.history ?? []); },});
const agent = new RealtimeAgent({ name: 'Customer Support', instructions: 'You are a customer support agent. If you receive any requests for refunds, you need to delegate to your supervisor.', tools: [refundSupervisor],});以下のコードはサーバーで実行されます。この例では Next.js Server Action 経由です。
// This runs on the serverimport 'server-only';
import { Agent, run } from '@openai/agents';import type { RealtimeItem } from '@openai/agents/realtime';import z from 'zod';
const agent = new Agent({ name: 'Refund Expert', instructions: 'You are a refund expert. You are given a request to process a refund and you need to determine if the request is valid.', model: 'gpt-5.4', outputType: z.object({ reason: z.string(), refundApproved: z.boolean(), }),});
export async function handleRefundRequest( request: string, history: RealtimeItem[],) { const input = `The user has requested a refund.
The request is: ${request}
Current conversation history:${JSON.stringify(history, null, 2)}`.trim();
const result = await run(agent, input);
return JSON.stringify(result.finalOutput, null, 2);}