This is the full developer documentation for OpenAI Agents SDK (TypeScript)
# OpenAI Agents SDK TypeScript
> The OpenAI Agents SDK for TypeScript enables you to build agentic AI apps in a lightweight, easy-to-use package with very few abstractions.
## OpenAI Agents SDK
Build sandbox, text, and voice agents with a small set of primitives.
[Let’s build](/openai-agents-js/llms-full.txt/guides/sandbox-agents)
* Sandbox Agent
```typescript
import { run } from '@openai/agents';
import { gitRepo, SandboxAgent } from '@openai/agents/sandbox';
import { UnixLocalSandboxClient } from '@openai/agents/sandbox/local';
const agent = new SandboxAgent({
name: 'Workspace Assistant',
model: 'gpt-5.5',
instructions: 'Inspect the repo before changing files.',
defaultManifest: {
entries: { repo: gitRepo({ repo: 'openai/openai-agents-js' }) },
},
});
const result = await run(
agent,
'Inspect the repo README and summarize what this project does.',
{ sandbox: { client: new UnixLocalSandboxClient() } },
);
console.log(result.finalOutput);
```
* Text Agent
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Assistant',
instructions: 'You are a helpful assistant.',
});
const result = await run(
agent,
'Write a haiku about recursion in programming.',
);
console.log(result.finalOutput);
```
* Voice Agent
```typescript
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Assistant',
instructions: 'You are a helpful assistant.',
});
// Automatically connects your microphone and audio output in the browser via WebRTC.
const session = new RealtimeSession(agent);
await session.connect({
apiKey: '',
});
```
## Overview
[Section titled “Overview”](#overview)
The [OpenAI Agents SDK for TypeScript](https://github.com/openai/openai-agents-js) enables you to build agentic AI apps in a lightweight, easy-to-use package with very few abstractions. It’s a production-ready upgrade of our previous experimentation for agents, [Swarm](https://github.com/openai/swarm/tree/main), that’s also [available in Python](https://github.com/openai/openai-agents-python). The Agents SDK has a very small set of primitives:
* **Agents**, which are LLMs equipped with instructions and tools
* **Sandbox agents**, which pair agents with isolated filesystem workspaces, shell commands, file editing, snapshots, and sandbox session state
* **Agents as tools / Handoffs**, which allow agents to delegate to other agents for specific tasks
* **Guardrails**, which enable the inputs to agents to be validated
In combination with TypeScript, these primitives are powerful enough to express complex relationships between tools and agents, give agents a real workspace when they need one, and allow you to build real-world applications without a steep learning curve. In addition, the SDK comes with built-in **tracing** that lets you visualize and debug your agentic flows, as well as evaluate them and even fine-tune models for your application.
## Why use the Agents SDK
[Section titled “Why use the Agents SDK”](#why-use-the-agents-sdk)
The SDK has two driving design principles:
1. Enough features to be worth using, but few enough primitives to make it quick to learn.
2. Works great out of the box, but you can customize exactly what happens.
Here are the main features of the SDK:
* **Agent loop**: A built-in agent loop that handles tool invocation, sends results back to the LLM, and continues until the task is complete.
* **Sandbox execution**: Run agents with isolated filesystem workspaces, shell commands, file editing, snapshots, and sandbox session state when the work needs a workspace.
* **TypeScript-first**: Orchestrate and chain agents using native TypeScript language features, without needing to learn new abstractions.
* **Agents as tools / Handoffs**: A powerful mechanism for coordinating and delegating work across multiple agents.
* **Guardrails**: Run input validation and safety checks in parallel with agent execution, and fail fast when checks do not pass.
* **Function tools**: Turn any TypeScript function into a tool with automatic schema generation and Zod-powered validation.
* **MCP server tool calling**: Built-in MCP server tool integration that works the same way as function tools.
* **Sessions**: A persistent memory layer for maintaining working context within an agent loop.
* **Human in the loop**: Built-in mechanisms for involving humans across agent runs.
* **Tracing**: Built-in tracing for visualizing, debugging, and monitoring workflows, with support for the OpenAI suite of evaluation, fine-tuning, and distillation tools.
* **Realtime Agents**: Build powerful voice agents with features such as automatic interruption detection, context management, guardrails, and more.
## Installation
[Section titled “Installation”](#installation)
```bash
npm install @openai/agents zod
```
The SDK requires Zod v4; installing `zod` via npm will fetch the latest v4 release.
## Choose your starting point
[Section titled “Choose your starting point”](#choose-your-starting-point)
Most first-time users only need one of these entry points:
| Start with | Use it when | Notes |
| -------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `@openai/agents` | You are building most text, sandbox, or voice applications. | Recommended default. It includes the OpenAI provider setup, sandbox agent APIs under `@openai/agents/sandbox`, and voice APIs under `@openai/agents/realtime`. |
| `@openai/agents-realtime` | You only need the standalone Realtime package. | Useful for browser-only voice apps or when you want a narrower package boundary. |
| Lower-level packages (`@openai/agents-core`, `@openai/agents-openai`, `@openai/agents-extensions`) | You need lower-level composition, custom provider wiring, or specific integrations. | Most new users can ignore these until they have a concrete need. |
## Hello world examples
[Section titled “Hello world examples”](#hello-world-examples)
Start with a sandbox agent when the agent should work in a filesystem. You can still use a regular `Agent` when your workflow does not need a sandbox workspace or sandbox lifecycle.
* Sandbox Agent
Hello World with a sandbox
```typescript
import { run } from '@openai/agents';
import { gitRepo, SandboxAgent } from '@openai/agents/sandbox';
import { UnixLocalSandboxClient } from '@openai/agents/sandbox/local';
const agent = new SandboxAgent({
name: 'Workspace Assistant',
model: 'gpt-5.5',
instructions: 'Inspect the repo before changing files.',
defaultManifest: {
entries: { repo: gitRepo({ repo: 'openai/openai-agents-js' }) },
},
});
const result = await run(
agent,
'Inspect the repo README and summarize what this project does.',
{ sandbox: { client: new UnixLocalSandboxClient() } },
);
console.log(result.finalOutput);
```
* Without Sandbox
Hello World without a sandbox
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Assistant',
instructions: 'You are a helpful assistant',
});
const result = await run(
agent,
'Write a haiku about recursion in programming.',
);
console.log(result.finalOutput);
// Code within the code,
// Functions calling themselves,
// Infinite loop's dance.
```
(*If running this, ensure you set the `OPENAI_API_KEY` environment variable*)
```bash
export OPENAI_API_KEY=sk-...
```
## Start here
[Section titled “Start here”](#start-here)
Pick one path first, get it working end to end, then come back for the deeper guides.
[Quickstart ](/openai-agents-js/guides/quickstart)Build your first text-based agent and learn the core SDK workflow.
[Voice Agents Quickstart ](/openai-agents-js/guides/voice-agents/quickstart)Start with the Realtime voice path when you are building spoken interactions.
[Sandbox agents ](/openai-agents-js/guides/sandbox-agents)Start a sandbox agent when the agent needs files, shell commands, patches, or resumable sandbox state.
## Choose your path
[Section titled “Choose your path”](#choose-your-path)
Use this table when you know the job you want to do, but not which page explains it.
| Goal | Start here |
| --------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------- |
| Build the first text agent and see one complete run | [Quickstart](/openai-agents-js/guides/quickstart) |
| Add function tools, hosted tools, or agents as tools | [Tools](/openai-agents-js/guides/tools) |
| Give an agent an isolated filesystem and shell workspace | [Sandbox agents](/openai-agents-js/guides/sandbox-agents) |
| Decide between handoffs and manager-style orchestration | [Agent orchestration](/openai-agents-js/guides/multi-agent) |
| Keep memory across turns | [Running agents](/openai-agents-js/guides/running-agents) and [Sessions](/openai-agents-js/guides/sessions) |
| Use OpenAI models, websocket transport, or non-OpenAI providers | [Models](/openai-agents-js/guides/models) |
| Review outputs, run items, interruptions, and resume state | [Results](/openai-agents-js/guides/results) |
| Build a low-latency voice agent | [Voice Agents Quickstart](/openai-agents-js/guides/voice-agents/quickstart) |
# AI SDK Integration
> Connect your Agents SDK agents to any model through Vercel's AI SDK
Out of the box the Agents SDK works with OpenAI models through the Responses API or Chat Completions API. However, if you would like to use another model, the [Vercel AI SDK](https://sdk.vercel.ai/) offers a range of supported models that can be brought into the Agents SDK through this adapter.
## Setup
[Section titled “Setup”](#setup)
1. Install the AI SDK adapter by installing the extensions package:
```bash
npm install @openai/agents-extensions
```
2. Choose your desired model package from the [Vercel’s AI SDK](https://ai-sdk.dev/docs/foundations/providers-and-models) and install it:
```bash
npm install @ai-sdk/openai
```
3. Import the adapter and model to connect to your agent:
Import the adapter
```typescript
import { openai } from '@ai-sdk/openai';
import { aisdk } from '@openai/agents-extensions/ai-sdk';
```
4. Initialize an instance of the model to be used by the agent:
Create the model
```typescript
import { openai } from '@ai-sdk/openai';
import { aisdk } from '@openai/agents-extensions/ai-sdk';
const model = aisdk(openai('gpt-5.4'));
```
## Code examples
[Section titled “Code examples”](#code-examples)
AI SDK Setup
```typescript
import { Agent, run } from '@openai/agents';
// Import the model package you installed
import { openai } from '@ai-sdk/openai';
// Import the adapter
import { aisdk } from '@openai/agents-extensions/ai-sdk';
// Create a model instance to be used by the agent
const model = aisdk(openai('gpt-5.4'));
// Create an agent with the model
const agent = new Agent({
name: 'My Agent',
instructions: 'You are a helpful assistant.',
model,
});
// Run the agent with the new model
run(agent, 'What is the capital of Germany?');
```
## Passing provider metadata
[Section titled “Passing provider metadata”](#passing-provider-metadata)
If you need to send provider-specific options with a message, pass them through `providerMetadata`. The values are forwarded directly to the underlying AI SDK model. For example, the following `providerData` in the Agents SDK
Agents SDK providerData
```typescript
const providerData = {
anthropic: {
cacheControl: {
type: 'ephemeral',
},
},
};
```
would become
AI SDK providerMetadata
```typescript
const providerMetadata = {
anthropic: {
cacheControl: {
type: 'ephemeral',
},
},
};
```
when using the AI SDK integration.
## Normalizing finalized output text
[Section titled “Normalizing finalized output text”](#normalizing-finalized-output-text)
Some providers return structured output as plain text with extra wrapping, such as JSON code fences. If you need provider-specific cleanup before the Agents runtime validates the final output, pass `transformOutputText` when creating the adapter:
Normalize finalized output text
````typescript
import { openai } from '@ai-sdk/openai';
import { aisdk } from '@openai/agents-extensions/ai-sdk';
const model = aisdk(openai('gpt-5.4'), {
transformOutputText(text) {
return text.match(/```(?:json)?\s*([\s\S]*?)\s*```/)?.[1]?.trim() ?? text;
},
});
````
`transformOutputText` runs on finalized assistant text for non-streamed responses and on the final `response_done` event for streamed responses. It does not modify incremental `output_text_delta` events.
## Retries
[Section titled “Retries”](#retries)
`modelSettings.retry` works with AI SDK-backed models too, because retries are implemented by the Agents runtime rather than only by the default OpenAI provider.
That means you can attach the same retry configuration you would use elsewhere:
* Set `modelSettings.retry` on the `Agent`, `Runner`, or both.
* Compose `retryPolicies` such as `networkError()`, `httpStatus([...])`, or `providerSuggested()`.
* Keep in mind that `providerSuggested()` only helps when the wrapped AI SDK model can surface retry advice through the adapter.
For a complete example using `aisdk(openai(...))`, see [`examples/ai-sdk/retry.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/ai-sdk/retry.ts). For the retry API itself, including safety boundaries for streaming and stateful follow-up requests, see the [Models guide](/openai-agents-js/guides/models#model-retries).
## Picking the right integration
[Section titled “Picking the right integration”](#picking-the-right-integration)
There are two related integrations in `@openai/agents-extensions`:
* `@openai/agents-extensions/ai-sdk` adapts an AI SDK model so an `Agent` can run on it.
* `@openai/agents-extensions/ai-sdk-ui` adapts a streamed Agents SDK run so AI SDK UI routes can return a standard streaming `Response`.
### Notes for AI SDK models
[Section titled “Notes for AI SDK models”](#notes-for-ai-sdk-models)
* The `@openai/agents-extensions/ai-sdk` adapter is still in beta, so it is worth testing carefully with your chosen provider, especially smaller ones.
* If you are using OpenAI models, prefer the default OpenAI model provider instead of this adapter.
* Supported AI SDK providers must expose `specificationVersion` `v2` or `v3`. If you need the older v1 provider style, copy the module from [examples/ai-sdk-v1](https://github.com/openai/openai-agents-js/tree/main/examples/ai-sdk-v1) into your project.
* Computer tools require display metadata when used through this adapter. Make sure the tool includes both `environment` and `dimensions` metadata.
* Deferred Responses tool-loading flows are not supported here. That includes `toolNamespace()`, function tools with `deferLoading: true`, and `toolSearchTool()`. If you need tool search, use an OpenAI Responses model directly. See the [Tools guide](/openai-agents-js/guides/tools#deferred-tool-loading-with-tool-search) and [Models guide](/openai-agents-js/guides/models#responses-only-deferred-tool-loading).
## AI SDK UI stream helpers
[Section titled “AI SDK UI stream helpers”](#ai-sdk-ui-stream-helpers)
`@openai/agents-extensions/ai-sdk-ui` provides response helpers for wiring Agents SDK streams into AI SDK UI routes:
* `createAiSdkTextStreamResponse(source, options?)` for plain text streaming responses.
* `createAiSdkUiMessageStream(source)` for a lower-level `ReadableStream`.
* `createAiSdkUiMessageStreamResponse(source, options?)` for `UIMessageChunk` streaming responses.
These helpers accept a `StreamedRunResult`, stream-like source, or compatible wrapper object. The response helpers return a `Response` with streaming-friendly headers.
Use `createAiSdkUiMessageStreamResponse(...)` when your route should return the AI SDK response directly. Use `createAiSdkUiMessageStream(...)` when you want to own the response or rendering layer while still using the maintained Agents SDK to AI SDK `UIMessageChunk` translation. Use `createAiSdkTextStreamResponse(...)` when you only want plain text.
The response helpers also accept optional response settings through `options`:
* `headers`: additional response headers to merge into the streaming response.
* `status`: the HTTP status code for the returned `Response`.
* `statusText`: the HTTP status text for the returned `Response`.
Example lower-level UI message stream:
UI message stream
```typescript
import { Agent, run } from '@openai/agents';
import { createAiSdkUiMessageStream } from '@openai/agents-extensions/ai-sdk-ui';
const agent = new Agent({
name: 'Assistant',
instructions: 'Reply with a short answer.',
});
export async function createStream() {
const stream = await run(agent, 'Hello there.', { stream: true });
return createAiSdkUiMessageStream(stream);
}
```
Example Next.js route for UI message streaming:
UI message stream response
```typescript
import { Agent, run } from '@openai/agents';
import { createAiSdkUiMessageStreamResponse } from '@openai/agents-extensions/ai-sdk-ui';
const agent = new Agent({
name: 'Assistant',
instructions: 'Reply with a short answer.',
});
export async function POST() {
const stream = await run(agent, 'Hello there.', { stream: true });
return createAiSdkUiMessageStreamResponse(stream);
}
```
Example Next.js route for text-only streaming:
Text stream response
```typescript
import { Agent, run } from '@openai/agents';
import { createAiSdkTextStreamResponse } from '@openai/agents-extensions/ai-sdk-ui';
const agent = new Agent({
name: 'Assistant',
instructions: 'Reply with a short answer.',
});
export async function POST() {
const stream = await run(agent, 'Hello there.', { stream: true });
return createAiSdkTextStreamResponse(stream);
}
```
For end-to-end usage, see the `examples/ai-sdk-ui` app in this repository.
# Realtime Agents on Cloudflare
> Connect your Agents SDK agents from Cloudflare Workers/workerd using a dedicated transport.
Cloudflare Workers and other workerd runtimes cannot open outbound WebSockets using the global `WebSocket` constructor. To simplify connecting Realtime Agents from these environments, the extensions package provides a dedicated transport that performs the `fetch()`-based upgrade internally.
Caution
This adapter is still in beta. You may run into edge case issues or bugs. Please report any issues via [GitHub issues](https://github.com/openai/openai-agents-js/issues) and we’ll fix quickly. For Node.js-style APIs in Workers, consider enabling `nodejs_compat`.
## Setup
[Section titled “Setup”](#setup)
1. **Install the extensions package.**
```bash
npm install @openai/agents-extensions
```
2. **Create a transport and attach it to your session.**
```typescript
import { CloudflareRealtimeTransportLayer } from '@openai/agents-extensions';
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'My Agent',
});
// Create a transport that connects to OpenAI Realtime via Cloudflare/workerd's fetch-based upgrade.
const cfTransport = new CloudflareRealtimeTransportLayer({
url: 'wss://api.openai.com/v1/realtime?model=gpt-realtime-2',
});
const session = new RealtimeSession(agent, {
// Set your own transport.
transport: cfTransport,
});
```
3. **Connect your `RealtimeSession`.**
```typescript
await session.connect({ apiKey: 'your-openai-ephemeral-or-server-key' });
```
## Notes
[Section titled “Notes”](#notes)
* The Cloudflare transport uses `fetch()` with `Upgrade: websocket` under the hood and skips waiting for a socket `open` event, matching the workerd APIs.
* All `RealtimeSession` features (tools, guardrails, etc.) work as usual when using this transport.
* Use `DEBUG=openai-agents*` to inspect detailed logs during development.
# Realtime Agents on Twilio
> Run Agents SDK voice agents over Twilio phone calls
Twilio offers a [Media Streams API](https://www.twilio.com/docs/voice/media-streams) that sends the raw audio from a phone call to a WebSocket server. This setup can be used to connect your [voice agents](/openai-agents-js/guides/voice-agents) to Twilio. You can use the default Realtime Session transport in `websocket` mode to connect the events coming from Twilio to your Realtime Session. However, this requires you to set the right audio format and adjust your own interruption timing as phone calls will naturally introduce more latency than a web-based conversation.
To improve the setup experience, we’ve created a dedicated transport layer that handles the connection to Twilio, including interruption handling and audio forwarding.
Caution
This adapter is still in beta. You may run into edge case issues or bugs. Please report any issues via [GitHub issues](https://github.com/openai/openai-agents-js/issues) and we’ll fix quickly.
## Setup
[Section titled “Setup”](#setup)
1. **Make sure you have a Twilio account and a Twilio phone number.**
2. **Set up a WebSocket server that can receive events from Twilio.**
If you are developing locally, you will need to configure a local tunnel like [`ngrok`](https://ngrok.io/) or [Cloudflare Tunnel](https://developers.cloudflare.com/pages/how-to/preview-with-cloudflare-tunnel/) to make your local server accessible to Twilio. You can use the `TwilioRealtimeTransportLayer` to connect to Twilio.
3. **Install the Twilio adapter by installing the extensions package:**
```bash
npm install @openai/agents-extensions
```
4. **Import the adapter and model to connect to your `RealtimeSession`:**
```typescript
import { TwilioRealtimeTransportLayer } from '@openai/agents-extensions';
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'My Agent',
});
// Create a new transport mechanism that will bridge the connection between Twilio and
// the OpenAI Realtime API.
const twilioTransport = new TwilioRealtimeTransportLayer({
twilioWebSocket: websocketConnection,
});
const session = new RealtimeSession(agent, {
// set your own transport
transport: twilioTransport,
});
```
5. **Connect your `RealtimeSession` to Twilio:**
```typescript
session.connect({ apiKey: 'your-openai-api-key' });
```
Any event and behavior that you would expect from a `RealtimeSession` will work as expected including tool calls, guardrails, and more. Read the [voice agents guide](/openai-agents-js/guides/voice-agents) for more information on how to use the `RealtimeSession` with voice agents.
## Tips and considerations
[Section titled “Tips and considerations”](#tips-and-considerations)
1. **Speed is the name of the game.**
In order to receive all the necessary events and audio from Twilio, you should create your `TwilioRealtimeTransportLayer` instance as soon as you have a reference to the WebSocket connection and immediately call `session.connect()` afterwards.
2. **Access the raw Twilio events.**
If you want to access the raw events that are being sent by Twilio, you can listen to the `transport_event` event on your `RealtimeSession` instance. Every event from Twilio will have a type of `twilio_message` and a `message` property that contains the raw event data.
3. **Watch debug logs.**
Sometimes you may run into issues where you want more information on what’s going on. Using a `DEBUG=openai-agents*` environment variable will show all the debug logs from the Agents SDK. Alternatively, you can enable just debug logs for the Twilio adapter using `DEBUG=openai-agents:extensions:twilio*`.
## Full example server
[Section titled “Full example server”](#full-example-server)
Below is an example of a full end-to-end example of a WebSocket server that receives requests from Twilio and forwards them to a `RealtimeSession`.
Example server using Fastify
```typescript
import Fastify from 'fastify';
import type { FastifyInstance, FastifyReply, FastifyRequest } from 'fastify';
import dotenv from 'dotenv';
import fastifyFormBody from '@fastify/formbody';
import fastifyWs from '@fastify/websocket';
import {
RealtimeAgent,
RealtimeSession,
backgroundResult,
tool,
} from '@openai/agents/realtime';
import { TwilioRealtimeTransportLayer } from '@openai/agents-extensions';
import { hostedMcpTool } from '@openai/agents';
import { z } from 'zod';
import process from 'node:process';
// Load environment variables from .env file
dotenv.config();
// Retrieve the OpenAI API key from environment variables. You must have OpenAI Realtime API access.
const { OPENAI_API_KEY } = process.env;
if (!OPENAI_API_KEY) {
console.error('Missing OpenAI API key. Please set it in the .env file.');
process.exit(1);
}
const PORT = +(process.env.PORT || 5050);
// Initialize Fastify
const fastify = Fastify();
fastify.register(fastifyFormBody);
fastify.register(fastifyWs);
const weatherTool = tool({
name: 'weather',
description: 'Get the weather in a given location.',
parameters: z.object({
location: z.string(),
}),
execute: async ({ location }: { location: string }) => {
return backgroundResult(`The weather in ${location} is sunny.`);
},
});
const secretTool = tool({
name: 'secret',
description: 'A secret tool to tell the special number.',
parameters: z.object({
question: z
.string()
.describe(
'The question to ask the secret tool; mainly about the special number.',
),
}),
execute: async ({ question }: { question: string }) => {
return `The answer to ${question} is 42.`;
},
needsApproval: true,
});
const agent = new RealtimeAgent({
name: 'Greeter',
instructions:
'You are a friendly assistant. When you use a tool always first say what you are about to do.',
tools: [
hostedMcpTool({
serverLabel: 'deepwiki',
serverUrl: 'https://mcp.deepwiki.com/mcp',
}),
secretTool,
weatherTool,
],
});
// Root Route
fastify.get('/', async (_request: FastifyRequest, reply: FastifyReply) => {
reply.send({ message: 'Twilio Media Stream Server is running!' });
});
// Route for Twilio to handle incoming and outgoing calls
// punctuation to improve text-to-speech translation
fastify.all(
'/incoming-call',
async (request: FastifyRequest, reply: FastifyReply) => {
const twimlResponse = `
O.K. you can start talking!
`.trim();
reply.type('text/xml').send(twimlResponse);
},
);
// WebSocket route for media-stream
fastify.register(async (scopedFastify: FastifyInstance) => {
scopedFastify.get(
'/media-stream',
{ websocket: true },
async (connection: any) => {
const twilioTransportLayer = new TwilioRealtimeTransportLayer({
twilioWebSocket: connection,
});
const session = new RealtimeSession(agent, {
transport: twilioTransportLayer,
model: 'gpt-realtime-2',
config: {
audio: {
output: {
voice: 'verse',
},
},
},
});
session.on('mcp_tools_changed', (tools: { name: string }[]) => {
const toolNames = tools.map((tool) => tool.name).join(', ');
console.log(`Available MCP tools: ${toolNames || 'None'}`);
});
session.on(
'tool_approval_requested',
(_context: unknown, _agent: unknown, approvalRequest: any) => {
console.log(
`Approving tool call for ${approvalRequest.approvalItem.rawItem.name}.`,
);
session
.approve(approvalRequest.approvalItem)
.catch((error: unknown) =>
console.error('Failed to approve tool call.', error),
);
},
);
session.on(
'mcp_tool_call_completed',
(_context: unknown, _agent: unknown, toolCall: unknown) => {
console.log('MCP tool call completed.', toolCall);
},
);
await session.connect({
apiKey: OPENAI_API_KEY,
});
console.log('Connected to the OpenAI Realtime API');
},
);
});
fastify.listen({ port: PORT }, (err: Error | null) => {
if (err) {
console.error(err);
process.exit(1);
}
console.log(`Server is listening on port ${PORT}`);
});
process.on('SIGINT', () => {
fastify.close();
process.exit(0);
});
```
# Agents
> Learn more about how to define agents in the OpenAI Agents SDK for JavaScript / TypeScript
Agents are the main building‑block of the OpenAI Agents SDK. An **Agent** is a Large Language Model (LLM) that has been configured with:
* **Instructions** – the system prompt that tells the model *who it is* and *how it should respond*.
* **Model** – which OpenAI model to call, plus any optional model tuning parameters.
* **Tools** – a list of functions or APIs the LLM can invoke to accomplish a task.
Basic Agent definition
```typescript
import { Agent } from '@openai/agents';
const agent = new Agent({
name: 'Haiku Agent',
instructions: 'Always respond in haiku form.',
model: 'gpt-5.4', // optional – falls back to the default model
});
```
> Use this page when you want to define or customize a single `Agent`. If you are deciding how several agents should collaborate, read [Agent orchestration](/openai-agents-js/guides/multi-agent).
### Choose the next guide
[Section titled “Choose the next guide”](#choose-the-next-guide)
Use this page as the hub for agent definition. Jump out to the adjacent guide that matches the next decision you need to make.
| If you want to… | Read next |
| ----------------------------------------------- | ------------------------------------------------------------------ |
| Choose a model or configure stored prompts | [Models](/openai-agents-js/guides/models) |
| Add capabilities to the agent | [Tools](/openai-agents-js/guides/tools) |
| Give the agent an isolated filesystem workspace | [Sandbox agents](/openai-agents-js/guides/sandbox-agents/concepts) |
| Decide between managers and handoffs | [Agent orchestration](/openai-agents-js/guides/multi-agent) |
| Configure handoff behavior | [Handoffs](/openai-agents-js/guides/handoffs) |
| Run turns, stream events, or manage state | [Running agents](/openai-agents-js/guides/running-agents) |
| Inspect final output, run items, or resume | [Results](/openai-agents-js/guides/results) |
The rest of this page walks through every Agent feature in more detail.
***
## Agent fundamentals
[Section titled “Agent fundamentals”](#agent-fundamentals)
### Basic configuration
[Section titled “Basic configuration”](#basic-configuration)
The `Agent` constructor takes a single configuration object. The most commonly‑used properties are shown below.
| Property | Required | Description |
| --------------------------------- | -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `name` | yes | A short human‑readable identifier. |
| `instructions` | yes | System prompt (string **or** function – see [Dynamic instructions](#dynamic-instructions)). |
| `prompt` | no | OpenAI Responses API prompt configuration. Accepts a static prompt object or a function. See [Prompt](/openai-agents-js/guides/models#prompt). |
| `handoffDescription` | no | Short description used when this agent is offered as a handoff tool. |
| `handoffs` | no | Delegate the conversation to specialist agents. See [Composition patterns](#composition-patterns) and the [Handoffs guide](/openai-agents-js/guides/handoffs). |
| `model` | no | Model name **or** a custom [`Model`](/openai-agents-js/openai/agents/interfaces/model/) implementation. |
| `modelSettings` | no | Tuning parameters (temperature, top\_p, etc.). See [Models](/openai-agents-js/guides/models#modelsettings). If the properties you need aren’t at the top level, you can include them under `providerData`. |
| `tools` | no | Array of [`Tool`](/openai-agents-js/openai/agents/type-aliases/tool/) instances the model can call. See [Tools](/openai-agents-js/guides/tools). |
| `mcpServers` | no | MCP-backed tools for the agent. See the [MCP guide](/openai-agents-js/guides/mcp). |
| `mcpConfig` | no | Options for local MCP tools, such as strict schemas, error handling, and server-prefixed tool names. See [Agent-level MCP configuration](/openai-agents-js/guides/mcp#agent-level-mcp-configuration). |
| `inputGuardrails` | no | Guardrails applied to the first user input for this agent chain. See [Guardrails](/openai-agents-js/guides/guardrails). |
| `outputGuardrails` | no | Guardrails applied to the final output for this agent. See [Guardrails](/openai-agents-js/guides/guardrails). |
| `outputType` | no | Return structured output instead of plain text. See [Output types](#output-types) and [Results](/openai-agents-js/guides/results#final-output). |
| `toolUseBehavior` | no | Control whether function-tool results loop back to the model or finish the run. See [Forcing tool use](#forcing-tool-use). |
| `resetToolChoice` | no | Reset `toolChoice` to the default after a tool call (default: `true`) to prevent tool-use loops. See [Forcing tool use](#forcing-tool-use). |
| `handoffOutputTypeWarningEnabled` | no | Emit a warning when handoff output types differ (default: `true`). See [Results](/openai-agents-js/guides/results#final-output). |
Agent with tools
```typescript
import { Agent, tool } from '@openai/agents';
import { z } from 'zod';
const getWeather = tool({
name: 'get_weather',
description: 'Return the weather for a given city.',
parameters: z.object({ city: z.string() }),
async execute({ city }) {
return `The weather in ${city} is sunny.`;
},
});
const agent = new Agent({
name: 'Weather bot',
instructions: 'You are a helpful weather bot.',
model: 'gpt-4.1',
tools: [getWeather],
});
```
***
### Context
[Section titled “Context”](#context)
Agents are **generic on their context type** – i.e. `Agent`. The *context* is a dependency‑injection object that you create and pass to `Runner.run()`. It is forwarded to every tool, guardrail, handoff, etc. and is useful for storing state or providing shared services (database connections, user metadata, feature flags, …).
Agent with context
```typescript
import { Agent } from '@openai/agents';
interface Purchase {
id: string;
uid: string;
deliveryStatus: string;
}
interface UserContext {
uid: string;
isProUser: boolean;
// this function can be used within tools
fetchPurchases(): Promise;
}
const agent = new Agent({
name: 'Personal shopper',
instructions: 'Recommend products the user will love.',
});
// Later
import { run } from '@openai/agents';
const result = await run(agent, 'Find me a new pair of running shoes', {
context: { uid: 'abc', isProUser: true, fetchPurchases: async () => [] },
});
```
***
### Output types
[Section titled “Output types”](#output-types)
By default, an Agent returns **plain text** (`string`). If you want the model to return a structured object you can specify the `outputType` property. The SDK accepts:
1. A [Zod](https://github.com/colinhacks/zod) schema (`z.object({...})`).
2. Any JSON‑schema‑compatible object.
Structured output with Zod
```typescript
import { Agent } from '@openai/agents';
import { z } from 'zod';
const CalendarEvent = z.object({
name: z.string(),
date: z.string(),
participants: z.array(z.string()),
});
const extractor = new Agent({
name: 'Calendar extractor',
instructions: 'Extract calendar events from the supplied text.',
outputType: CalendarEvent,
});
```
When `outputType` is provided, the SDK automatically uses [structured outputs](https://developers.openai.com/api/docs/guides/structured-outputs) instead of plain text.
***
### OpenAI platform mapping
[Section titled “OpenAI platform mapping”](#openai-platform-mapping)
Some agent concepts map directly to OpenAI platform concepts, while others are configured when you run the agent rather than when you define it.
| SDK concept | OpenAI guide | When it matters |
| --------------------------------------- | -------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------ |
| `outputType` | [Structured Outputs](https://developers.openai.com/api/docs/guides/structured-outputs) | The agent should return typed JSON or a Zod-validated object instead of text. |
| `tools` / hosted tools | [Tools guide](https://developers.openai.com/api/docs/guides/tools) | The model should search, retrieve, execute code, or call your functions/tools. |
| `conversationId` / `previousResponseId` | [Conversation state](https://developers.openai.com/api/docs/guides/conversation-state) | You want OpenAI to persist or chain conversation state between turns. |
`conversationId` and `previousResponseId` are run-time controls, not `Agent` constructor fields. Use [Running agents](/openai-agents-js/guides/running-agents) when you need those SDK entry points.
***
## Composition patterns
[Section titled “Composition patterns”](#composition-patterns)
Two SDK entry points show up most often when an agent participates in a larger workflow:
1. **Manager (agents as tools)** – a central agent owns the conversation and invokes specialized agents that are exposed as tools.
2. **Handoffs** – the initial agent delegates the entire conversation to a specialist once it has identified the user’s request.
These approaches are complementary. Managers give you a single place to enforce guardrails or rate limits, while handoffs let each agent focus on a single task without retaining control of the conversation. For the design tradeoffs and when to choose each pattern, see [Agent orchestration](/openai-agents-js/guides/multi-agent).
#### Manager (agents as tools)
[Section titled “Manager (agents as tools)”](#manager-agents-as-tools)
In this pattern the manager never hands over control—the LLM uses the tools and the manager summarizes the final answer. Read more in the [tools guide](/openai-agents-js/guides/tools#agents-as-tools).
Agents as tools
```typescript
import { Agent } from '@openai/agents';
const bookingAgent = new Agent({
name: 'Booking expert',
instructions: 'Answer booking questions and modify reservations.',
});
const refundAgent = new Agent({
name: 'Refund expert',
instructions: 'Help customers process refunds and credits.',
});
const customerFacingAgent = new Agent({
name: 'Customer-facing agent',
instructions:
'Talk to the user directly. When they need booking or refund help, call the matching tool.',
tools: [
bookingAgent.asTool({
toolName: 'booking_expert',
toolDescription: 'Handles booking questions and requests.',
}),
refundAgent.asTool({
toolName: 'refund_expert',
toolDescription: 'Handles refund questions and requests.',
}),
],
});
```
#### Handoffs
[Section titled “Handoffs”](#handoffs)
With handoffs the triage agent routes requests, but once a handoff occurs the specialist agent owns the conversation until it produces a final output. This keeps prompts short and lets you reason about each agent independently. Learn more in the [handoffs guide](/openai-agents-js/guides/handoffs).
Agent with handoffs
```typescript
import { Agent } from '@openai/agents';
const bookingAgent = new Agent({
name: 'Booking Agent',
instructions: 'Help users with booking requests.',
});
const refundAgent = new Agent({
name: 'Refund Agent',
instructions: 'Process refund requests politely and efficiently.',
});
// Use Agent.create method to ensure the finalOutput type considers handoffs
const triageAgent = Agent.create({
name: 'Triage Agent',
instructions: `Help the user with their questions.
If the user asks about booking, hand off to the booking agent.
If the user asks about refunds, hand off to the refund agent.`.trimStart(),
handoffs: [bookingAgent, refundAgent],
});
```
If your handoff targets can return different output types, prefer `Agent.create(...)` over `new Agent(...)`. That lets TypeScript infer the union of possible `finalOutput` shapes across the handoff graph and avoids the runtime warning controlled by `handoffOutputTypeWarningEnabled`. See the [results guide](/openai-agents-js/guides/results#final-output) for an end-to-end example.
***
## Advanced configuration and runtime controls
[Section titled “Advanced configuration and runtime controls”](#advanced-configuration-and-runtime-controls)
### Dynamic instructions
[Section titled “Dynamic instructions”](#dynamic-instructions)
`instructions` can be a **function** instead of a string. The function receives the current `RunContext` and the Agent instance and can return a string *or* a `Promise`.
Agent with dynamic instructions
```typescript
import { Agent, RunContext } from '@openai/agents';
interface UserContext {
name: string;
}
function buildInstructions(runContext: RunContext) {
return `The user's name is ${runContext.context.name}. Be extra friendly!`;
}
const agent = new Agent({
name: 'Personalized helper',
instructions: buildInstructions,
});
```
Both synchronous and `async` functions are supported.
***
### Dynamic prompts
[Section titled “Dynamic prompts”](#dynamic-prompts)
`prompt` supports the same callback shape as `instructions`, but returns a prompt configuration object instead of a string. This is useful when the prompt ID, version, or variables depend on the current run context.
Agent with dynamic prompt
```typescript
import { Agent, RunContext } from '@openai/agents';
interface PromptContext {
customerTier: 'free' | 'pro';
}
function buildPrompt(runContext: RunContext) {
return {
promptId: 'pmpt_support_agent',
version: '7',
variables: {
customer_tier: runContext.context.customerTier,
},
};
}
const agent = new Agent({
name: 'Prompt-backed helper',
prompt: buildPrompt,
});
```
This is only supported when you use the OpenAI Responses API. Both synchronous and `async` functions are supported.
***
### Lifecycle hooks
[Section titled “Lifecycle hooks”](#lifecycle-hooks)
For advanced use‑cases you can observe the Agent lifecycle by listening on events.
`Agent` instances emit lifecycle events for that specific agent instance, while `Runner` emits the same event names as a single stream across the whole run. This is useful for multi-agent workflows where you want one place to observe handoffs and tool calls.
The shared event names are:
| Event | Agent hook arguments | Runner hook arguments |
| ------------------ | --------------------------------------- | ---------------------------------------------- |
| `agent_start` | `(context, agent, turnInput?)` | `(context, agent, turnInput?)` |
| `agent_end` | `(context, output)` | `(context, agent, output)` |
| `agent_handoff` | `(context, nextAgent)` | `(context, fromAgent, toAgent)` |
| `agent_tool_start` | `(context, tool, { toolCall })` | `(context, agent, tool, { toolCall })` |
| `agent_tool_end` | `(context, tool, result, { toolCall })` | `(context, agent, tool, result, { toolCall })` |
Agent with lifecycle hooks
```typescript
import { Agent } from '@openai/agents';
const agent = new Agent({
name: 'Verbose agent',
instructions: 'Explain things thoroughly.',
});
agent.on('agent_start', (ctx, agent) => {
console.log(`[${agent.name}] started`);
});
agent.on('agent_end', (ctx, output) => {
console.log(`[agent] produced:`, output);
});
```
***
### Guardrails
[Section titled “Guardrails”](#guardrails)
Guardrails allow you to validate or transform user input and agent output. They are configured via the `inputGuardrails` and `outputGuardrails` arrays. See the [guardrails guide](/openai-agents-js/guides/guardrails) for details.
***
### Cloning / copying agents
[Section titled “Cloning / copying agents”](#cloning--copying-agents)
Need a slightly modified version of an existing agent? Use the `clone()` method, which returns an entirely new `Agent` instance.
Cloning Agents
```typescript
import { Agent } from '@openai/agents';
const pirateAgent = new Agent({
name: 'Pirate',
instructions: 'Respond like a pirate – lots of “Arrr!”',
model: 'gpt-5.4',
});
const robotAgent = pirateAgent.clone({
name: 'Robot',
instructions: 'Respond like a robot – be precise and factual.',
});
```
***
### Forcing tool use
[Section titled “Forcing tool use”](#forcing-tool-use)
Supplying tools doesn’t guarantee the LLM will call one. You can **force** tool use with `modelSettings.toolChoice`:
1. `'auto'` (default) – the LLM decides whether to use a tool.
2. `'required'` – the LLM *must* call a tool (it can choose which one).
3. `'none'` – the LLM must **not** call a tool.
4. A specific tool name, e.g. `'calculator'` – the LLM must call that particular tool.
When the available tool is `computerTool()` on OpenAI Responses, `toolChoice: 'computer'` is special: it forces the GA built-in computer tool instead of treating `'computer'` as a plain function name. The SDK also accepts preview-compatible computer selectors for older integrations, but new code should prefer `'computer'`. If no computer tool is available, the string behaves like any other function tool name.
Forcing tool use
```typescript
import { Agent, tool } from '@openai/agents';
import { z } from 'zod';
const calculatorTool = tool({
name: 'Calculator',
description: 'Use this tool to answer questions about math problems.',
parameters: z.object({ question: z.string() }),
execute: async (input) => {
throw new Error('TODO: implement this');
},
});
const agent = new Agent({
name: 'Strict tool user',
instructions: 'Always answer using the calculator tool.',
tools: [calculatorTool],
modelSettings: { toolChoice: 'required' },
});
```
When you use deferred Responses tools such as `toolNamespace()`, function tools with `deferLoading: true`, or hosted MCP tools with `deferLoading: true`, keep `modelSettings.toolChoice` on `'auto'`. The SDK rejects forcing a deferred tool or the built-in `tool_search` helper by name because the model needs to decide when to load those definitions. See the [Tools guide](/openai-agents-js/guides/tools#deferred-tool-loading-with-tool-search) for the full tool-search setup.
#### Preventing infinite loops
[Section titled “Preventing infinite loops”](#preventing-infinite-loops)
After a tool call the SDK automatically resets `toolChoice` back to `'auto'`. This prevents the model from entering an infinite loop where it repeatedly tries to call the tool. You can override this behavior via the `resetToolChoice` flag or by configuring `toolUseBehavior`:
* `'run_llm_again'` (default) – run the LLM again with the tool result.
* `'stop_on_first_tool'` – treat the first tool result as the final answer.
* `{ stopAtToolNames: ['my_tool'] }` – stop when any of the listed tools is called.
* `(context, toolResults) => ...` – custom function returning whether the run should finish.
```typescript
const agent = new Agent({
...,
toolUseBehavior: 'stop_on_first_tool',
});
```
Note: `toolUseBehavior` only applies to **function tools**. Hosted tools always return to the model for processing.
***
## Related guides
[Section titled “Related guides”](#related-guides)
* [Models](/openai-agents-js/guides/models) for model selection, stored prompts, and provider configuration.
* [Tools](/openai-agents-js/guides/tools) for function tools, hosted tools, MCP, and `agent.asTool()`.
* [Agent orchestration](/openai-agents-js/guides/multi-agent) for choosing between managers, handoffs, and code-driven orchestration.
* [Handoffs](/openai-agents-js/guides/handoffs) for configuring specialist delegation.
* [Running agents](/openai-agents-js/guides/running-agents) for executing turns, streaming, and conversation state.
* [Results](/openai-agents-js/guides/results) for `finalOutput`, run items, and resume state.
* Explore the full TypeDoc reference under **@openai/agents** in the sidebar.
# Configuration
> Configure process-wide OpenAI client, transport, tracing, and logging defaults
This page covers **SDK-wide defaults** that you usually set once during app startup, such as the default OpenAI client, transport, tracing export key, and debug logging behavior. These settings apply process-wide by default, so this is the right place for universal configuration rather than per-agent or per-run tuning.
If you need to configure a specific `Agent`, `Runner`, or `run()` call instead, see:
* [Running Agents](/openai-agents-js/guides/running-agents) for `Runner` and per-run options.
* [Models](/openai-agents-js/guides/models) for agent-level and runner-level model settings.
* [Tracing](/openai-agents-js/guides/tracing) for run-specific tracing configuration and exporter behavior.
## OpenAI client and transport
[Section titled “OpenAI client and transport”](#openai-client-and-transport)
### API keys and clients
[Section titled “API keys and clients”](#api-keys-and-clients)
By default the SDK resolves `OPENAI_API_KEY` lazily when it needs to create an OpenAI client. If setting the environment variable is not possible, call `setDefaultOpenAIKey()` manually.
Set default OpenAI key
```typescript
import { setDefaultOpenAIKey } from '@openai/agents';
setDefaultOpenAIKey(process.env.OPENAI_API_KEY!); // sk-...
```
You may also pass your own `OpenAI` client instance. The SDK will otherwise create one automatically using the default key.
Set default OpenAI client
```typescript
import { OpenAI } from 'openai';
import { setDefaultOpenAIClient } from '@openai/agents';
const customClient = new OpenAI({ baseURL: '...', apiKey: '...' });
setDefaultOpenAIClient(customClient);
```
### API selection
[Section titled “API selection”](#api-selection)
Finally you can switch between the Responses API and the Chat Completions API.
Set OpenAI API
```typescript
import { setOpenAIAPI } from '@openai/agents';
setOpenAIAPI('chat_completions');
```
### Responses transport
[Section titled “Responses transport”](#responses-transport)
If you are using the Responses API, you can also choose the OpenAI provider transport. The default is HTTP.
Set Responses transport
```typescript
import { setOpenAIAPI, setOpenAIResponsesTransport } from '@openai/agents';
setOpenAIAPI('responses');
setOpenAIResponsesTransport('websocket');
```
Use `setOpenAIResponsesTransport('websocket')` to enable the WebSocket transport and `setOpenAIResponsesTransport('http')` to switch back. If you route websocket traffic through a proxy or gateway, set `OPENAI_WEBSOCKET_BASE_URL` (or configure `websocketBaseURL` on your `OpenAIProvider`).
This process-wide default only affects models that are later resolved through the default OpenAI provider. If you pass a concrete `Model` instance or a custom `modelProvider`, configure the transport there instead. See the [Models guide](/openai-agents-js/guides/models#responses-websocket-transport).
## Observability and debugging
[Section titled “Observability and debugging”](#observability-and-debugging)
### Tracing
[Section titled “Tracing”](#tracing)
Tracing is enabled by default in supported server runtimes. It is disabled by default in browsers and when `NODE_ENV=test`.
By default trace export uses the same OpenAI key from the section above.
A separate key may be set via `setTracingExportApiKey()`:
Set tracing export API key
```typescript
import { setTracingExportApiKey } from '@openai/agents';
setTracingExportApiKey('sk-...');
```
Tracing can also be disabled entirely:
Disable tracing
```typescript
import { setTracingDisabled } from '@openai/agents';
setTracingDisabled(true);
```
If you’d like to learn more about the tracing feature, please check out [Tracing guide](/openai-agents-js/guides/tracing).
### Debug logging
[Section titled “Debug logging”](#debug-logging)
The SDK uses the [`debug`](https://www.npmjs.com/package/debug) package for debug logging. Set the `DEBUG` environment variable to `openai-agents*` to see verbose logs.
```bash
export DEBUG=openai-agents*
```
To log session persistence activity, set `OPENAI_AGENTS__DEBUG_SAVE_SESSION=1`.
You can obtain a namespaced logger for your own modules using `getLogger(namespace)` from `@openai/agents`.
Get logger
```typescript
import { getLogger } from '@openai/agents';
const logger = getLogger('my-app');
logger.debug('something happened');
```
#### Sensitive data in logs
[Section titled “Sensitive data in logs”](#sensitive-data-in-logs)
Certain logs may contain user data. Disable them by setting these environment variables.
To disable logging LLM inputs and outputs:
```bash
export OPENAI_AGENTS_DONT_LOG_MODEL_DATA=1
```
To disable logging tool inputs and outputs:
```bash
export OPENAI_AGENTS_DONT_LOG_TOOL_DATA=1
```
# Context Management
> Learn how to provide local data via RunContext and expose context to the LLM
Context is an overloaded term. There are two main classes of context you might care about:
1. **Local context** that your code can access during a run: dependencies or data needed by tools, callbacks like `onHandoff`, and lifecycle hooks.
2. **Agent/LLM context** that the language model can see when generating a response.
## Local context
[Section titled “Local context”](#local-context)
Local context is represented by the `RunContext` type. You create any object to hold your state or dependencies and pass it to `Runner.run()`. All tool calls and hooks receive a `RunContext` wrapper so they can read from or modify that object.
Local context example
```typescript
import { Agent, run, RunContext, tool } from '@openai/agents';
import { z } from 'zod';
interface UserInfo {
name: string;
uid: number;
}
const fetchUserAge = tool({
name: 'fetch_user_age',
description: 'Return the age of the current user',
parameters: z.object({}),
execute: async (
_args,
runContext?: RunContext,
): Promise => {
return `User ${runContext?.context.name} is 47 years old`;
},
});
async function main() {
const userInfo: UserInfo = { name: 'John', uid: 123 };
const agent = new Agent({
name: 'Assistant',
tools: [fetchUserAge],
});
const result = await run(agent, 'What is the age of the user?', {
context: userInfo,
});
console.log(result.finalOutput);
// The user John is 47 years old.
}
main().catch((error) => {
console.error(error);
process.exit(1);
});
```
Every agent, tool and hook participating in a single run must use the same **type** of context.
Use local context for things like:
* Data about the run (user name, IDs, etc.)
* Dependencies such as loggers or data fetchers
* Helper functions
Note
The context object is **not** sent to the LLM. It is purely local and you can read from or write to it freely.
Within a single run, derived contexts share the same underlying app context, approvals, and usage tracking. Nested `agent.asTool()` runs may attach a different `toolInput`, but they do not get an isolated copy of your app state by default.
### What `RunContext` exposes
[Section titled “What RunContext exposes”](#what-runcontext-exposes)
`RunContext` is a wrapper around your app-defined context object. In practice you will most often use:
* `runContext.context` for your own mutable app state and dependencies.
* `runContext.usage` for the aggregated token/request usage of the current run.
* `runContext.toolInput` for structured input when the current run is executing inside `agent.asTool()`.
* `runContext.approveTool(...)` / `runContext.rejectTool(...)` when you need to update approval state programmatically.
Only `runContext.context` is your app-defined object. The other fields are runtime metadata managed by the SDK.
If you later serialize a [`RunState`](/openai-agents-js/guides/results#state) for [human-in-the-loop](/openai-agents-js/guides/human-in-the-loop), that runtime metadata is saved with the state. Avoid putting secrets in `runContext.context` if you intend to persist or transmit serialized state.
Note
`RunContext` is about local app state for the current run. Conversation state is a separate concern: use `result.history`, `session`, `conversationId`, or `previousResponseId` depending on how you want to carry turns forward. See [Running agents](/openai-agents-js/guides/running-agents#state-and-conversation-management) for that decision.
If you subclass `RunContext`, verify that nested or derived runs still preserve any subclass-specific instance state you rely on. The SDK creates forked contexts internally during nested runs.
## Agent/LLM context
[Section titled “Agent/LLM context”](#agentllm-context)
When the LLM is called, the only data it can see comes from the conversation history. To make additional information available you have a few options:
1. Add it to the Agent `instructions` – also known as a system or developer message. This can be a static string or a function that receives the context and returns a string.
2. Include it in the `input` when calling `Runner.run()`. This is similar to the instructions technique but lets you place the message lower in the [chain of command](https://cdn.openai.com/spec/model-spec-2024-05-08.html#follow-the-chain-of-command).
3. Expose it via function tools so the LLM can fetch data on demand.
4. Use retrieval or web search tools to ground responses in relevant data from files, databases, or the web.
# Guardrails
> Validate or transform agent input and output
Guardrails can run alongside your agents or block execution until they complete, allowing you to perform checks and validations on user input or agent output. For example, you may run a lightweight model as a guardrail before invoking an expensive model. If the guardrail detects malicious usage, it can trigger an error and stop the costly model from running.
There are two kinds of guardrails:
1. **Input guardrails** run on the initial user input.
2. **Output guardrails** run on the final agent output.
## Workflow boundaries
[Section titled “Workflow boundaries”](#workflow-boundaries)
Guardrails are attached to agents, but they do not necessarily run on every agent in a workflow:
* **Input guardrails** run only for the first agent in the chain.
* **Output guardrails** run only for the agent that produces the final output.
* **Tool guardrails** run on every function-tool invocation, with input guardrails before execution and output guardrails after execution.
If you need checks around each custom function-tool call in a workflow that includes managers or handoffs, use **tool guardrails** instead of agent-level input/output guardrails.
## Input guardrails
[Section titled “Input guardrails”](#input-guardrails)
Input guardrails run in three steps:
1. The guardrail receives the same input passed to the agent.
2. The guardrail function executes and returns a [`GuardrailFunctionOutput`](/openai-agents-js/openai/agents/interfaces/guardrailfunctionoutput) wrapped inside an [`InputGuardrailResult`](/openai-agents-js/openai/agents/interfaces/inputguardrailresult).
3. If `tripwireTriggered` is `true`, an [`InputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents/classes/inputguardrailtripwiretriggered) error is thrown.
> **Note** Input guardrails are intended for user input, so they only run if the agent is the *first* agent in the workflow. Guardrails are configured on the agent itself because different agents often require different guardrails.
### Execution modes
[Section titled “Execution modes”](#execution-modes)
* `runInParallel: true` (default) starts guardrails alongside the LLM/tool calls. This minimizes latency but the model may already have consumed tokens or run tools if the guardrail later triggers.
* `runInParallel: false` runs the guardrail **before** calling the model, preventing token spend and tool execution when the guardrail blocks the request. Use this when you prefer safety and cost over latency.
## Output guardrails
[Section titled “Output guardrails”](#output-guardrails)
Output guardrails run in 3 steps:
1. The guardrail receives the output produced by the agent.
2. The guardrail function executes and returns a [`GuardrailFunctionOutput`](/openai-agents-js/openai/agents/interfaces/guardrailfunctionoutput) wrapped inside an [`OutputGuardrailResult`](/openai-agents-js/openai/agents/interfaces/outputguardrailresult).
3. If `tripwireTriggered` is `true`, an [`OutputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents/classes/outputguardrailtripwiretriggered) error is thrown.
> **Note** Output guardrails only run if the agent is the *last* agent in the workflow. For realtime voice interactions see [the voice agents guide](/openai-agents-js/guides/voice-agents/build#guardrails).
Output guardrail functions also receive an optional `details` object with the underlying `modelResponse` and the generated output items for the turn. Use this when the final output alone is not enough to decide whether the response should pass, for example when you want to inspect the full generated item list or provider response metadata before tripping the guardrail.
## Tool guardrails
[Section titled “Tool guardrails”](#tool-guardrails)
Tool guardrails wrap **function tools** and let you validate or block tool calls before and after execution. They are configured on the tool itself (via `tool()` options) and run for every invocation of that tool.
In practice, this means custom function tools where you set `inputGuardrails` and/or `outputGuardrails` on `tool({...})`.
* **Input tool guardrails** run before the tool executes and can reject the call with a message or throw a tripwire.
* **Output tool guardrails** run after the tool executes and can replace the output with a rejection message or throw a tripwire.
Tool guardrails return a `behavior`:
* `allow` — continue to the next guardrail or tool execution.
* `rejectContent` — short‑circuit with a message (tool call is skipped or output is replaced).
* `throwException` — throw a tripwire error immediately.
Tool guardrails apply to function tools you define with `tool()`. Handoffs are presented to the model as function-like tools, but they run through the SDK’s handoff path rather than the normal function-tool pipeline, so tool guardrails do not apply to the handoff call itself. Hosted tools and built-in execution tools (`computerTool`, `shellTool`, `applyPatchTool`) also do not use this guardrail pipeline, and `agent.asTool()` does not currently expose tool-guardrail options directly.
## Tripwires
[Section titled “Tripwires”](#tripwires)
When a guardrail fails, it signals this via a tripwire. As soon as a tripwire is triggered, the runner throws the corresponding error and halts execution.
## Implementing a guardrail
[Section titled “Implementing a guardrail”](#implementing-a-guardrail)
A guardrail is simply a function that returns a `GuardrailFunctionOutput`. Below is a minimal example that checks whether the user is asking for math homework help by running another agent under the hood.
Input guardrail example
```typescript
import {
Agent,
run,
InputGuardrailTripwireTriggered,
InputGuardrail,
} from '@openai/agents';
import { z } from 'zod';
const guardrailAgent = new Agent({
name: 'Guardrail check',
instructions: 'Check if the user is asking you to do their math homework.',
outputType: z.object({
isMathHomework: z.boolean(),
reasoning: z.string(),
}),
});
const mathGuardrail: InputGuardrail = {
name: 'Math Homework Guardrail',
// Set runInParallel to false to block the model until the guardrail completes.
runInParallel: false,
execute: async ({ input, context }) => {
const result = await run(guardrailAgent, input, { context });
return {
outputInfo: result.finalOutput,
tripwireTriggered: result.finalOutput?.isMathHomework === false,
};
},
};
const agent = new Agent({
name: 'Customer support agent',
instructions:
'You are a customer support agent. You help customers with their questions.',
inputGuardrails: [mathGuardrail],
});
async function main() {
try {
await run(agent, 'Hello, can you help me solve for x: 2x + 3 = 11?');
console.log("Guardrail didn't trip - this is unexpected");
} catch (e) {
if (e instanceof InputGuardrailTripwireTriggered) {
console.log('Math homework guardrail tripped');
}
}
}
main().catch(console.error);
```
Output guardrails work the same way.
Output guardrail example
```typescript
import {
Agent,
run,
OutputGuardrailTripwireTriggered,
OutputGuardrail,
} from '@openai/agents';
import { z } from 'zod';
// The output by the main agent
const MessageOutput = z.object({ response: z.string() });
type MessageOutput = z.infer;
// The output by the math guardrail agent
const MathOutput = z.object({ reasoning: z.string(), isMath: z.boolean() });
// The guardrail agent
const guardrailAgent = new Agent({
name: 'Guardrail check',
instructions: 'Check if the output includes any math.',
outputType: MathOutput,
});
// An output guardrail using an agent internally
const mathGuardrail: OutputGuardrail = {
name: 'Math Guardrail',
async execute({ agentOutput, context }) {
const result = await run(guardrailAgent, agentOutput.response, {
context,
});
return {
outputInfo: result.finalOutput,
tripwireTriggered: result.finalOutput?.isMath ?? false,
};
},
};
const agent = new Agent({
name: 'Support agent',
instructions:
'You are a user support agent. You help users with their questions.',
outputGuardrails: [mathGuardrail],
outputType: MessageOutput,
});
async function main() {
try {
const input = 'Hello, can you help me solve for x: 2x + 3 = 11?';
await run(agent, input);
console.log("Guardrail didn't trip - this is unexpected");
} catch (e) {
if (e instanceof OutputGuardrailTripwireTriggered) {
console.log('Math output guardrail tripped');
}
}
}
main().catch(console.error);
```
Tool input/output guardrails look like this:
Tool guardrails
```typescript
import {
Agent,
ToolGuardrailFunctionOutputFactory,
defineToolInputGuardrail,
defineToolOutputGuardrail,
tool,
} from '@openai/agents';
import { z } from 'zod';
const blockSecrets = defineToolInputGuardrail({
name: 'block_secrets',
run: async ({ toolCall }) => {
const args = JSON.parse(toolCall.arguments) as { text?: string };
if (args.text?.includes('sk-')) {
return ToolGuardrailFunctionOutputFactory.rejectContent(
'Remove secrets before calling this tool.',
);
}
return ToolGuardrailFunctionOutputFactory.allow();
},
});
const redactOutput = defineToolOutputGuardrail({
name: 'redact_output',
run: async ({ output }) => {
const text = String(output ?? '');
if (text.includes('sk-')) {
return ToolGuardrailFunctionOutputFactory.rejectContent(
'Output contained sensitive data.',
);
}
return ToolGuardrailFunctionOutputFactory.allow();
},
});
const classifyTool = tool({
name: 'classify_text',
description: 'Classify text for internal routing.',
parameters: z.object({
text: z.string(),
}),
inputGuardrails: [blockSecrets],
outputGuardrails: [redactOutput],
execute: ({ text }) => `length:${text.length}`,
});
const agent = new Agent({
name: 'Classifier',
instructions: 'Classify incoming text.',
tools: [classifyTool],
});
```
1. `guardrailAgent` is used inside the guardrail functions.
2. The guardrail function receives the agent input or output and returns the result.
3. Extra information can be included in the guardrail result.
4. `agent` defines the actual workflow where guardrails are applied.
# Handoffs
> Delegate tasks from one agent to another
Handoffs let an agent delegate part of a conversation to another agent. This is useful when different agents specialise in specific areas. In a customer support app for example, you might have agents that handle bookings, refunds or FAQs.
Handoffs are represented as tools to the LLM. If you hand off to an agent called `Refund Agent`, the tool name would be `transfer_to_refund_agent`.
> Read this page after [Agents](/openai-agents-js/guides/agents#composition-patterns) once you know the specialist should take over the conversation. If the specialist should stay behind the original agent, use [agents as tools](/openai-agents-js/guides/tools#4-agents-as-tools) instead.
## Creating a handoff
[Section titled “Creating a handoff”](#creating-a-handoff)
Every agent accepts a `handoffs` option. It can contain other `Agent` instances or `Handoff` objects returned by the `handoff()` helper.
If you pass plain `Agent` instances, their `handoffDescription` (if provided) is appended to the default tool description. Use it to clarify when the model should pick that handoff.
### Basic usage
[Section titled “Basic usage”](#basic-usage)
Basic handoffs
```typescript
import { Agent, handoff } from '@openai/agents';
const billingAgent = new Agent({ name: 'Billing agent' });
const refundAgent = new Agent({ name: 'Refund agent' });
// Use Agent.create method to ensure the finalOutput type considers handoffs
const triageAgent = Agent.create({
name: 'Triage agent',
handoffs: [billingAgent, handoff(refundAgent)],
});
```
### Customising handoffs via `handoff()`
[Section titled “Customising handoffs via handoff()”](#customising-handoffs-via-handoff)
The `handoff()` function lets you tweak the generated tool.
* `agent` – the agent to hand off to.
* `toolNameOverride` – override the default `transfer_to_` tool name.
* `toolDescriptionOverride` – override the default tool description.
* `onHandoff` – callback when the handoff occurs. Receives a `RunContext` and, when `inputType` is configured, the parsed handoff payload.
* `inputType` – schema for the handoff tool-call arguments.
* `inputFilter` – filter the history passed to the next agent.
* `isEnabled` – boolean or predicate that exposes the handoff only for matching runs.
The `handoff()` helper always transfers control to the specific `agent` you passed in. If you have multiple possible destinations, register one handoff per destination and let the model choose among them. Use a custom `Handoff` when your own handoff code must decide which agent to return at invocation time.
Customized handoffs
```typescript
import { z } from 'zod';
import { Agent, handoff, RunContext } from '@openai/agents';
const FooSchema = z.object({ foo: z.string() });
function onHandoff(ctx: RunContext, input?: { foo: string }) {
console.log('Handoff called with:', input?.foo);
}
const agent = new Agent({ name: 'My agent' });
const handoffObj = handoff(agent, {
onHandoff,
inputType: FooSchema,
toolNameOverride: 'custom_handoff_tool',
toolDescriptionOverride: 'Custom description',
});
```
## Handoff inputs
[Section titled “Handoff inputs”](#handoff-inputs)
Sometimes you want the model to attach a small structured payload when it chooses a handoff. Define `inputType` and `onHandoff` together for that case.
Handoff inputs
```typescript
import { z } from 'zod';
import { Agent, handoff, RunContext } from '@openai/agents';
const EscalationData = z.object({ reason: z.string() });
type EscalationData = z.infer;
async function onHandoff(
ctx: RunContext,
input: EscalationData | undefined,
) {
console.log(`Escalation agent called with reason: ${input?.reason}`);
}
const agent = new Agent({ name: 'Escalation agent' });
const handoffObj = handoff(agent, {
onHandoff,
inputType: EscalationData,
});
```
`inputType` describes the arguments for the handoff tool call itself. The SDK exposes that schema to the model as the handoff tool’s `parameters`, parses the returned arguments locally, and passes the parsed value to `onHandoff`.
It does not replace the next agent’s main input, and it does not choose a different destination. The `handoff()` helper still transfers to the specific agent you wrapped, and the receiving agent still sees the conversation history unless you change it with an `inputFilter`.
`inputType` is also separate from `RunContext`. Use it for metadata the model decides at handoff time, not for application state or dependencies you already have locally.
### When to use `inputType`
[Section titled “When to use inputType”](#when-to-use-inputtype)
Use `inputType` when the handoff needs a small piece of model-generated routing metadata such as `reason`, `language`, `priority`, or `summary`. For example, a triage agent can hand off to a refund agent with `{ reason: 'duplicate_charge', priority: 'high' }`, and `onHandoff` can log or persist that metadata before the refund agent takes over.
Choose a different mechanism when the goal is different:
* Put existing application state in `RunContext`.
* Use `inputFilter` if you want to change what history the receiving agent sees.
* Register one handoff per destination if there are multiple possible specialists. `inputType` can add metadata to the chosen handoff, but it does not dispatch between destinations.
* Prefer a Zod schema when you want the SDK to validate the parsed payload before `onHandoff` runs; a raw JSON Schema only defines the tool contract sent to the model.
## Input filters
[Section titled “Input filters”](#input-filters)
By default a handoff receives the entire conversation history. To modify what gets passed to the next agent, provide an `inputFilter`. Common helpers live in `@openai/agents-core/extensions`.
Input filters
```typescript
import { Agent, handoff } from '@openai/agents';
import { removeAllTools } from '@openai/agents-core/extensions';
const agent = new Agent({ name: 'FAQ agent' });
const handoffObj = handoff(agent, {
inputFilter: removeAllTools,
});
```
An `inputFilter` receives and returns a `HandoffInputData` object:
* `inputHistory` – the input history before the run started.
* `preHandoffItems` – items generated before the turn where the handoff happened.
* `newItems` – items generated during the current turn, including the handoff call/output items.
* `runContext` – the active run context.
If you also configure `handoffInputFilter` on the `Runner`, the per-handoff `inputFilter` takes precedence for that specific handoff.
Note
Handoffs stay within a single run. Input guardrails still apply only to the first agent in the chain, and output guardrails only to the agent that produces the final output. Use tool guardrails when you need checks around each custom function-tool call inside the workflow.
## Recommended prompts
[Section titled “Recommended prompts”](#recommended-prompts)
LLMs respond more reliably when your prompts mention handoffs. The SDK exposes a recommended prefix via `RECOMMENDED_PROMPT_PREFIX`.
Recommended prompts
```typescript
import { Agent } from '@openai/agents';
import { RECOMMENDED_PROMPT_PREFIX } from '@openai/agents-core/extensions';
const billingAgent = new Agent({
name: 'Billing agent',
instructions: `${RECOMMENDED_PROMPT_PREFIX}
Fill in the rest of your prompt here.`,
});
```
## Related guides
[Section titled “Related guides”](#related-guides)
* [Agents](/openai-agents-js/guides/agents#composition-patterns) for choosing between managers and handoffs.
* [Agent orchestration](/openai-agents-js/guides/multi-agent) for the broader workflow tradeoffs.
* [Tools](/openai-agents-js/guides/tools#4-agents-as-tools) for the manager-style alternative using `agent.asTool()`.
* [Running agents](/openai-agents-js/guides/running-agents) for how handoffs behave at run time.
* [Results](/openai-agents-js/guides/results#final-output) for typed `finalOutput` across handoff graphs.
# Human-in-the-loop
> Add a human in the loop check for your agent executions
This guide covers the SDK’s approval-based human-in-the-loop flow. When a tool call requires approval, the SDK pauses the run, returns `interruptions`, and lets you resume later from the same `RunState`.
That approval surface is run-wide, not limited to the current top-level agent. The same pattern applies when the tool belongs to the current agent, to an agent reached through a handoff, or to a nested `agent.asTool()` execution. In the nested `agent.asTool()` case, the interruption still surfaces on the outer run, so you approve or reject it on the outer `result.state` and resume the original root run.
With `agent.asTool()`, approvals can happen at two different layers: the agent tool itself can require approval via `asTool({ needsApproval })`, and tools inside the nested agent can later raise their own approvals after the nested run starts. Both are handled through the same outer-run interruption flow.
This page focuses on the manual approval flow via `interruptions`. If your app can decide in code, some tool types also support programmatic approval callbacks so the run can continue without pausing. If you are setting up `agent.asTool()` itself, see the [tools guide](/openai-agents-js/guides/tools#4-agents-as-tools); this page covers what happens once any tool in that run hierarchy needs approval.
## Approval flow
[Section titled “Approval flow”](#approval-flow)
You can define a tool that requires approval by setting the `needsApproval` option to `true` or to an async function that returns a boolean.
Tool approval definition
```typescript
import { tool } from '@openai/agents';
import z from 'zod';
const sensitiveTool = tool({
name: 'cancelOrder',
description: 'Cancel order',
parameters: z.object({
orderId: z.number(),
}),
// always requires approval
needsApproval: true,
execute: async ({ orderId }, args) => {
// prepare order return
},
});
const sendEmail = tool({
name: 'sendEmail',
description: 'Send an email',
parameters: z.object({
to: z.string(),
subject: z.string(),
body: z.string(),
}),
needsApproval: async (_context, { subject }) => {
// check if the email is spam
return subject.includes('spam');
},
execute: async ({ to, subject, body }, args) => {
// send email
},
});
```
### Flow
[Section titled “Flow”](#flow)
1. When a tool invocation is about to execute, the SDK evaluates its approval rule (`needsApproval` or the hosted MCP equivalent).
2. If approval is required and no decision is stored yet, the tool call does not execute. Instead, the run records a [`RunToolApprovalItem`](/openai-agents-js/openai/agents/classes/runtoolapprovalitem).
3. At the end of that turn, the run pauses and returns all pending approvals in the [result](/openai-agents-js/guides/results) `interruptions` array. This includes approvals raised inside nested `agent.asTool()` runs.
4. Resolve each pending item with `result.state.approve(interruption)` or `result.state.reject(interruption)`. Pass `{ alwaysApprove: true }` or `{ alwaysReject: true }` if the same tool should stay approved or rejected for the rest of the run. When rejecting, you can also pass `{ message: '...' }` to control the rejection text that is sent back to the model for that specific tool call.
5. Resume by passing the updated `result.state` back into `runner.run(agent, state)`, where `agent` is the original top-level agent for the run. The SDK continues from the interrupted point, including nested agent-tool executions.
Sticky decisions created with `{ alwaysApprove: true }` or `{ alwaysReject: true }` are stored in the run state, so they survive `toString()` / `fromString()` when you resume the same paused run later.
Computer tool interruptions can represent a batch of actions in one `computer_call` on GA models. The SDK evaluates `needsApproval` per action before execution, so one pending approval can cover a sequence such as move + click. If you inspect `interruption.rawItem` to render a UI, handle both the GA `actions` array and the legacy single `action` field.
Serialized `RunState` also preserves computer approvals across both the current `computer` tool name and the legacy `computer_use_preview` name, so paused runs can resume cleanly during preview-to-GA migrations.
If you do not provide `message`, the SDK falls back to the configured `toolErrorFormatter` (if any) and then to the default rejection text.
You do not need to resolve every pending approval in the same pass. If you rerun after approving or rejecting only some items, those resolved calls can continue while unresolved ones remain in `interruptions` and pause the run again.
### Automatic approval decisions
[Section titled “Automatic approval decisions”](#automatic-approval-decisions)
Manual `interruptions` are the most general pattern, but they are not the only one:
* Local `shellTool()` and `applyPatchTool()` can use `onApproval` to approve or reject immediately in code.
* Hosted MCP tools can use `requireApproval` together with `onApproval` for the same kind of programmatic decision.
* Plain function tools use the manual interruption flow on this page.
When these callbacks return a decision, the run continues without pausing for a human response. For Realtime / voice session APIs, see the approval flow in the [voice agents build guide](/openai-agents-js/guides/voice-agents/build#approval-requests).
### Streaming and sessions
[Section titled “Streaming and sessions”](#streaming-and-sessions)
The same interruption flow works in streaming runs. After a streamed run pauses, wait for `stream.completed`, read `stream.interruptions`, resolve them, and call `run()` again with `{ stream: true }` if you want the resumed output to keep streaming. See [Human in the loop while streaming](/openai-agents-js/guides/streaming#human-in-the-loop-while-streaming) for the streamed version of this pattern.
If you are also using a `session`, keep passing the same `session` when you resume from `RunState`. The resumed turn is then appended to session memory without re-preparing the input. See the [sessions guide](/openai-agents-js/guides/sessions) for the session lifecycle details.
## Example
[Section titled “Example”](#example)
Below is a more complete example of a human-in-the-loop flow that prompts for approval in the terminal and temporarily stores the state in a file.
Human in the loop
```typescript
import { z } from 'zod';
import readline from 'node:readline/promises';
import fs from 'node:fs/promises';
import { Agent, run, tool, RunState, RunResult } from '@openai/agents';
const getWeatherTool = tool({
name: 'get_weather',
description: 'Get the weather for a given city',
parameters: z.object({
location: z.string(),
}),
needsApproval: async (_context, { location }) => {
// forces approval to look up the weather in San Francisco
return location === 'San Francisco';
},
execute: async ({ location }) => {
return `The weather in ${location} is sunny`;
},
});
const dataAgentTwo = new Agent({
name: 'Data agent',
instructions: 'You are a data agent',
handoffDescription: 'You know everything about the weather',
tools: [getWeatherTool],
});
const agent = new Agent({
name: 'Basic test agent',
instructions: 'You are a basic agent',
handoffs: [dataAgentTwo],
});
async function confirm(question: string) {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
const answer = await rl.question(`${question} (y/n): `);
const normalizedAnswer = answer.toLowerCase();
rl.close();
return normalizedAnswer === 'y' || normalizedAnswer === 'yes';
}
async function main() {
let result: RunResult> = await run(
agent,
'What is the weather in Oakland and San Francisco?',
);
let hasInterruptions = result.interruptions?.length > 0;
while (hasInterruptions) {
// storing
await fs.writeFile(
'result.json',
JSON.stringify(result.state, null, 2),
'utf-8',
);
// from here on you could run things on a different thread/process
// reading later on
const storedState = await fs.readFile('result.json', 'utf-8');
const state = await RunState.fromString(agent, storedState);
for (const interruption of result.interruptions) {
const confirmed = await confirm(
`Agent ${interruption.agent.name} would like to use the tool ${interruption.name} with "${interruption.arguments}". Do you approve?`,
);
if (confirmed) {
state.approve(interruption);
} else {
state.reject(interruption);
}
}
// resume execution of the current state
result = await run(agent, state);
hasInterruptions = result.interruptions?.length > 0;
}
console.log(result.finalOutput);
}
main().catch((error) => {
console.dir(error, { depth: null });
});
```
See [the full example script](https://github.com/openai/openai-agents-js/tree/main/examples/agent-patterns/human-in-the-loop.ts) for a working end-to-end version.
## Dealing with longer approval times
[Section titled “Dealing with longer approval times”](#dealing-with-longer-approval-times)
The human-in-the-loop flow is designed to be interruptible for longer periods of time without keeping your server running. If you need to shut down the request and continue later on you can serialize the state and resume later.
You can serialize the state using `result.state.toString()` (or `JSON.stringify(result.state)`) and resume later on by passing the serialized state into `RunState.fromString(agent, serializedState)` where `agent` is the instance of the agent that triggered the overall run.
When `RunState` is serialized, the SDK records stable agent identities for the handoff and `Agent.asTool()` graph. This lets paused runs resume even when distinct agents share the same `name`, as long as the process that resumes the run rebuilds the same agent graph.
If the resumed process needs to inject a fresh context object, use `RunState.fromStringWithContext(agent, serializedState, context, { contextStrategy })` instead.
* `contextStrategy: 'merge'` (default) keeps the provided `RunContext`, merges in the serialized approval state, and restores serialized `toolInput` when the new context does not already define one.
* `contextStrategy: 'replace'` rebuilds the run using the provided `RunContext` as-is.
Serialized run state includes your app context plus SDK-managed runtime metadata such as approvals, usage, nested `toolInput`, and pending nested agent-tool resumptions. If you plan to store or transmit serialized state, treat `runContext.context` as persisted data and avoid placing secrets there unless you intentionally want them to travel with the state.
By default tracing API keys are omitted from serialized state so you do not accidentally persist secrets. Pass `result.state.toString({ includeTracingApiKey: true })` only when you intentionally need to move tracing credentials with the state.
That way you can store your serialized state in a database, or along with your request.
### Versioning pending tasks
[Section titled “Versioning pending tasks”](#versioning-pending-tasks)
Note
This primarily applies if you are trying to store your serialized state for a longer time while doing changes to your agents.
If your approval requests take a longer time and you intend to version your agent definitions in a meaningful way or bump your Agents SDK version, we currently recommend for you to implement your own branching logic by installing two versions of the Agents SDK in parallel using package aliases.
In practice this means assigning your own code a version number and storing it along with the serialized state and guiding the deserialization to the correct version of your code.
# Model Context Protocol (MCP)
> Learn how to utilize MCP servers as tools
The [**Model Context Protocol (MCP)**](https://modelcontextprotocol.io) is an open protocol that standardizes how applications provide tools and context to LLMs. From the MCP docs:
> MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
There are three types of MCP servers this SDK supports:
1. **Hosted MCP server tools** – remote MCP servers used as tools by the [OpenAI Responses API](https://platform.openai.com/docs/guides/tools-remote-mcp)
2. **Streamable HTTP MCP servers** – local or remote servers that implement the [Streamable HTTP transport](https://modelcontextprotocol.io/docs/concepts/transports#streamable-http)
3. **Stdio MCP servers** – servers accessed via standard input/output (the simplest option)
> Note: The SDK also includes `MCPServerSSE` for legacy Server‑Sent Events transports, but SSE has been deprecated by the MCP project. Prefer Streamable HTTP or stdio for new integrations.
Choose a server type based on your use‑case:
| What you need | Recommended option |
| -------------------------------------------------------------------------------- | ----------------------- |
| Call publicly accessible remote servers with default OpenAI responses models | **1. Hosted MCP tools** |
| Use publicly accessible remote servers but have the tool calls triggered locally | **2. Streamable HTTP** |
| Use locally running Streamable HTTP servers | **2. Streamable HTTP** |
| Use any Streamable HTTP servers with non-OpenAI-Responses models | **2. Streamable HTTP** |
| Work with local MCP servers that only support the standard-I/O protocol | **3. Stdio** |
## 1. Hosted MCP server tools
[Section titled “1. Hosted MCP server tools”](#1-hosted-mcp-server-tools)
Hosted tools push the entire round‑trip into the model. Instead of your code calling an MCP server, the OpenAI Responses API invokes the remote tool endpoint and streams the result back to the model.
Here is the simplest example of using hosted MCP tools. You can pass the remote MCP server’s label and URL to the `hostedMcpTool` utility function, which is helpful for creating hosted MCP server tools.
hostedAgent.ts
```typescript
import { Agent, hostedMcpTool } from '@openai/agents';
export const agent = new Agent({
name: 'MCP Assistant',
instructions: 'You must always use the MCP tools to answer questions.',
tools: [
hostedMcpTool({
serverLabel: 'deepwiki',
serverUrl: 'https://mcp.deepwiki.com/mcp',
}),
],
});
```
Then, you can run the Agent with the `run` function (or your own customized `Runner` instance’s `run` method):
Run with hosted MCP tools
```typescript
import { run } from '@openai/agents';
import { agent } from './hostedAgent';
async function main() {
const result = await run(
agent,
'Which language is the repo I pointed in the MCP tool settings written in?',
);
console.log(result.finalOutput);
}
main().catch(console.error);
```
To stream incremental MCP results, pass `stream: true` when you run the `Agent`:
Run with hosted MCP tools (streaming)
```typescript
import { isOpenAIResponsesRawModelStreamEvent, run } from '@openai/agents';
import { agent } from './hostedAgent';
async function main() {
const result = await run(
agent,
'Which language is the repo I pointed in the MCP tool settings written in?',
{ stream: true },
);
for await (const event of result) {
if (
isOpenAIResponsesRawModelStreamEvent(event) &&
event.data.event.type !== 'response.mcp_call_arguments.delta' &&
event.data.event.type !== 'response.output_text.delta'
) {
console.log(`Got event of type ${JSON.stringify(event.data)}`);
}
}
console.log(`Done streaming; final result: ${result.finalOutput}`);
}
main().catch(console.error);
```
### Optional approval flow
[Section titled “Optional approval flow”](#optional-approval-flow)
For sensitive operations you can require human approval of individual tool calls. Pass either `requireApproval: 'always'` or a fine‑grained object mapping tool names to `'never'`/`'always'`.
If you can programmatically determine whether a tool call is safe, you can use the [`onApproval` callback](https://github.com/openai/openai-agents-js/blob/main/examples/mcp/hosted-mcp-on-approval.ts) to approve or reject the tool call. If you require human approval, you can use the same [human-in-the-loop (HITL) approach](/openai-agents-js/guides/human-in-the-loop/) using `interruptions` as for local function tools.
Human in the loop with hosted MCP tools
```typescript
import { Agent, run, hostedMcpTool, RunToolApprovalItem } from '@openai/agents';
async function main(): Promise {
const agent = new Agent({
name: 'MCP Assistant',
instructions: 'You must always use the MCP tools to answer questions.',
tools: [
hostedMcpTool({
serverLabel: 'deepwiki',
serverUrl: 'https://mcp.deepwiki.com/mcp',
// 'always' | 'never' | { never, always }
requireApproval: {
never: {
toolNames: ['read_wiki_structure', 'read_wiki_contents'],
},
always: {
toolNames: ['ask_question'],
},
},
}),
],
});
let result = await run(
agent,
'For the repository openai/codex, tell me the primary programming language.',
);
while (result.interruptions && result.interruptions.length) {
for (const interruption of result.interruptions) {
// Human in the loop here
const approval = await confirm(interruption);
if (approval) {
result.state.approve(interruption);
} else {
result.state.reject(interruption);
}
}
result = await run(agent, result.state);
}
console.log(result.finalOutput);
}
import { stdin, stdout } from 'node:process';
import * as readline from 'node:readline/promises';
async function confirm(item: RunToolApprovalItem): Promise {
const rl = readline.createInterface({ input: stdin, output: stdout });
const name = item.name;
const params = item.arguments;
const answer = await rl.question(
`Approve running tool (mcp: ${name}, params: ${params})? (y/n) `,
);
rl.close();
return answer.toLowerCase().trim() === 'y';
}
main().catch(console.error);
```
### Hosted MCP options reference
[Section titled “Hosted MCP options reference”](#hosted-mcp-options-reference)
`hostedMcpTool(...)` supports both MCP server URLs and connector-backed servers:
| Option | Type | Notes |
| ----------------- | ------------------------------- | ------------------------------------------------------------------------------------------------------------- |
| `serverLabel` | `string` | Required label that identifies the hosted MCP server in events and traces. |
| `serverUrl` | `string` | Remote MCP server URL (use this for regular hosted MCP servers). |
| `connectorId` | `string` | OpenAI connector id (use this instead of `serverUrl` for connector-backed hosted servers). |
| `authorization` | `string` | Optional authorization token sent to the hosted MCP backend. |
| `headers` | `Record` | Optional extra request headers. |
| `allowedTools` | `string[] \| object` | Allowlist of tool names exposed to the model. Pass `string[]` or `{ toolNames?: string[] }`. |
| `deferLoading` | `boolean` | Responses-only deferred loading for hosted MCP tools. Requires `toolSearchTool()` in the same agent. |
| `requireApproval` | `'never' \| 'always' \| object` | Approval policy for hosted MCP tool calls. Use the object form for per-tool overrides. Defaults to `'never'`. |
| `onApproval` | Approval callback | Optional callback for programmatic approval/rejection when `requireApproval` requires approval handling. |
Set `deferLoading: true` when you want the model to load a hosted MCP server’s tool definitions on demand via tool search instead of exposing them up front. This only works with the OpenAI Responses API, requires `toolSearchTool()` in the same request, and should be used with GPT-5.4 and newer supported model releases. See the [Tools guide](/openai-agents-js/guides/tools#deferred-tool-loading-with-tool-search) for the full deferred-loading setup.
`requireApproval` object form:
```ts
{
always?: { toolNames: string[] };
never?: { toolNames: string[] };
}
```
`onApproval` signature:
```ts
async function onApproval(
context,
item,
): Promise<{
approve: boolean;
reason?: string;
}> {}
```
### Connector-backed hosted servers
[Section titled “Connector-backed hosted servers”](#connector-backed-hosted-servers)
Hosted MCP also supports OpenAI connectors. Instead of providing a `serverUrl`, pass the connector’s `connectorId` and an `authorization` token. The Responses API then handles authentication and exposes the connector’s tools through the hosted MCP interface.
Connector-backed hosted MCP tool
```typescript
import { Agent, hostedMcpTool } from '@openai/agents';
const authorization = process.env.GOOGLE_CALENDAR_AUTHORIZATION!;
export const connectorAgent = new Agent({
name: 'Calendar Assistant',
instructions:
"You are a helpful assistant that can answer questions about the user's calendar.",
tools: [
hostedMcpTool({
serverLabel: 'google_calendar',
connectorId: 'connector_googlecalendar',
authorization,
requireApproval: 'never',
}),
],
});
```
In this example the `GOOGLE_CALENDAR_AUTHORIZATION` environment variable holds an OAuth token obtained from the Google OAuth Playground, which authorizes the connector-backed server to call the Calendar API. For a runnable sample that also demonstrates streaming, see [`examples/connectors`](https://github.com/openai/openai-agents-js/tree/main/examples/connectors).
Fully working samples (Hosted tools/Streamable HTTP/stdio + Streaming, HITL, onApproval) are [examples/mcp](https://github.com/openai/openai-agents-js/tree/main/examples/mcp) in our GitHub repository.
## Agent-level MCP configuration
[Section titled “Agent-level MCP configuration”](#agent-level-mcp-configuration)
In addition to choosing a transport, you can tune how local MCP tools are prepared by setting `Agent.mcpConfig`.
```ts
const agent = new Agent({
name: 'Assistant',
mcpServers: [server],
mcpConfig: {
// Try to convert MCP tool schemas to strict JSON schema.
convertSchemasToStrict: true,
// Set to null to raise MCP tool failures instead of returning model-visible error text.
errorFunction: null,
// Prefix local MCP tool names with their server name.
includeServerInToolNames: true,
},
});
```
Notes:
* `convertSchemasToStrict` is best-effort. If a schema cannot be converted, the original schema is used.
* `errorFunction` controls how MCP tool call failures are surfaced to the model.
* When `errorFunction` is unset, the SDK uses the default tool error formatter.
* Server-level `errorFunction` values override `Agent.mcpConfig.errorFunction` for that server.
* `includeServerInToolNames` is opt-in. When enabled, each local MCP tool is exposed to the model with a deterministic server-prefixed name, which helps avoid collisions when multiple MCP servers publish tools with the same name.
## 2. Streamable HTTP MCP servers
[Section titled “2. Streamable HTTP MCP servers”](#2-streamable-http-mcp-servers)
When your Agent talks directly to a Streamable HTTP MCP server—local or remote—instantiate `MCPServerStreamableHttp` with the server `url`, `name`, and any optional settings:
Run with Streamable HTTP MCP servers
```typescript
import { Agent, run, MCPServerStreamableHttp } from '@openai/agents';
async function main() {
const mcpServer = new MCPServerStreamableHttp({
url: 'https://mcp.deepwiki.com/mcp',
name: 'DeepWiki MCP Server',
});
const agent = new Agent({
name: 'DeepWiki Assistant',
instructions: 'Use the tools to respond to user requests.',
mcpServers: [mcpServer],
});
try {
await mcpServer.connect();
const result = await run(
agent,
'For the repository openai/codex, tell me the primary programming language.',
);
console.log(result.finalOutput);
} finally {
await mcpServer.close();
}
}
main().catch(console.error);
```
Constructor options:
| Option | Type | Notes |
| ----------------------------- | ---------------------------------------------- | -------------------------------------------- |
| `url` | `string` | Streamable HTTP server URL. |
| `name` | `string` | Optional label for the server. |
| `cacheToolsList` | `boolean` | Cache tools list to reduce latency. |
| `clientSessionTimeoutSeconds` | `number` | Timeout for MCP client sessions. |
| `toolFilter` | `MCPToolFilterCallable \| MCPToolFilterStatic` | Filter available tools. |
| `toolMetaResolver` | `MCPToolMetaResolver` | Inject per-call MCP `_meta` request fields. |
| `errorFunction` | `MCPToolErrorFunction \| null` | Map MCP call failures to model-visible text. |
| `timeout` | `number` | Per-request timeout (milliseconds). |
| `logger` | `Logger` | Custom logger. |
| `authProvider` | `OAuthClientProvider` | OAuth provider from the MCP TypeScript SDK. |
| `requestInit` | `RequestInit` | Fetch init options for requests. |
| `fetch` | `FetchLike` | Custom fetch implementation. |
| `reconnectionOptions` | `StreamableHTTPReconnectionOptions` | Reconnection tuning options. |
| `sessionId` | `string` | Explicit session id for MCP connections. |
The constructor also accepts additional MCP TypeScript‑SDK options such as `authProvider`, `requestInit`, `fetch`, `reconnectionOptions`, and `sessionId`. See the [MCP TypeScript SDK repository](https://github.com/modelcontextprotocol/typescript-sdk) and its documents for details.
## 3. Stdio MCP servers
[Section titled “3. Stdio MCP servers”](#3-stdio-mcp-servers)
For servers that expose only standard I/O, instantiate `MCPServerStdio` with a `fullCommand`:
Run with Stdio MCP servers
```typescript
import { Agent, run, MCPServerStdio } from '@openai/agents';
import * as path from 'node:path';
async function main() {
const samplesDir = path.join(__dirname, 'sample_files');
const mcpServer = new MCPServerStdio({
name: 'Filesystem MCP Server, via local package',
fullCommand: `pnpm exec mcp-server-filesystem ${samplesDir}`,
});
await mcpServer.connect();
try {
const agent = new Agent({
name: 'FS MCP Assistant',
instructions:
'Use the tools to read the filesystem and answer questions based on those files. If you are unable to find any files, you can say so instead of assuming they exist.',
mcpServers: [mcpServer],
});
const result = await run(agent, 'Read the files and list them.');
console.log(result.finalOutput);
} finally {
await mcpServer.close();
}
}
main().catch(console.error);
```
Constructor options:
| Option | Type | Notes |
| ----------------------------- | ---------------------------------------------- | ------------------------------------------------------ |
| `command` / `args` | `string` / `string[]` | Command + args for stdio servers. |
| `fullCommand` | `string` | Full command string alternative to `command` + `args`. |
| `env` | `Record` | Environment variables for the server process. |
| `cwd` | `string` | Working directory for the server process. |
| `cacheToolsList` | `boolean` | Cache tools list to reduce latency. |
| `clientSessionTimeoutSeconds` | `number` | Timeout for MCP client sessions. |
| `name` | `string` | Optional label for the server. |
| `encoding` | `string` | Encoding for stdio streams. |
| `encodingErrorHandler` | `'strict' \| 'ignore' \| 'replace'` | Encoding error strategy. |
| `toolFilter` | `MCPToolFilterCallable \| MCPToolFilterStatic` | Filter available tools. |
| `toolMetaResolver` | `MCPToolMetaResolver` | Inject per-call MCP `_meta` request fields. |
| `errorFunction` | `MCPToolErrorFunction \| null` | Map MCP call failures to model-visible text. |
| `timeout` | `number` | Per-request timeout (milliseconds). |
| `logger` | `Logger` | Custom logger. |
## Managing MCP server lifecycle
[Section titled “Managing MCP server lifecycle”](#managing-mcp-server-lifecycle)
When you work with multiple MCP servers, you can use `connectMcpServers` to connect them together, track failures, and close them in one place. The helper returns an `MCPServers` instance with `active`, `failed`, and `errors` collections so you can pass only healthy servers to your agent.
Manage multiple MCP servers
```typescript
import {
Agent,
MCPServerStreamableHttp,
connectMcpServers,
run,
} from '@openai/agents';
async function main() {
const servers = [
new MCPServerStreamableHttp({
url: 'https://mcp.deepwiki.com/mcp',
name: 'DeepWiki MCP Server',
}),
new MCPServerStreamableHttp({
url: 'http://localhost:8001/mcp',
name: 'Local MCP Server',
}),
];
const mcpServers = await connectMcpServers(servers, {
connectInParallel: true,
});
try {
console.log(`Active servers: ${mcpServers.active.length}`);
console.log(`Failed servers: ${mcpServers.failed.length}`);
for (const [server, error] of mcpServers.errors) {
console.warn(`${server.name} failed to connect: ${error.message}`);
}
const agent = new Agent({
name: 'MCP lifecycle agent',
instructions: 'Use MCP tools to answer user questions.',
mcpServers: mcpServers.active,
});
const result = await run(
agent,
'Which language is the openai/codex repository written in?',
);
console.log(result.finalOutput);
} finally {
await mcpServers.close();
}
}
main().catch(console.error);
```
Use cases:
* **Multiple servers at once**: connect everything in parallel and use `mcpServers.active` for the agent.
* **Partial failure handling**: inspect `failed` + `errors` and decide whether to continue or retry.
* **Retry failed servers**: call `mcpServers.reconnect()` (defaults to retrying failed servers only).
If you want a strict “all or nothing” connection or different timeouts, use `connectMcpServers(servers, options)` and tune the options for your environment.
`connectMcpServers` options:
| Option | Type | Default | Notes |
| -------------------- | ---------------- | ------- | ------------------------------------------------------------- |
| `connectTimeoutMs` | `number \| null` | `10000` | Timeout for each server `connect()`. Use `null` to disable. |
| `closeTimeoutMs` | `number \| null` | `10000` | Timeout for each server `close()`. Use `null` to disable. |
| `dropFailed` | `boolean` | `true` | Exclude failed servers from `active`. |
| `strict` | `boolean` | `false` | Throw if any server fails to connect. |
| `suppressAbortError` | `boolean` | `true` | Ignore abort-like errors while still tracking failed servers. |
| `connectInParallel` | `boolean` | `false` | Connect all servers concurrently instead of sequentially. |
`mcpServers.reconnect(options)` supports:
| Option | Type | Default | Notes |
| ------------ | --------- | ------- | ---------------------------------------------------------------------- |
| `failedOnly` | `boolean` | `true` | Retry only failed servers (`true`) or reconnect all servers (`false`). |
### Async disposal (optional)
[Section titled “Async disposal (optional)”](#async-disposal-optional)
If your runtime supports `Symbol.asyncDispose`, `MCPServers` also supports the `await using` pattern. In TypeScript, enable `esnext.disposable` in `tsconfig.json`:
```json
{
"compilerOptions": {
"lib": ["ES2018", "DOM", "esnext.disposable"]
}
}
```
Then you can write:
```ts
await using mcpServers = await connectMcpServers(servers);
```
## Other things to know
[Section titled “Other things to know”](#other-things-to-know)
For **Streamable HTTP** and **Stdio** servers, each time an `Agent` runs it may call `list_tools()` to discover available tools. Because that round‑trip can add latency—especially to remote servers—you can cache the results in memory by passing `cacheToolsList: true` to `MCPServerStdio` or `MCPServerStreamableHttp`.
Only enable this if you’re confident the tool list won’t change. To invalidate the cache later, call `invalidateToolsCache()` on the server instance. If you are using shared MCP tool caching via `getAllMcpTools(...)`, you can also invalidate by server name with `invalidateServerToolsCache(serverName)`.
For advanced cases, `getAllMcpTools({ generateMCPToolCacheKey })` lets you customize cache partitioning (for example, by server + agent + run context).
### Server-prefixed tool names
[Section titled “Server-prefixed tool names”](#server-prefixed-tool-names)
By default, local MCP tools keep the tool name reported by the MCP server. If two local MCP servers expose the same tool name, the SDK raises a duplicate tool name error because the model cannot safely choose between them.
To opt in to deterministic server-prefixed names, set `mcpConfig.includeServerInToolNames: true` on the agent:
```ts
const agent = new Agent({
name: 'Assistant',
mcpServers: [docsServer, calendarServer],
mcpConfig: {
includeServerInToolNames: true,
},
});
```
With this setting, a `search` tool from a `docs` server is exposed to the model as `mcp_docs__search`, while a `search` tool from a `calendar` server is exposed as `mcp_calendar__search`. The SDK still invokes the original MCP tool name on the original server.
Generated names are ASCII-safe, stay within the function-tool name limit, and avoid local function tool names and enabled handoff names on the same agent. The setting only affects local Streamable HTTP and stdio MCP tools; hosted MCP tools keep their hosted server labels and tool metadata.
### Tool filtering
[Section titled “Tool filtering”](#tool-filtering)
You can restrict which tools are exposed from each server by passing either a static filter via `createMCPToolStaticFilter` or a custom function. Here’s a combined example showing both approaches:
Tool filtering
```typescript
import {
MCPServerStdio,
MCPServerStreamableHttp,
createMCPToolStaticFilter,
MCPToolFilterContext,
} from '@openai/agents';
interface ToolFilterContext {
allowAll: boolean;
}
const server = new MCPServerStdio({
fullCommand: 'my-server',
toolFilter: createMCPToolStaticFilter({
allowed: ['safe_tool'],
blocked: ['danger_tool'],
}),
});
const dynamicServer = new MCPServerStreamableHttp({
url: 'http://localhost:3000',
toolFilter: async ({ runContext }: MCPToolFilterContext, tool) =>
(runContext.context as ToolFilterContext).allowAll || tool.name !== 'admin',
});
```
## Further reading
[Section titled “Further reading”](#further-reading)
* [Model Context Protocol](https://modelcontextprotocol.io/) – official specification.
* [examples/mcp](https://github.com/openai/openai-agents-js/tree/main/examples/mcp) – runnable demos referenced above.
# Models
> Choose and configure language models for your agents
Every Agent ultimately calls an LLM. The SDK abstracts models behind two lightweight interfaces:
* [`Model`](/openai-agents-js/openai/agents/interfaces/model) – knows how to make *one* request against a specific API.
* [`ModelProvider`](/openai-agents-js/openai/agents/interfaces/modelprovider) – resolves human‑readable model **names** (e.g. `'gpt‑5.4'`) to `Model` instances.
In day‑to‑day work you normally only interact with model **names** and occasionally `ModelSettings`.
Specifying a model per‑agent
```typescript
import { Agent } from '@openai/agents';
const agent = new Agent({
name: 'Creative writer',
model: 'gpt-5.4',
});
```
## Choosing models
[Section titled “Choosing models”](#choosing-models)
### Default model
[Section titled “Default model”](#default-model)
When you don’t specify a model when initializing an `Agent`, the default model will be used. The default is currently [`gpt-5.4-mini`](https://developers.openai.com/api/docs/models/gpt-5.4-mini) with `reasoning.effort: "none"` and `text.verbosity: "low"` for a balance of quality and latency.
If you want to switch to another model like [`gpt-5.5`](https://developers.openai.com/api/docs/models/gpt-5.5), there are two ways to configure your agents.
First, if you want to consistently use a specific model for all agents that do not set a custom model, set the `OPENAI_DEFAULT_MODEL` environment variable before running your agents.
```bash
export OPENAI_DEFAULT_MODEL=gpt-5.5
node my-awesome-agent.js
```
Second, you can set a default model for a `Runner` instance. If you don’t set a model for an agent, this `Runner`’s default model will be used.
Set a default model for a Runner
```typescript
import { Runner } from '@openai/agents';
const runner = new Runner({ model: 'gpt‑4.1-mini' });
```
#### GPT-5.x models
[Section titled “GPT-5.x models”](#gpt-5x-models)
When you use any GPT-5.x model such as [`gpt-5.4`](https://developers.openai.com/api/docs/models/gpt-5.4) in this way, the SDK applies default `modelSettings`. It sets the ones that work the best for most use cases. To adjust the reasoning effort for the default model, pass your own `modelSettings`:
Customize GPT-5 default settings
```typescript
import { Agent } from '@openai/agents';
const myAgent = new Agent({
name: 'My Agent',
instructions: "You're a helpful agent.",
// If OPENAI_DEFAULT_MODEL=gpt-5.4 is set, passing only modelSettings works.
// It's also fine to pass a GPT-5.x model name explicitly:
model: 'gpt-5.4',
modelSettings: {
reasoning: { effort: 'high' },
text: { verbosity: 'low' },
},
});
```
If latency matters, start with the default `gpt-5.4-mini` configuration or use `reasoning.effort: "none"` on another GPT-5.x model, then increase reasoning effort only if your task needs more deliberate reasoning.
#### Non-GPT-5 models
[Section titled “Non-GPT-5 models”](#non-gpt-5-models)
If you pass a non–GPT-5 model name without custom `modelSettings`, the SDK reverts to generic `modelSettings` compatible with any model.
***
## OpenAI provider configuration
[Section titled “OpenAI provider configuration”](#openai-provider-configuration)
### The OpenAI provider
[Section titled “The OpenAI provider”](#the-openai-provider)
The default `ModelProvider` resolves names using the OpenAI APIs. It supports two distinct endpoints:
| API | Usage | Call `setOpenAIAPI()` |
| ---------------- | ----------------------------------------------------------------- | --------------------------------------- |
| Chat Completions | Standard chat & function calls | `setOpenAIAPI('chat_completions')` |
| Responses | New streaming‑first generative API (tool calls, flexible outputs) | `setOpenAIAPI('responses')` *(default)* |
#### Authentication
[Section titled “Authentication”](#authentication)
Set default OpenAI key
```typescript
import { setDefaultOpenAIKey } from '@openai/agents';
setDefaultOpenAIKey(process.env.OPENAI_API_KEY!); // sk-...
```
You can also plug your own `OpenAI` client via `setDefaultOpenAIClient(client)` if you need custom networking settings.
#### Responses WebSocket transport
[Section titled “Responses WebSocket transport”](#responses-websocket-transport)
When you use the OpenAI provider with the Responses API, you can send requests over a WebSocket transport instead of the default HTTP transport.
Enable it globally with `setOpenAIResponsesTransport('websocket')`, or enable it per provider with `new OpenAIProvider({ useResponses: true, useResponsesWebSocket: true })`.
You do not need `withResponsesWebSocketSession(...)` or a custom `OpenAIProvider` just to use the WebSocket transport. If reconnecting for each run/request is acceptable, your existing `run()` / `Runner.run()` usage will continue to work after enabling `setOpenAIResponsesTransport('websocket')`.
Transport selection follows model resolution:
* `setOpenAIResponsesTransport('websocket')` only affects string model names that are later resolved through the OpenAI provider while using the Responses API.
* If you pass a concrete `Model` instance to an `Agent` or `Runner`, that instance is used as-is. `OpenAIResponsesWSModel` stays on WebSocket, `OpenAIResponsesModel` stays on HTTP, and `OpenAIChatCompletionsModel` stays on Chat Completions.
* If you provide your own `modelProvider`, that provider controls model resolution. Enable WebSocket there instead of relying on the global setter.
* If you route through a proxy, gateway, or other OpenAI-compatible endpoint, the target must support the WebSocket `/responses` endpoint. You may also need to set `websocketBaseURL` explicitly.
Use `withResponsesWebSocketSession(...)` or a custom `OpenAIProvider` / `Runner` only when you want to optimize connection reuse and manage the websocket provider lifecycle more explicitly:
* `withResponsesWebSocketSession(...)`: convenient scoped lifecycle with automatic cleanup after the callback.
* Custom `OpenAIProvider` / `Runner`: explicit lifecycle control (including shutdown cleanup) in your own app architecture.
Despite the name, `withResponsesWebSocketSession(...)` is a transport lifecycle helper and is unrelated to the memory `Session` interface described in the [sessions guide](/openai-agents-js/guides/sessions).
If you use a websocket proxy or gateway, configure `websocketBaseURL` on `OpenAIProvider` or set `OPENAI_WEBSOCKET_BASE_URL`.
If you instantiate `OpenAIProvider` yourself, remember that websocket-backed Responses model wrappers are cached by default for connection reuse. Call `await provider.close()` during shutdown to release those cached connections. `withResponsesWebSocketSession(...)` exists largely to manage that lifecycle for you: it creates a websocket-enabled provider and runner, passes them to your callback, and always closes the provider afterward. Use `providerOptions` for the temporary provider and `runnerConfig` for callback-scoped runner defaults.
See [`examples/basic/stream-ws.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/basic/stream-ws.ts) for a full streaming + HITL example using the Responses WebSocket transport.
#### Responses-only deferred tool loading
[Section titled “Responses-only deferred tool loading”](#responses-only-deferred-tool-loading)
`toolSearchTool()`, `toolNamespace()`, and function tools or hosted MCP tools that set `deferLoading: true` require the OpenAI Responses API. The Chat Completions provider rejects namespaced or deferred function tools, and the AI SDK adapter does not support deferred Responses tool-loading flows. Use a Responses model directly when you need tool search.
Tool search is supported only on GPT-5.4 and newer model releases that support it in the Responses API.
When a run includes deferred tools, add `toolSearchTool()` to the same agent and keep `modelSettings.toolChoice` on `'auto'`. The SDK does not let you force the built-in `tool_search` tool or a deferred function tool by name because the model needs to decide when to load those definitions. See the [Tools guide](/openai-agents-js/guides/tools#deferred-tool-loading-with-tool-search) and the official [OpenAI tool search guide](https://developers.openai.com/api/docs/guides/tools-tool-search) for the full setup.
***
## Model behavior and prompts
[Section titled “Model behavior and prompts”](#model-behavior-and-prompts)
### ModelSettings
[Section titled “ModelSettings”](#modelsettings)
`ModelSettings` mirrors the OpenAI parameters but is provider‑agnostic.
| Field | Type | Notes |
| ---------------------- | --------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `temperature` | `number` | Creativity vs. determinism. |
| `topP` | `number` | Nucleus sampling. |
| `frequencyPenalty` | `number` | Penalise repeated tokens. |
| `presencePenalty` | `number` | Encourage new tokens. |
| `toolChoice` | `'auto' \| 'required' \| 'none' \| string` | See [forcing tool use](/openai-agents-js/guides/agents#forcing-tool-use). On OpenAI Responses, `toolChoice: 'computer'` forces the GA built-in computer tool when available. |
| `parallelToolCalls` | `boolean` | Allow parallel function calls where supported. |
| `truncation` | `'auto' \| 'disabled'` | Token truncation strategy. |
| `maxTokens` | `number` | Maximum tokens in the response. |
| `store` | `boolean` | Persist the response for retrieval / RAG workflows. |
| `promptCacheRetention` | `'in-memory' \| '24h' \| null` | Controls provider prompt-cache retention when supported. |
| `contextManagement` | `ModelSettingsContextManagement` | Controls provider context management, such as server-side compaction. |
| `reasoning.effort` | `'none' \| 'minimal' \| 'low' \| 'medium' \| 'high' \| 'xhigh'` | Reasoning effort for gpt-5.x models. |
| `reasoning.summary` | `'auto' \| 'concise' \| 'detailed'` | Controls how much reasoning summary the model returns. |
| `text.verbosity` | `'low' \| 'medium' \| 'high'` | Text verbosity for gpt-5.x etc. |
| `providerData` | `Record` | Provider-specific passthrough options forwarded to the underlying model. |
| `retry` | `ModelRetrySettings` | Runtime-only opt-in retry config. See [Model retries](#model-retries). |
Attach settings at either level:
Model settings
```typescript
import { Runner, Agent } from '@openai/agents';
const agent = new Agent({
name: 'Creative writer',
// ...
modelSettings: { temperature: 0.7, toolChoice: 'auto' },
});
// or globally
new Runner({ modelSettings: { temperature: 0.3 } });
```
`Runner`‑level settings override any conflicting per‑agent settings. `retry` is the notable exception: its nested fields are merged across runner and agent settings unless you explicitly clear inherited values with `undefined`.
### Model retries
[Section titled “Model retries”](#model-retries)
Retries are runtime-only and opt-in. The SDK does not retry model requests unless you configure `modelSettings.retry` and your policy returns a retry decision.
Opt in to model retries
```typescript
import { Agent, Runner, retryPolicies } from '@openai/agents';
const sharedRetry = {
maxRetries: 4,
backoff: {
initialDelayMs: 500,
maxDelayMs: 5_000,
multiplier: 2,
jitter: true,
},
policy: retryPolicies.any(
retryPolicies.providerSuggested(),
retryPolicies.retryAfter(),
retryPolicies.networkError(),
retryPolicies.httpStatus([408, 409, 429, 500, 502, 503, 504]),
),
};
const runner = new Runner({
modelSettings: {
retry: sharedRetry,
},
});
const agent = new Agent({
name: 'Assistant',
instructions: 'You are a concise assistant.',
modelSettings: {
retry: {
maxRetries: 2,
backoff: {
maxDelayMs: 2_000,
},
},
},
});
await runner.run(agent, 'Summarize exponential backoff in plain English.');
```
`ModelRetrySettings` has three fields:
| Field | Type | Notes |
| ------------ | -------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `maxRetries` | `number` | Number of retry attempts allowed after the initial request. |
| `backoff` | `{ initialDelayMs?, maxDelayMs?, multiplier?, jitter? }` | Default delay strategy when the policy retries without returning `delayMs`. `backoff.maxDelayMs` caps this computed backoff delay only; it does not cap explicit `delayMs` values returned by a policy or retry-after hints. |
| `policy` | `RetryPolicy` | Callback that decides whether to retry. This function is runtime-only and is not serialized into persisted run state. |
A retry policy receives a `RetryPolicyContext` with:
* `attempt` and `maxRetries` so you can make attempt-aware decisions.
* `stream` so you can branch between streamed and non-streamed behavior.
* `error` for raw inspection.
* `normalized` facts such as `statusCode`, `retryAfterMs`, `errorCode`, `isNetworkError`, and `isAbort`.
* `providerAdvice` when the underlying model/provider can supply retry guidance.
The policy can return either:
* `true` / `false` for a simple retry decision.
* `{ retry, delayMs?, reason? }` when you want to override the delay or attach a diagnostic reason for logging.
The SDK exports ready-made helpers on `retryPolicies`:
| Helper | Behavior |
| ----------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------- |
| `retryPolicies.never()` | Always opts out. |
| `retryPolicies.providerSuggested()` | Follows provider retry advice when available. |
| `retryPolicies.networkError()` | Matches transient transport/connectivity failures. |
| `retryPolicies.httpStatus([..])` | Matches selected HTTP status codes. |
| `retryPolicies.retryAfter()` | Retries only when a retry-after hint is available, using that hint as an explicit delay that is not capped by `backoff.maxDelayMs`. |
| `retryPolicies.any(...)` | Retries when any nested policy opts in. |
| `retryPolicies.all(...)` | Retries only when every nested policy opts in. |
When you compose policies, `providerSuggested()` is the safest first building block because it preserves provider vetoes and replay-safety approvals when the provider can distinguish them.
#### Safety boundaries
[Section titled “Safety boundaries”](#safety-boundaries)
Some failures are never retried automatically:
* Abort errors.
* Streamed runs after any visible event or raw model event has already been emitted.
* Provider advice that marks replay as unsafe.
Stateful follow-up requests using `previousResponseId` or `conversationId` are also treated more conservatively. For those requests, non-provider predicates such as `networkError()` or `httpStatus([500])` are not enough by themselves. The retry policy must include a replay-safe approval from the provider, typically via `retryPolicies.providerSuggested()`.
#### Runner and agent merge behavior
[Section titled “Runner and agent merge behavior”](#runner-and-agent-merge-behavior)
`retry` is deep-merged between runner-level and agent-level `modelSettings`:
* An agent can override only `retry.maxRetries` and still inherit the runner’s `policy`.
* An agent can override only part of `retry.backoff` and keep sibling backoff fields from the runner.
* If you need to remove an inherited `policy` or `backoff`, set that field to `undefined` explicitly.
See [`examples/basic/retry.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/basic/retry.ts) and [`examples/ai-sdk/retry.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/ai-sdk/retry.ts) for fuller examples with logging.
***
### Prompt
[Section titled “Prompt”](#prompt)
Agents can be configured with a `prompt` parameter, indicating a server-stored prompt configuration that should be used to control the Agent’s behavior. Currently, this option is only supported when you use the OpenAI [Responses API](https://platform.openai.com/docs/api-reference/responses).
`prompt` can be either a static object or a function that returns one at runtime. For the callback shape, see [Dynamic prompts](/openai-agents-js/guides/agents#dynamic-prompts).
| Field | Type | Notes |
| ----------- | -------- | -------------------------------------------------------------------------------------------------------------------------------------- |
| `promptId` | `string` | Unique identifier for a prompt. |
| `version` | `string` | Version of the prompt you wish to use. |
| `variables` | `object` | A key/value pair of variables to substitute into the prompt. Values can be strings or content input types like text, images, or files. |
Agent with prompt
```typescript
import { parseArgs } from 'node:util';
import { Agent, run } from '@openai/agents';
/*
NOTE: This example will not work out of the box, because the default prompt ID will not
be available in your project.
To use it, please:
1. Go to https://platform.openai.com/chat/edit
2. Create a new prompt variable, `poem_style`.
3. Create a system prompt with the content:
Write a poem in {{poem_style}}
4. Run the example with the `--prompt-id` flag.
*/
const DEFAULT_PROMPT_ID =
'pmpt_6965a984c7ac8194a8f4e79b00f838840118c1e58beb3332';
const POEM_STYLES = ['limerick', 'haiku', 'ballad'];
function pickPoemStyle(): string {
return POEM_STYLES[Math.floor(Math.random() * POEM_STYLES.length)];
}
async function runDynamic(promptId: string) {
const poemStyle = pickPoemStyle();
console.log(`[debug] Dynamic poem_style: ${poemStyle}`);
const agent = new Agent({
name: 'Assistant',
prompt: {
promptId,
version: '1',
variables: { poem_style: poemStyle },
},
});
const result = await run(agent, 'Tell me about recursion in programming.');
console.log(result.finalOutput);
}
async function runStatic(promptId: string) {
const agent = new Agent({
name: 'Assistant',
prompt: {
promptId,
version: '1',
variables: { poem_style: 'limerick' },
},
});
const result = await run(agent, 'Tell me about recursion in programming.');
console.log(result.finalOutput);
}
async function main() {
const args = parseArgs({
options: {
dynamic: { type: 'boolean', default: false },
'prompt-id': { type: 'string', default: DEFAULT_PROMPT_ID },
},
});
const promptId = args.values['prompt-id'];
if (!promptId) {
console.error('Please provide a prompt ID via --prompt-id.');
process.exit(1);
}
if (args.values.dynamic) {
await runDynamic(promptId);
} else {
await runStatic(promptId);
}
}
main().catch((error) => {
console.error(error);
process.exit(1);
});
```
Any additional agent configuration, like tools or instructions, will override the values you may have configured in your stored prompt.
When a stored prompt already defines the model, the SDK does not send the agent’s default model unless you explicitly override it. That matters for `computerTool()`: prompt-managed runs keep the legacy preview wire shape by default for compatibility. To opt into the GA Responses computer tool on a prompt-managed run, explicitly set `modelSettings.toolChoice: 'computer'` or send an explicit model such as [`gpt-5.4`](https://developers.openai.com/api/docs/models/gpt-5.4). See [Tools](/openai-agents-js/guides/tools#computer-tool-specifics) for the surrounding computer-use details.
***
## Advanced providers and observability
[Section titled “Advanced providers and observability”](#advanced-providers-and-observability)
### Custom model providers
[Section titled “Custom model providers”](#custom-model-providers)
Implementing your own provider is straightforward – implement `ModelProvider` and `Model` and pass the provider to the `Runner` constructor:
Minimal custom provider
```typescript
import {
ModelProvider,
Model,
ModelRequest,
ModelResponse,
ResponseStreamEvent,
} from '@openai/agents-core';
import { Agent, Runner } from '@openai/agents';
class EchoModel implements Model {
name: string;
constructor() {
this.name = 'Echo';
}
async getResponse(request: ModelRequest): Promise {
return {
usage: {},
output: [{ role: 'assistant', content: request.input as string }],
} as any;
}
async *getStreamedResponse(
_request: ModelRequest,
): AsyncIterable {
yield {
type: 'response.completed',
response: { output: [], usage: {} },
} as any;
}
}
class EchoProvider implements ModelProvider {
getModel(_modelName?: string): Promise | Model {
return new EchoModel();
}
}
const runner = new Runner({ modelProvider: new EchoProvider() });
console.log(runner.config.modelProvider.getModel());
const agent = new Agent({
name: 'Test Agent',
instructions: 'You are a helpful assistant.',
model: new EchoModel(),
modelSettings: { temperature: 0.7, toolChoice: 'auto' },
});
console.log(agent.model);
```
If you want every `run()` call and every newly constructed `Runner` to use the same provider by default, set it once during app startup:
Set a default model provider
```typescript
import { setDefaultModelProvider } from '@openai/agents';
setDefaultModelProvider({
async getModel() {
// Return any Model implementation here.
throw new Error('Provide your own model implementation.');
},
});
```
This is useful when your app standardizes on a non-OpenAI provider and you do not want to pass a custom `Runner` everywhere.
#### AI SDK integration
[Section titled “AI SDK integration”](#ai-sdk-integration)
If you want to use non-OpenAI models without implementing `ModelProvider` yourself, see [Using any model with Vercel’s AI SDK](/openai-agents-js/extensions/ai-sdk). That adapter lets you plug an AI SDK model into the Agents runtime directly, which is useful when your app already standardizes on AI SDK providers or you want access to the wider provider ecosystem. It also documents how Agents SDK `providerData` maps to AI SDK `providerMetadata`, plus the stream helpers available for AI SDK UI routes.
***
### Tracing credentials
[Section titled “Tracing credentials”](#tracing-credentials)
Tracing is already enabled by default in supported server runtimes. Use `setTracingExportApiKey()` only when trace export should use a different credential than the default OpenAI API key:
Set tracing export API key
```typescript
import { setTracingExportApiKey } from '@openai/agents';
setTracingExportApiKey('sk-...');
```
This sends traces to the [OpenAI dashboard](https://platform.openai.com/traces) using that credential. For exporter customization such as custom ingest endpoints or retry tuning, see the [Tracing guide](/openai-agents-js/guides/tracing#openai-tracing-exporter).
***
## Next steps
[Section titled “Next steps”](#next-steps)
* Explore [running agents](/openai-agents-js/guides/running-agents).
* Give your models super‑powers with [tools](/openai-agents-js/guides/tools).
* Add [guardrails](/openai-agents-js/guides/guardrails) or [tracing](/openai-agents-js/guides/tracing) as needed.
# Agent Orchestration
> Coordinate the flow between several agents
Orchestration refers to the flow of agents in your app. Which agents run, in what order, and how do they decide what happens next? There are two main ways to orchestrate agents:
> Read this page after the [Quickstart](/openai-agents-js/guides/quickstart) or the [Agents guide](/openai-agents-js/guides/agents#composition-patterns). This page is about workflow design across multiple agents, not the `Agent` constructor itself.
1. Allowing the LLM to make decisions: this uses the intelligence of an LLM to plan, reason, and decide on what steps to take based on that.
2. Orchestrating via code: determining the flow of agents via your code.
You can mix and match these patterns. Each has their own tradeoffs, described below.
## Orchestrating via LLM
[Section titled “Orchestrating via LLM”](#orchestrating-via-llm)
An agent is an LLM equipped with instructions, tools and handoffs. This means that given an open-ended task, the LLM can autonomously plan how it will tackle the task, using tools to take actions and acquire data, and using handoffs to delegate tasks to sub-agents. For example, a research agent could be equipped with tools like:
* Web search to find information online
* File search and retrieval to search through proprietary data and connections
* Computer use to take actions on a computer
* Code execution to do data analysis
* Handoffs to specialized agents that are great at planning, report writing and more.
### Core SDK patterns
[Section titled “Core SDK patterns”](#core-sdk-patterns)
In the Agents SDK, two orchestration patterns come up most often:
| Pattern | How it works | Best when |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------ | --------------------------------------------------------------------------------------------------------------------------------- |
| Agents as tools | A manager agent keeps control of the conversation and calls specialist agents through `agent.asTool()`. | You want one agent to own the final answer, combine outputs from multiple specialists, or enforce shared guardrails in one place. |
| Handoffs | A triage agent routes the conversation to a specialist, and that specialist becomes the active agent for the rest of the turn. | You want the specialist to speak directly to the user, keep prompts focused, or use different instructions/models per specialist. |
Use **agents as tools** when the specialist should help with a subtask but should not take over the user-facing conversation. The manager stays responsible for deciding which tools to call and how to present the final response. See the [tools guide](/openai-agents-js/guides/tools#agents-as-tools) for the API details, and the [agents guide](/openai-agents-js/guides/agents#composition-patterns) for a side-by-side example.
Use **handoffs** when routing itself is part of the workflow and you want the selected specialist to own the next part of the conversation. The handoff preserves the conversation context while narrowing the active instructions to the specialist. See the [handoffs guide](/openai-agents-js/guides/handoffs) for the API, and the [quickstart](/openai-agents-js/guides/quickstart#define-your-handoffs) for the smallest end-to-end example.
You can combine the two patterns. A triage agent might hand off to a specialist, and that specialist can still use other agents as tools for bounded subtasks.
This pattern is great when the task is open-ended and you want to rely on the intelligence of an LLM. The most important tactics here are:
1. Invest in good prompts. Make it clear what tools are available, how to use them, and what parameters it must operate within.
2. Monitor your app and iterate on it. See where things go wrong, and iterate on your prompts.
3. Allow the agent to introspect and improve. For example, run it in a loop, and let it critique itself; or, provide error messages and let it improve.
4. Have specialized agents that excel in one task, rather than having a general purpose agent that is expected to be good at anything.
5. Invest in [evals](https://platform.openai.com/docs/guides/evals). This lets you train your agents to improve and get better at tasks.
If you want the SDK primitives behind this style of orchestration, start with [tools](/openai-agents-js/guides/tools), [handoffs](/openai-agents-js/guides/handoffs), and [running agents](/openai-agents-js/guides/running-agents).
## Orchestrating via code
[Section titled “Orchestrating via code”](#orchestrating-via-code)
While orchestrating via LLM is powerful, orchestrating via code makes tasks more deterministic and predictable, in terms of speed, cost and performance. Common patterns here are:
* Using [structured outputs](https://developers.openai.com/api/docs/guides/structured-outputs) to generate well formed data that you can inspect with your code. For example, you might ask an agent to classify the task into a few categories, and then pick the next agent based on the category.
* Chaining multiple agents by transforming the output of one into the input of the next. You can decompose a task like writing a blog post into a series of steps - do research, write an outline, write the blog post, critique it, and then improve it.
* Running the agent that performs the task in a `while` loop with an agent that evaluates and provides feedback, until the evaluator says the output passes certain criteria.
* Running multiple agents in parallel, e.g. via JavaScript primitives like `Promise.all`. This is useful for speed when you have multiple tasks that don’t depend on each other.
We have a number of examples in [`examples/agent-patterns`](https://github.com/openai/openai-agents-js/tree/main/examples/agent-patterns).
## Related guides
[Section titled “Related guides”](#related-guides)
* [Agents](/openai-agents-js/guides/agents) for composition patterns and agent configuration.
* [Tools](/openai-agents-js/guides/tools#agents-as-tools) for `agent.asTool()` and manager-style orchestration.
* [Handoffs](/openai-agents-js/guides/handoffs) for delegation between specialist agents.
* [Running Agents](/openai-agents-js/guides/running-agents) for `Runner` and per-run orchestration controls.
* [Quickstart](/openai-agents-js/guides/quickstart) for a minimal end-to-end handoff example.
# Quickstart
> Create your first AI Agent from scratch
Looking for sandbox agents?
This quickstart builds a text agent that runs in your app process. If you want an agent with an isolated filesystem workspace, shell commands, and sandbox session state, start with the [Sandbox agents quickstart](/openai-agents-js/guides/sandbox-agents).
## Project Setup
[Section titled “Project Setup”](#project-setup)
1. Create a project and initialize npm. You’ll only need to do this once.
```bash
mkdir my_project
cd my_project
npm init -y
```
2. Install the Agents SDK and Zod. The SDK uses Zod v4 for tool schemas and structured outputs.
```bash
npm install @openai/agents zod
```
3. Set an OpenAI API key. If you don’t have one, follow [these instructions](https://platform.openai.com/docs/quickstart#create-and-export-an-api-key) to create an OpenAI API key.
```bash
export OPENAI_API_KEY=sk-...
```
Alternatively you can call `setDefaultOpenAIKey('')` to set the key programmatically and use `setTracingExportApiKey('')` for tracing. See [the config guide](/openai-agents-js/guides/config) for more details.
## Create your first agent
[Section titled “Create your first agent”](#create-your-first-agent)
Agents are defined with instructions and a name.
Create an agent
```typescript
import { Agent } from '@openai/agents';
const agent = new Agent({
name: 'History Tutor',
instructions:
'You provide assistance with historical queries. Explain important events and context clearly.',
});
```
## Run your first agent
[Section titled “Run your first agent”](#run-your-first-agent)
You can use the `run` method to run your agent. You trigger a run by passing both the agent you want to start on and the input you want to pass in.
This will return a result that contains the final output and any actions that were performed during that run.
Run an agent
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'History Tutor',
instructions:
'You provide assistance with historical queries. Explain important events and context clearly.',
});
const result = await run(agent, 'When did sharks first appear?');
console.log(result.finalOutput);
```
For a second turn, you can either pass `result.history` back into `run()`, attach a [session](/openai-agents-js/guides/sessions), or reuse OpenAI server-managed state with `conversationId` / `previousResponseId`. The [running agents](/openai-agents-js/guides/running-agents) guide compares these approaches.
## Give your agent tools
[Section titled “Give your agent tools”](#give-your-agent-tools)
You can give an agent tools to use to look up information or perform actions.
Add a tool
```typescript
import { Agent, tool } from '@openai/agents';
import { z } from 'zod';
const historyFunFact = tool({
// The name of the tool will be used by the agent to tell what tool to use.
name: 'history_fun_fact',
// The description is used to describe when to use the tool by telling it what it does.
description: 'Give a fun fact about a historical event',
// This tool takes no parameters, so we provide an empty Zod object.
parameters: z.object({}),
execute: async () => {
// The output will be returned back to the agent to use.
return 'Sharks are older than trees.';
},
});
const agent = new Agent({
name: 'History Tutor',
instructions:
'You provide assistance with historical queries. Explain important events and context clearly.',
// Add the tool to the agent.
tools: [historyFunFact],
});
```
## Add a few more agents
[Section titled “Add a few more agents”](#add-a-few-more-agents)
Additional agents can be defined similarly to break down problems into smaller parts and have your agent be more focused on the task at hand. It also allows you to use different models for different problems by defining the model on the agent.
Create specialist agents
```typescript
import { Agent } from '@openai/agents';
const historyTutorAgent = new Agent({
name: 'History Tutor',
instructions:
'You provide assistance with historical queries. Explain important events and context clearly.',
});
const mathTutorAgent = new Agent({
name: 'Math Tutor',
instructions:
'You provide help with math problems. Explain your reasoning at each step and include examples',
});
```
## Define your handoffs
[Section titled “Define your handoffs”](#define-your-handoffs)
In order to orchestrate between multiple agents, you can define `handoffs` for an agent. This will enable the agent to pass the conversation on to the next agent. This will happen automatically during the course of a run.
Define handoffs
```typescript
import { Agent } from '@openai/agents';
const historyTutorAgent = new Agent({
name: 'History Tutor',
instructions:
'You provide assistance with historical queries. Explain important events and context clearly.',
});
const mathTutorAgent = new Agent({
name: 'Math Tutor',
instructions:
'You provide help with math problems. Explain your reasoning at each step and include examples',
});
// Use Agent.create() to keep handoff output types aligned.
const triageAgent = Agent.create({
name: 'Triage Agent',
instructions:
"You determine which agent to use based on the user's homework question",
handoffs: [historyTutorAgent, mathTutorAgent],
});
```
After your run you can see which agent generated the final response by looking at the `lastAgent` property on the result.
## Run the agent orchestration
[Section titled “Run the agent orchestration”](#run-the-agent-orchestration)
The runner handles executing individual agents, any handoffs, and any tool calls.
Run agent orchestration
```typescript
import { Agent, run } from '@openai/agents';
const historyTutorAgent = new Agent({
name: 'History Tutor',
instructions:
'You provide assistance with historical queries. Explain important events and context clearly.',
});
const mathTutorAgent = new Agent({
name: 'Math Tutor',
instructions:
'You provide help with math problems. Explain your reasoning at each step and include examples',
});
const triageAgent = Agent.create({
name: 'Triage Agent',
instructions:
"You determine which agent to use based on the user's homework question",
handoffs: [historyTutorAgent, mathTutorAgent],
});
async function main() {
const result = await run(triageAgent, 'What is the capital of France?');
console.log(result.finalOutput);
}
main().catch((err) => console.error(err));
```
## Putting it all together
[Section titled “Putting it all together”](#putting-it-all-together)
Let’s put it all together into one full example. Place this into your `index.js` file and run it. If your app is already set up for TypeScript, you can use `index.ts` instead.
Quickstart
```typescript
import { Agent, run } from '@openai/agents';
const historyTutorAgent = new Agent({
name: 'History Tutor',
instructions:
'You provide assistance with historical queries. Explain important events and context clearly.',
});
const mathTutorAgent = new Agent({
name: 'Math Tutor',
instructions:
'You provide help with math problems. Explain your reasoning at each step and include examples',
});
const triageAgent = Agent.create({
name: 'Triage Agent',
instructions:
"You determine which agent to use based on the user's homework question",
handoffs: [historyTutorAgent, mathTutorAgent],
});
async function main() {
const result = await run(triageAgent, 'What is the capital of France?');
console.log(result.finalOutput);
}
main().catch((err) => console.error(err));
```
## View your traces
[Section titled “View your traces”](#view-your-traces)
The Agents SDK will automatically generate traces for you. This allows you to review how your agents are operating, what tools they called or which agent they handed off to.
To review what happened during your agent run, navigate to the [Trace viewer in the OpenAI Dashboard](https://platform.openai.com/traces).
## Next steps
[Section titled “Next steps”](#next-steps)
Learn how to build more complex agentic flows:
* Learn about configuring [Agents](/openai-agents-js/guides/agents).
* Learn about [running agents](/openai-agents-js/guides/running-agents) and [sessions](/openai-agents-js/guides/sessions).
* Learn about [tools](/openai-agents-js/guides/tools), [guardrails](/openai-agents-js/guides/guardrails), and [models](/openai-agents-js/guides/models).
# Release process
> Learn how we version and release the SDK and recent changes.
## Versioning
[Section titled “Versioning”](#versioning)
The project follows a slightly modified version of semantic versioning using the form `0.Y.Z`. The leading `0` indicates the SDK is still evolving rapidly. Increment the components as follows:
## Minor (`Y`) versions
[Section titled “Minor (Y) versions”](#minor-y-versions)
We will increase minor versions `Y` for **breaking changes** to any public interfaces that are not marked as beta. For example, going from `0.0.x` to `0.1.x` might include breaking changes.
If you don’t want breaking changes, we recommend pinning to `0.0.x` versions in your project.
## Patch (`Z`) versions
[Section titled “Patch (Z) versions”](#patch-z-versions)
We will increment `Z` for non-breaking changes:
* Bug fixes
* New features
* Changes to private interfaces
* Updates to beta features
## Versioning sub-packages
[Section titled “Versioning sub-packages”](#versioning-sub-packages)
The main `@openai/agents` package is comprised of multiple sub-packages that can be used independently. At the moment the versions of the packages are linked, meaning if one package receives a version increase, so do the others. We might change this strategy as we move to `1.0.0`.
## Changelogs
[Section titled “Changelogs”](#changelogs)
We generate changelogs for each of the sub-packages to help understand what has changed. As the changes might have happened in a sub-package, you might have to look in that respective changelog for details on the change.
* [`@openai/agents`](https://github.com/openai/openai-agents-js/blob/main/packages/agents/CHANGELOG.md)
* [`@openai/agents-core`](https://github.com/openai/openai-agents-js/blob/main/packages/agents-core/CHANGELOG.md)
* [`@openai/agents-extensions`](https://github.com/openai/openai-agents-js/blob/main/packages/agents-extensions/CHANGELOG.md)
* [`@openai/agents-openai`](https://github.com/openai/openai-agents-js/blob/main/packages/agents-openai/CHANGELOG.md)
* [`@openai/agents-realtime`](https://github.com/openai/openai-agents-js/blob/main/packages/agents-realtime/CHANGELOG.md)
# Results
> Learn how to access the results and output from your agent run
When you [run your agent](/openai-agents-js/guides/running-agents), you will either receive a:
* [`RunResult`](/openai-agents-js/openai/agents/classes/runresult) if you call `run` without `stream: true`
* [`StreamedRunResult`](/openai-agents-js/openai/agents/classes/streamedrunresult) if you call `run` with `stream: true`. For details on streaming, also check the [streaming guide](/openai-agents-js/guides/streaming).
Both result types expose the same core result surfaces such as `finalOutput`, `newItems`, `interruptions`, and `state`. `StreamedRunResult` adds streaming controls like `completed`, `toStream()`, `toTextStream()`, and `currentAgent`.
## Choose the right result surface
[Section titled “Choose the right result surface”](#choose-the-right-result-surface)
Most applications only need a few properties:
| If you need… | Use |
| --------------------------------------------------------------------------------------------------------- | ---------------------------------------------- |
| The final answer to show the user | `finalOutput` |
| A replay-ready next-turn input with the full local transcript | `history` |
| Only the newly generated model-shaped items from this run | `output` |
| Rich run items with agent/tool/handoff metadata | `newItems` |
| The agent that should usually handle the next user turn | `lastAgent` or `activeAgent` |
| OpenAI Responses API chaining with `previousResponseId` | `lastResponseId` |
| Pending approvals and a resumable snapshot | `interruptions` and `state` |
| App context, approvals, usage, and nested agent-tool input | `runContext` |
| Metadata about the current nested `Agent.asTool()` invocation, for example inside `customOutputExtractor` | `agentToolInvocation` |
| Raw model calls or guardrail diagnostics | `rawResponses` and the guardrail result arrays |
## Final output
[Section titled “Final output”](#final-output)
The `finalOutput` property contains the final output of the last agent that ran. This result is either:
* `string` — default for any agent that has no `outputType` defined
* `unknown` — if the agent has a JSON schema defined as output type. In this case the JSON was parsed but you still have to verify its type manually.
* `z.infer` — if the agent has a Zod schema defined as output type. The output will automatically be parsed against this schema.
* `undefined` — if the agent did not produce an output (for example stopped before it could produce an output)
`finalOutput` is also `undefined` while a streamed run is still in progress or when the run paused on an approval interruption before reaching a final output.
If you are using handoffs with different output types, you should use the `Agent.create()` method instead of the `new Agent()` constructor to create your agents.
This will enable the SDK to infer the output types across all possible handoffs and provide a union type for the `finalOutput` property.
For example:
Handoff final output types
```typescript
import { Agent, run } from '@openai/agents';
import { z } from 'zod';
const refundAgent = new Agent({
name: 'Refund Agent',
instructions:
'You are a refund agent. You are responsible for refunding customers.',
outputType: z.object({
refundApproved: z.boolean(),
}),
});
const orderAgent = new Agent({
name: 'Order Agent',
instructions:
'You are an order agent. You are responsible for processing orders.',
outputType: z.object({
orderId: z.string(),
}),
});
const triageAgent = Agent.create({
name: 'Triage Agent',
instructions:
'You are a triage agent. You are responsible for triaging customer issues.',
handoffs: [refundAgent, orderAgent],
});
const result = await run(triageAgent, 'I need to a refund for my order');
const output = result.finalOutput;
// ^? { refundApproved: boolean } | { orderId: string } | string | undefined
```
## Input and output surfaces
[Section titled “Input and output surfaces”](#input-and-output-surfaces)
These properties answer different questions:
| Property | What it contains | Best for |
| ---------- | ------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------- |
| `input` | The base input for this run. If a handoff input filter rewrote the history, this reflects the filtered input the run continued with. | Auditing what this run actually used as input |
| `output` | Only the model-shaped items generated in this run, without agent metadata. | Storing or replaying just the new model delta |
| `newItems` | Rich [`RunItem`](/openai-agents-js/openai/agents/type-aliases/runitem) wrappers with agent/tool/handoff metadata. | Logs, UIs, audits, and debugging |
| `history` | A replay-ready next-turn input built from `input + newItems`. | Manual chat loops and client-managed conversation state |
In practice:
* Use `history` when you are manually carrying the whole conversation in your application.
* Use `output` when you already store prior history elsewhere and only want the new generated items from this run.
* Use `newItems` when you need agent associations, tool outputs, handoff boundaries, or approval items.
* If you are using `conversationId` or `previousResponseId`, you usually do not pass `history` back into `run()`. Instead, pass only the new user input and reuse the server-managed ID. See [Running agents](/openai-agents-js/guides/running-agents#state-and-conversation-management) for the full comparison.
`history` is a convenient way to maintain a full history in a chat-like use case:
History loop
```typescript
import { Agent, user, run } from '@openai/agents';
import type { AgentInputItem } from '@openai/agents';
const agent = new Agent({
name: 'Assistant',
instructions:
'You are a helpful assistant knowledgeable about recent AGI research.',
});
let history: AgentInputItem[] = [
// initial message
user('Are we there yet?'),
];
for (let i = 0; i < 10; i++) {
// run 10 times
const result = await run(agent, history);
// update the history to the new output
history = result.history;
history.push(user('How about now?'));
}
```
## New items
[Section titled “New items”](#new-items)
`newItems` gives you the richest view of what happened during the run. Common item types are:
* [`RunMessageOutputItem`](/openai-agents-js/openai/agents/classes/runmessageoutputitem) for assistant messages.
* [`RunReasoningItem`](/openai-agents-js/openai/agents/classes/runreasoningitem) for reasoning items.
* [`RunToolSearchCallItem`](/openai-agents-js/openai/agents/classes/runtoolsearchcallitem) and [`RunToolSearchOutputItem`](/openai-agents-js/openai/agents/classes/runtoolsearchoutputitem) for Responses tool-search requests and the loaded tool definitions they return.
* [`RunToolCallItem`](/openai-agents-js/openai/agents/classes/runtoolcallitem) and [`RunToolCallOutputItem`](/openai-agents-js/openai/agents/classes/runtoolcalloutputitem) for tool calls and their results.
* [`RunToolApprovalItem`](/openai-agents-js/openai/agents/classes/runtoolapprovalitem) for tool calls that paused for approval.
* [`RunHandoffCallItem`](/openai-agents-js/openai/agents/classes/runhandoffcallitem) and [`RunHandoffOutputItem`](/openai-agents-js/openai/agents/classes/runhandoffoutputitem) for handoff requests and completed transfers.
Choose `newItems` over `output` whenever you need to know which agent produced an item or whether it marks a tool, tool-search, handoff, or approval boundary. When you use `toolSearchTool()`, these tool-search items are the easiest way to inspect which deferred tools or namespaces were loaded before the normal tool call happened.
## Continue or resume the conversation
[Section titled “Continue or resume the conversation”](#continue-or-resume-the-conversation)
### Active agent
[Section titled “Active agent”](#active-agent)
The `lastAgent` property contains the last agent that ran. This is often the best agent to reuse for the next user turn after handoffs. `activeAgent` is an alias for the same value.
In streaming mode, `currentAgent` tells you which agent is currently active while the run is still in progress.
### Interruptions and resumable state
[Section titled “Interruptions and resumable state”](#interruptions-and-resumable-state)
If a tool needs approval, the run pauses and `interruptions` contains the pending [`RunToolApprovalItem`](/openai-agents-js/openai/agents/classes/runtoolapprovalitem)s. This can include approvals raised by direct tools, by tools reached after a handoff, or by nested `agent.asTool()` runs.
Resolve approvals through `result.state.approve(...)` / `result.state.reject(...)`, then pass the same `state` back into `run()` to resume. You do not need to resolve every interruption at once. If you rerun after handling only some items, resolved calls can continue while unresolved ones stay pending and pause the run again.
The `state` property is the serializable snapshot behind the result. Use it for [human-in-the-loop](/openai-agents-js/guides/human-in-the-loop), retry flows, or any case where you need to resume a paused run later.
### Server-managed continuation
[Section titled “Server-managed continuation”](#server-managed-continuation)
`lastResponseId` is the value to pass as `previousResponseId` on the next turn when you are using OpenAI Responses API chaining.
If you are already continuing the conversation with `history`, `session`, or `conversationId`, you usually do not need `lastResponseId`. If you need every raw model response from a multi-step run, inspect `rawResponses` instead.
## Nested agent-tool metadata
[Section titled “Nested agent-tool metadata”](#nested-agent-tool-metadata)
`agentToolInvocation` is for nested `Agent.asTool()` results, especially when you are inside `customOutputExtractor` and want metadata about the current tool invocation. It is not a general “the whole run has finished” summary field.
In that nested context, `agentToolInvocation` exposes:
* `toolName`
* `toolCallId`
* `toolArguments`
Pair it with `result.runContext.toolInput` when you also need the structured input passed into that nested agent-tool run.
On normal top-level `run()` results this is usually `undefined`. The metadata is runtime-only and is not serialized into `RunState`. See [Agents as tools](/openai-agents-js/guides/tools#4-agents-as-tools) for the surrounding pattern.
## Streamed results
[Section titled “Streamed results”](#streamed-results)
`StreamedRunResult` inherits the same result surfaces above, but adds streaming-specific controls:
* `toTextStream()` for assistant text only.
* `toStream()` or `for await ... of stream` for the full event stream.
* `completed` to wait until the run and all post-processing callbacks finish.
* `error` and `cancelled` to inspect the terminal streaming state.
* `currentAgent` to track the active agent mid-run.
If you need the settled final state of a streamed run, wait for `completed` before reading `finalOutput`, `history`, `interruptions`, or other summary properties. For event-by-event handling, see the [streaming guide](/openai-agents-js/guides/streaming).
If a streamed run is cancelled, `completed` still resolves after cleanup and `cancelled` becomes `true`, but turn-end fields such as `finalOutput` can remain unset because the current turn never finished. Resume that unfinished turn with `result.state` (and the same `session`, if you use one) instead of appending a fresh user message.
## Diagnostics and advanced fields
[Section titled “Diagnostics and advanced fields”](#diagnostics-and-advanced-fields)
### Run context
[Section titled “Run context”](#run-context)
The `runContext` property is the supported public view of the run context on the result. `result.runContext.context` is your app context, and the same object also carries SDK-managed runtime metadata such as approvals, usage, and nested `toolInput`. See [Context](/openai-agents-js/guides/context) for the full shape.
### Raw responses
[Section titled “Raw responses”](#raw-responses)
`rawResponses` contains the raw model responses collected during the run. Multi-step runs can produce more than one response, for example across handoffs or repeated tool/model cycles.
### Guardrail results
[Section titled “Guardrail results”](#guardrail-results)
The `inputGuardrailResults` and `outputGuardrailResults` properties contain agent-level guardrail results. Tool guardrail results are exposed separately via `toolInputGuardrailResults` and `toolOutputGuardrailResults`.
Use these arrays when you want to log guardrail decisions, inspect extra metadata returned by guardrail functions, or debug why a run was blocked.
### Usage
[Section titled “Usage”](#usage)
Token usage is aggregated in `result.state.usage`, which tracks request counts and token totals for the run. The same usage object is also available through `result.runContext.usage`. For streaming runs this data updates as responses arrive.
Read usage from RunState
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Usage Tracker',
instructions: 'Summarize the latest project update in one sentence.',
});
const result = await run(
agent,
'Summarize this: key customer feedback themes and the next product iteration.',
);
const usage = result.state.usage;
console.log({
requests: usage.requests,
inputTokens: usage.inputTokens,
outputTokens: usage.outputTokens,
totalTokens: usage.totalTokens,
});
if (usage.requestUsageEntries) {
for (const entry of usage.requestUsageEntries) {
console.log('request', {
endpoint: entry.endpoint,
inputTokens: entry.inputTokens,
outputTokens: entry.outputTokens,
totalTokens: entry.totalTokens,
});
}
}
```
# Running Agents
> Configure and execute agent workflows with the Runner class
Agents do nothing by themselves – you **run** them with the `Runner` class or the `run()` utility.
> Read this page after [Agents](/openai-agents-js/guides/agents) once you want to execute turns, stream events, or manage conversation state. If you are still deciding how the agent should be defined, start with [Agents](/openai-agents-js/guides/agents) first.
Simple run
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Assistant',
instructions: 'You are a helpful assistant',
});
const result = await run(
agent,
'Write a haiku about recursion in programming.',
);
console.log(result.finalOutput);
// Code within the code,
// Functions calling themselves,
// Infinite loop's dance.
```
When you don’t need a custom runner, you can also use the `run()` utility, which runs a singleton default `Runner` instance.
Alternatively, you can create your own runner instance:
Simple run
```typescript
import { Agent, Runner } from '@openai/agents';
const agent = new Agent({
name: 'Assistant',
instructions: 'You are a helpful assistant',
});
// You can pass custom configuration to the runner
const runner = new Runner();
const result = await runner.run(
agent,
'Write a haiku about recursion in programming.',
);
console.log(result.finalOutput);
// Code within the code,
// Functions calling themselves,
// Infinite loop's dance.
```
After running your agent, you will receive a [result](/openai-agents-js/guides/results) object that contains the final output and the full history of the run.
## Runner lifecycle and configuration
[Section titled “Runner lifecycle and configuration”](#runner-lifecycle-and-configuration)
### The agent loop
[Section titled “The agent loop”](#the-agent-loop)
When you use the run method in Runner, you pass in a starting agent and input. The input can either be a string (which is considered a user message), or a list of input items, which are the items in the OpenAI Responses API.
The runner then runs a loop:
1. Call the current agent’s model with the current input.
2. Inspect the LLM response.
* **Final output** → return.
* **Handoff** → switch to the new agent, keep the accumulated conversation history, go to 1.
* **Tool calls** → execute tools, append their results to the conversation, go to 1.
3. Throw [`MaxTurnsExceededError`](/openai-agents-js/openai/agents-core/classes/maxturnsexceedederror) once `maxTurns` is reached, unless `maxTurns` is `null`.
Note
The rule for whether the LLM output is considered as a “final output” is that it produces text output with the desired type, and there are no tool calls.
#### Runner lifecycle
[Section titled “Runner lifecycle”](#runner-lifecycle)
Create a `Runner` when your app starts and reuse it across requests. The instance stores global configuration such as model provider and tracing options. Only create another `Runner` if you need a completely different setup. For simple scripts you can also call `run()` which uses a default runner internally.
### Run arguments
[Section titled “Run arguments”](#run-arguments)
The input to the `run()` method is an initial agent to start the run on, input for the run and a set of options.
The input can either be a string (which is considered a user message), or a list of [input items](/openai-agents-js/openai/agents-core/type-aliases/agentinputitem), or a [`RunState`](/openai-agents-js/openai/agents-core/classes/runstate) object in case you are building a [human-in-the-loop](/openai-agents-js/guides/human-in-the-loop) agent.
The additional options are:
| Option | Default | Description |
| ----------------------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `stream` | `false` | If `true` the call returns a `StreamedRunResult` and emits events as they arrive from the model. |
| `context` | – | Context object forwarded to every tool / guardrail / handoff. Learn more in the [context guide](/openai-agents-js/guides/context). |
| `maxTurns` | `10` | Safety limit – throws [`MaxTurnsExceededError`](/openai-agents-js/openai/agents-core/classes/maxturnsexceedederror) when reached. Pass `null` to disable the limit. |
| `signal` | – | `AbortSignal` for cancellation. |
| `session` | – | Session persistence implementation. See the [sessions guide](/openai-agents-js/guides/sessions). |
| `sessionInputCallback` | – | Custom merge logic for session history and new input; runs before the model call. See [sessions](/openai-agents-js/guides/sessions). |
| `callModelInputFilter` | – | Hook to edit the model input (items + optional instructions) just before calling the model. See [Call model input filter](#call-model-input-filter). |
| `toolErrorFormatter` | – | Hook to customize tool approval rejection messages returned to the model. See [Tool error formatter](#tool-error-formatter). |
| `reasoningItemIdPolicy` | – | Controls whether reasoning-item `id`s are preserved or omitted when prior run items are turned back into model input. See [Reasoning item ID policy](#reasoning-item-id-policy). |
| `tracing` | – | Per-run tracing configuration overrides (for example, export API key). |
| `sandbox` | – | Sandbox client, live session, session state, snapshot, manifest override, or concurrency limits for `SandboxAgent` runs. See [Sandbox agents](/openai-agents-js/guides/sandbox-agents/concepts). |
| `toolExecution` | – | SDK-side execution settings for local tool calls. Use `toolExecution.maxFunctionToolConcurrency` to limit how many function tools run at once. |
| `errorHandlers` | – | Handlers for supported runtime errors (currently `maxTurns`). See [Error handlers](#error-handlers). |
| `conversationId` | – | Reuse a server-side conversation (OpenAI Responses API + Conversations API only). |
| `previousResponseId` | – | Continue from the previous Responses API call without creating a conversation (OpenAI Responses API only). |
### Streaming
[Section titled “Streaming”](#streaming)
Streaming allows you to additionally receive streaming events as the LLM runs. Once the stream is started, the `StreamedRunResult` will contain the complete information about the run, including all the new outputs produces. You can iterate over the streaming events using a `for await` loop. Read more in the [streaming guide](/openai-agents-js/guides/streaming).
### Run config
[Section titled “Run config”](#run-config)
If you are creating your own `Runner` instance, you can pass in a `RunConfig` object to configure the runner.
| Field | Type | Purpose |
| --------------------------- | ------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `model` | `string \| Model` | Force a specific model for **all** agents in the run. |
| `modelProvider` | `ModelProvider` | Resolves model names – defaults to the OpenAI provider. |
| `modelSettings` | `ModelSettings` | Global tuning parameters that override per‑agent settings. See the [models guide](/openai-agents-js/guides/models#modelsettings) for details, including opt-in retry configuration. |
| `handoffInputFilter` | `HandoffInputFilter` | Mutates input items when performing handoffs (if the handoff itself doesn’t already define one). |
| `inputGuardrails` | `InputGuardrail[]` | Guardrails applied to the *initial* user input. |
| `outputGuardrails` | `OutputGuardrail[]` | Guardrails applied to the *final* output. |
| `tracingDisabled` | `boolean` | Disable OpenAI Tracing completely. |
| `traceIncludeSensitiveData` | `boolean` | Exclude LLM/tool inputs & outputs from traces while still emitting spans. |
| `workflowName` | `string` | Appears in the Traces dashboard – helps group related runs. |
| `traceId` / `groupId` | `string` | Manually specify the trace or group ID instead of letting the SDK generate one. |
| `traceMetadata` | `Record` | Arbitrary metadata to attach to every span. |
| `tracing` | `TracingConfig` | Per-run tracing overrides (for example, export API key). |
| `sessionInputCallback` | `SessionInputCallback` | Default history merge strategy for all runs on this runner. |
| `callModelInputFilter` | `CallModelInputFilter` | Global hook to edit model inputs before each model call. |
| `toolErrorFormatter` | `ToolErrorFormatter` | Global hook to customize tool approval rejection messages returned to the model. |
| `reasoningItemIdPolicy` | `ReasoningItemIdPolicy` | Default policy for preserving or omitting reasoning-item `id`s when replaying generated items into later model calls. |
| `sandbox` | `SandboxRunConfig` | Default sandbox runtime configuration for `SandboxAgent` runs. |
| `toolExecution` | `ToolExecutionConfig` | Default SDK-side execution settings for local tool calls. `maxFunctionToolConcurrency` caps local function tool concurrency for each turn; unset or `null` starts all function tool calls emitted in a turn. |
`toolExecution.maxFunctionToolConcurrency` must be an integer greater than or equal to `1`. This setting only limits SDK-side execution of local function tools. It does not change provider-side `modelSettings.parallelToolCalls`.
## State and conversation management
[Section titled “State and conversation management”](#state-and-conversation-management)
### Choose one memory strategy
[Section titled “Choose one memory strategy”](#choose-one-memory-strategy)
There are four common ways to carry state into the next turn:
| Strategy | Where state lives | Best for | What you pass on the next turn |
| -------------------- | ------------------------- | ------------------------------------------------------------------------ | ----------------------------------------------------- |
| `result.history` | Your app memory | Small chat loops, full manual control, any provider | `result.history` |
| `session` | Your storage + the SDK | Persistent chat state, resumable runs, custom stores | The same `session` instance (or a store-backed one) |
| `conversationId` | OpenAI Conversations API | Shared server-side state across workers/services | The same `conversationId` plus only the new user turn |
| `previousResponseId` | OpenAI Responses API only | The simplest server-managed continuation without creating a conversation | `result.lastResponseId` plus only the new user turn |
`result.history` and `session` are client-managed. `conversationId` and `previousResponseId` are OpenAI-managed and only apply when you are using the OpenAI Responses API. In most applications, pick one persistence strategy per conversation. Mixing client-managed history with server-managed state can duplicate context unless you are deliberately reconciling both layers.
Sandbox agents add another state layer: the live sandbox workspace. Use the regular SDK `session`, `conversationId`, or `previousResponseId` for conversation history, and use `sandbox.session`, `sandbox.sessionState`, `RunState`, or snapshots for sandbox filesystem state. See [Sandbox agents](/openai-agents-js/guides/sandbox-agents/concepts) for the workspace lifecycle.
### Conversations / chat threads
[Section titled “Conversations / chat threads”](#conversations--chat-threads)
Each call to `runner.run()` (or `run()` utility) represents one **turn** in your application-level conversation. You choose how much of the `RunResult` you show the end‑user – sometimes only `finalOutput`, other times every generated item.
Example of carrying over the conversation history
```typescript
import { Agent, run } from '@openai/agents';
import type { AgentInputItem } from '@openai/agents';
let thread: AgentInputItem[] = [];
const agent = new Agent({
name: 'Assistant',
});
async function userSays(text: string) {
const result = await run(
agent,
thread.concat({ role: 'user', content: text }),
);
thread = result.history; // Carry over history + newly generated items
return result.finalOutput;
}
await userSays('What city is the Golden Gate Bridge in?');
// -> "San Francisco"
await userSays('What state is it in?');
// -> "California"
```
See [the chat example](https://github.com/openai/openai-agents-js/tree/main/examples/basic/chat.ts) for an interactive version.
#### Server-managed conversations
[Section titled “Server-managed conversations”](#server-managed-conversations)
You can let the OpenAI Responses API persist conversation history for you instead of sending your entire local conversation history on every turn. This is useful when you are coordinating long conversations or multiple services. With either server-managed approach below, pass only the new turn’s input on each request. The API reuses prior state for you. See the [Conversation state guide](https://developers.openai.com/api/docs/guides/conversation-state) for details.
OpenAI exposes two ways to reuse server-side state:
##### 1. `conversationId` for an entire conversation
[Section titled “1. conversationId for an entire conversation”](#1-conversationid-for-an-entire-conversation)
You can create a conversation once using [Conversations API](https://platform.openai.com/docs/api-reference/conversations/create) and then reuse its ID for every turn. The SDK automatically includes only the newly generated items.
Reusing a server conversation
```typescript
import { Agent, run } from '@openai/agents';
import { OpenAI } from 'openai';
const agent = new Agent({
name: 'Assistant',
instructions: 'Reply very concisely.',
});
async function main() {
// Create a server-managed conversation:
const client = new OpenAI();
const { id: conversationId } = await client.conversations.create({});
const first = await run(agent, 'What city is the Golden Gate Bridge in?', {
conversationId,
});
console.log(first.finalOutput);
// -> "San Francisco"
const second = await run(agent, 'What state is it in?', { conversationId });
console.log(second.finalOutput);
// -> "California"
}
main().catch(console.error);
```
##### 2. `previousResponseId` to continue from the last turn
[Section titled “2. previousResponseId to continue from the last turn”](#2-previousresponseid-to-continue-from-the-last-turn)
If you want to start only with Responses API anyway, you can chain each request using the ID returned from the previous response. This keeps the context alive across turns without creating a full conversation resource.
Chaining with previousResponseId
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Assistant',
instructions: 'Reply very concisely.',
});
async function main() {
const first = await run(agent, 'What city is the Golden Gate Bridge in?');
console.log(first.finalOutput);
// -> "San Francisco"
const previousResponseId = first.lastResponseId;
const second = await run(agent, 'What state is it in?', {
previousResponseId,
});
console.log(second.finalOutput);
// -> "California"
}
main().catch(console.error);
```
`conversationId` and `previousResponseId` are mutually exclusive. Use `conversationId` when you want a named conversation resource you can share across systems, and `previousResponseId` when you just want the cheapest SDK-level continuation primitive from one response to the next.
## Hooks and customization
[Section titled “Hooks and customization”](#hooks-and-customization)
### Call model input filter
[Section titled “Call model input filter”](#call-model-input-filter)
Use `callModelInputFilter` to edit the model input *right before* the model is called. This hook receives the current agent, context, and the combined input items (including session history when present). Return the updated `input` array and optional `instructions` to redact sensitive data, drop old messages, or inject additional system guidance.
Set it per run in `runner.run(..., { callModelInputFilter })` or as a default in the `Runner` config (`callModelInputFilter` in `RunConfig`).
The return value must be a `ModelInputData` object: `{ input: AgentInputItem[], instructions? }`. The `input` field is required and must be an array. Returning any other shape throws a `UserError`.
The SDK clones the prepared turn input before invoking the filter. If you are also using a `session`, the filtered clones are what get persisted, so redaction or truncation applied here is reflected in stored session history as well.
With `conversationId` or `previousResponseId`, the hook runs on the prepared payload for the next Responses API call. Prior server-managed context is recovered by the API, so the filtered array for that call may already represent only the new turn delta rather than a full replay of earlier history. If you need to change how stored history and the current turn are merged before this final filter step, use `sessionInputCallback`.
### Tool error formatter
[Section titled “Tool error formatter”](#tool-error-formatter)
Use `toolErrorFormatter` to customize approval-rejection messages that are sent back to the model when a tool call is rejected. This lets you return domain-specific wording (for example, compliance guidance) instead of the SDK default message.
The formatter can be set per-run (`runner.run(..., { toolErrorFormatter })`) or globally in `RunConfig` (`toolErrorFormatter` in `new Runner(...)`).
This formatter is the global fallback for approval rejections. If you reject a specific interruption with `result.state.reject(interruption, { message: '...' })`, that per-call `message` takes precedence over `toolErrorFormatter`. If neither is provided, the SDK falls back to the default rejection text: `Tool execution was not approved.`
The formatter currently runs for `approval_rejected` events and receives:
* `kind` (currently always `'approval_rejected'`)
* `toolType` (`'function'`, `'computer'`, `'shell'`, or `'apply_patch'`)
* `toolName`
* `callId`
* `defaultMessage` (the SDK fallback message, currently `Tool execution was not approved.`)
* `runContext`
Return a string to override the message, or return `undefined` to keep the SDK default. If the formatter throws (or returns a non-string value), the SDK logs a warning and falls back to the default approval-rejection message.
### Reasoning item ID policy
[Section titled “Reasoning item ID policy”](#reasoning-item-id-policy)
Use `reasoningItemIdPolicy` to control whether reasoning items keep their `id` fields when the SDK converts previously generated run items back into `AgentInputItem[]` for later model input.
This affects places where the SDK replays generated model items as input, such as:
* follow-up model calls inside the same run (for example, after tool execution),
* subsequent turns that reuse generated items as input/history,
* resumed runs from a saved `RunState`,
* derived result views like `result.history` / `result.output` (which are model-input-shaped arrays).
* `'preserve'` (default) keeps reasoning-item IDs.
* `'omit'` strips the `id` field from reasoning items before they are sent back as input.
* Non-reasoning items are unaffected.
What this does **not** change:
* raw model responses (`result.rawResponses`),
* run items (`result.newItems`),
* the model’s current-turn output as returned by the provider.
In other words, the policy applies when the SDK builds the **next input** from prior generated items.
You can set the policy per run (`runner.run(..., { reasoningItemIdPolicy: 'omit' })`) or as the runner default (`new Runner({ reasoningItemIdPolicy: 'omit', ... })`). When resuming from a saved `RunState`, the previously resolved policy is reused unless you override it.
#### Interaction with `callModelInputFilter`
[Section titled “Interaction with callModelInputFilter”](#interaction-with-callmodelinputfilter)
`reasoningItemIdPolicy` is applied before `callModelInputFilter`. If you need custom behavior, `callModelInputFilter` can still inspect the prepared input and re-introduce or remove reasoning IDs manually before the model call.
#### When to use `'omit'`
[Section titled “When to use 'omit'”](#when-to-use-omit)
Use `'omit'` when you want replayed reasoning items to be normalized without IDs (for example, to keep forwarded/replayed model inputs simpler or to match integration requirements in your app pipeline).
It is also a useful troubleshooting option if your backend/provider rejects replayed reasoning items with request validation errors (for example, HTTP `400` errors related to reasoning item IDs in follow-up inputs). In those cases, stripping replayed reasoning IDs with `'omit'` can avoid sending IDs that the backend treats as invalid for a new request.
Keep `'preserve'` if you want the SDK to carry reasoning-item IDs through replayed inputs and your integration accepts them.
## Errors and recovery
[Section titled “Errors and recovery”](#errors-and-recovery)
### Error handlers
[Section titled “Error handlers”](#error-handlers)
Use `errorHandlers` to convert supported runtime errors into a final output instead of throwing. The supported keys are `maxTurns` and `modelRefusal`.
* `errorHandlers.maxTurns` handles only max-turn errors.
* `errorHandlers.modelRefusal` handles model refusals surfaced as [`ModelRefusalError`](/openai-agents-js/openai/agents-core/classes/modelrefusalerror).
* `errorHandlers.default` is used as a fallback for supported kinds.
* Handlers receive `{ error, context, runData }` and can return `{ finalOutput, includeInHistory? }`.
### Exceptions
[Section titled “Exceptions”](#exceptions)
The SDK throws a small set of errors you can catch:
* [`MaxTurnsExceededError`](/openai-agents-js/openai/agents-core/classes/maxturnsexceedederror) – `maxTurns` reached.
* [`ModelBehaviorError`](/openai-agents-js/openai/agents-core/classes/modelbehaviorerror) – model produced invalid output (e.g. malformed JSON, unknown tool).
* [`ModelRefusalError`](/openai-agents-js/openai/agents-core/classes/modelrefusalerror) – model refused to produce the requested output.
* [`InputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents-core/classes/inputguardrailtripwiretriggered) / [`OutputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents-core/classes/outputguardrailtripwiretriggered) – guardrail violations.
* [`ToolInputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents-core/classes/toolinputguardrailtripwiretriggered) / [`ToolOutputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents-core/classes/tooloutputguardrailtripwiretriggered) – tool guardrail violations.
* [`GuardrailExecutionError`](/openai-agents-js/openai/agents-core/classes/guardrailexecutionerror) – guardrails failed to complete.
* [`ToolTimeoutError`](/openai-agents-js/openai/agents-core/classes/tooltimeouterror) – a function tool exceeded `timeoutMs` and used `timeoutBehavior: 'raise_exception'`.
* [`ToolCallError`](/openai-agents-js/openai/agents-core/classes/toolcallerror) – function tool execution failed for non-timeout errors.
* [`UserError`](/openai-agents-js/openai/agents-core/classes/usererror) – any error thrown based on configuration or user input.
All extend the base `AgentsError` class, which could provide the `state` property to access the current run state.
Here is an example code that handles `GuardrailExecutionError`. Because input guardrails only run on the first user input, the example restarts the run with the original input and context. It also shows reusing the saved state to retry output guardrails without calling the model again:
Guardrail execution error
```typescript
import {
Agent,
GuardrailExecutionError,
InputGuardrail,
InputGuardrailTripwireTriggered,
OutputGuardrail,
OutputGuardrailTripwireTriggered,
run,
} from '@openai/agents';
import { z } from 'zod';
// Shared guardrail agent to avoid re-creating it on every fallback run.
const guardrailAgent = new Agent({
name: 'Guardrail check',
instructions: 'Check if the user is asking you to do their math homework.',
outputType: z.object({
isMathHomework: z.boolean(),
reasoning: z.string(),
}),
});
async function main() {
const input = 'Hello, can you help me solve for x: 2x + 3 = 11?';
const context = { customerId: '12345' };
// Input guardrail example
const unstableInputGuardrail: InputGuardrail = {
name: 'Math Homework Guardrail (unstable)',
execute: async () => {
throw new Error('Something is wrong!');
},
};
const fallbackInputGuardrail: InputGuardrail = {
name: 'Math Homework Guardrail (fallback)',
execute: async ({ input, context }) => {
const result = await run(guardrailAgent, input, { context });
const isMathHomework =
result.finalOutput?.isMathHomework ??
/solve for x|math homework/i.test(JSON.stringify(input));
return {
outputInfo: result.finalOutput,
tripwireTriggered: isMathHomework,
};
},
};
const agent = new Agent({
name: 'Customer support agent',
instructions:
'You are a customer support agent. You help customers with their questions.',
inputGuardrails: [unstableInputGuardrail],
});
try {
// Input guardrails only run on the first turn of a run, so retries must start a fresh run.
await run(agent, input, { context });
} catch (e) {
if (e instanceof GuardrailExecutionError) {
console.error(`Guardrail execution failed (input): ${e}`);
try {
agent.inputGuardrails = [fallbackInputGuardrail];
// Retry from scratch with the original input and context.
await run(agent, input, { context });
} catch (ee) {
if (ee instanceof InputGuardrailTripwireTriggered) {
console.log('Math homework input guardrail tripped on retry');
} else {
throw ee;
}
}
} else {
throw e;
}
}
// Output guardrail example
const replyOutputSchema = z.object({ reply: z.string() });
const unstableOutputGuardrail: OutputGuardrail = {
name: 'Answer review (unstable)',
execute: async () => {
throw new Error('Output guardrail crashed.');
},
};
const fallbackOutputGuardrail: OutputGuardrail = {
name: 'Answer review (fallback)',
execute: async ({ agentOutput }) => {
const outputText =
typeof agentOutput === 'string'
? agentOutput
: (agentOutput?.reply ?? JSON.stringify(agentOutput));
const flagged = /math homework|solve for x|x =/i.test(outputText);
return {
outputInfo: { flaggedOutput: outputText },
tripwireTriggered: flagged,
};
},
};
const agent2 = new Agent({
name: 'Customer support agent (output check)',
instructions: 'You are a customer support agent. Answer briefly.',
outputType: replyOutputSchema,
outputGuardrails: [unstableOutputGuardrail],
});
try {
await run(agent2, input, { context });
} catch (e) {
if (e instanceof GuardrailExecutionError && e.state) {
console.error(`Guardrail execution failed (output): ${e}`);
try {
agent2.outputGuardrails = [fallbackOutputGuardrail];
// Output guardrails can be retried using the saved state without another model call.
await run(agent2, e.state);
} catch (ee) {
if (ee instanceof OutputGuardrailTripwireTriggered) {
console.log('Output guardrail tripped after retry with saved state');
} else {
throw ee;
}
}
} else {
throw e;
}
}
}
main().catch(console.error);
```
Input vs. output retries:
* Input guardrails run only on the very first user input of a run, so you must start a fresh run with the same input/context to retry them—passing a saved `state` will not re-trigger input guardrails.
* Output guardrails run after the model response, so you can reuse the saved `state` from a `GuardrailExecutionError` to rerun output guardrails without another model call.
When you run the above example, you will see the following output:
```plaintext
Guardrail execution failed (input): Error: Input guardrail failed to complete: Error: Something is wrong!
Math homework input guardrail tripped on retry
Guardrail execution failed (output): Error: Output guardrail failed to complete: Error: Output guardrail crashed.
Output guardrail tripped after retry with saved state
```
***
## Related guides
[Section titled “Related guides”](#related-guides)
* [Agents](/openai-agents-js/guides/agents) for defining the agent before you run it.
* [Results](/openai-agents-js/guides/results) for `finalOutput`, run items, interruptions, and resume state.
* [Sessions](/openai-agents-js/guides/sessions) for persistent SDK-managed memory.
* [Tools](/openai-agents-js/guides/tools) for the capabilities used during the run loop.
* [Models](/openai-agents-js/guides/models) for provider configuration and Responses transport.
* Add [guardrails](/openai-agents-js/guides/guardrails) or [tracing](/openai-agents-js/guides/tracing) for production readiness.
# Quickstart
> Create your first sandbox agent with an isolated workspace, filesystem tools, shell commands, and sandbox session state.
Beta feature
Sandbox agents are in beta. API details, defaults, and supported capabilities may change before general availability, and more advanced features are expected over time.
Modern agents work best when they can operate on real files in a filesystem. **Sandbox Agents** in the Agents SDK give the model a persistent workspace where it can search large document sets, edit files, run commands, generate artifacts, and pick work back up from saved sandbox state.
The SDK gives you that execution harness without making you wire together file staging, filesystem tools, shell access, sandbox lifecycle, snapshots, and provider-specific glue yourself. You keep the normal `Agent` and `Runner` flow, then add a `Manifest` for the workspace, capabilities for sandbox-native tools, and the `sandbox` run option for where the work runs.
## Prerequisites
[Section titled “Prerequisites”](#prerequisites)
* Node.js 22 or higher.
* Basic familiarity with the OpenAI Agents SDK.
* A sandbox client. For local development, start with `UnixLocalSandboxClient`.
This quickstart uses Node.js and npm commands, but the SDK is not limited to Node.js. Sandbox agents can also run on Deno and Bun when your project uses compatible package resolution and runtime APIs.
## Installation
[Section titled “Installation”](#installation)
If you have not already installed the SDK:
```bash
npm install @openai/agents
```
For Docker-backed sandboxes, install Docker locally and use `DockerSandboxClient` from `@openai/agents/sandbox/local`.
If you use interactive local PTY sessions with `tty: true`, the process running the SDK also needs Python 3 available as `python3`, or through `OPENAI_AGENTS_PYTHON`. Non-PTY shell commands do not require Python.
## Create a local sandbox agent
[Section titled “Create a local sandbox agent”](#create-a-local-sandbox-agent)
This example stages a local repo under `repo/`, loads local skills lazily, and lets the runner create a Unix-local sandbox session for the run. The agent definition owns the manifest and capabilities, while the run config only chooses the sandbox client for this run.
Create a local sandbox agent
```typescript
import { run } from '@openai/agents';
import {
Capabilities,
Manifest,
SandboxAgent,
localDir,
skills,
} from '@openai/agents/sandbox';
import {
UnixLocalSandboxClient,
localDirLazySkillSource,
} from '@openai/agents/sandbox/local';
import { dirname, join } from 'node:path';
import { fileURLToPath } from 'node:url';
const exampleDir = dirname(fileURLToPath(import.meta.url));
const hostRepoDir = join(exampleDir, 'repo');
const hostSkillsDir = join(exampleDir, 'skills');
const manifest = new Manifest({
entries: {
repo: localDir({ src: hostRepoDir }),
},
});
const agent = new SandboxAgent({
name: 'Sandbox engineer',
model: 'gpt-5.5',
instructions:
'Read `repo/task.md` before editing files. Load the `$invoice-total-fixer` skill before changing code. Stay grounded in the repository, preserve existing behavior, and mention the exact verification command you ran. If you edit files with apply_patch, paths are relative to the sandbox workspace root.',
defaultManifest: manifest,
capabilities: [
...Capabilities.default(),
skills({
lazyFrom: localDirLazySkillSource({
src: hostSkillsDir,
}),
}),
],
});
const result = await run(
agent,
'Open `repo/task.md`, fix the issue, run the targeted test, and summarize the change.',
{
sandbox: {
client: new UnixLocalSandboxClient(),
},
},
);
console.log(result.finalOutput);
```
## Key choices
[Section titled “Key choices”](#key-choices)
Once the basic run works, the choices most people reach for next are:
* `defaultManifest`: the files, repos, directories, and mounts for fresh sandbox sessions.
* `instructions`: short workflow rules that should apply across prompts.
* `baseInstructions`: an advanced escape hatch for replacing the SDK sandbox prompt.
* `capabilities`: sandbox-native tools such as filesystem editing/image inspection, shell, skills, memory, and compaction.
* `runAs`: the sandbox user identity for model-facing tools.
* `sandbox.client`: the sandbox backend.
* `sandbox.session`, `sandbox.sessionState`, or `sandbox.snapshot`: how later runs reconnect to prior work.
## Where to go next
[Section titled “Where to go next”](#where-to-go-next)
* [Concepts](/openai-agents-js/guides/sandbox-agents/concepts): understand manifests, capabilities, permissions, snapshots, run config, and composition patterns.
* [Sandbox clients](/openai-agents-js/guides/sandbox-agents/clients): choose Unix-local, Docker, hosted providers, and mount strategies.
* [Agent memory](/openai-agents-js/guides/sandbox-agents/memory): preserve and reuse lessons from previous sandbox runs.
If shell access is only one occasional tool, start with hosted shell in the [Tools guide](/openai-agents-js/guides/tools). Reach for sandbox agents when workspace isolation, sandbox client choice, or sandbox-session resume behavior are part of the design.
# Sandbox clients
> Choose where sandbox work should run and how sessions, snapshots, mounts, and ports behave.
Use this page to choose where sandbox work should run. In most cases, the `SandboxAgent` definition stays the same while the sandbox client and client-specific options change in the `sandbox` run option.
Beta feature
Sandbox agents are in beta. API details, defaults, and supported capabilities may change before general availability, and more advanced features are expected over time.
## Decision guide
[Section titled “Decision guide”](#decision-guide)
| Goal | Start with | Why |
| ---------------------------------------------- | ------------------------ | ------------------------------------------------------------------- |
| Fastest local iteration on macOS or Linux | `UnixLocalSandboxClient` | No extra service dependency and a simple local filesystem workflow. |
| Basic container isolation | `DockerSandboxClient` | Runs work inside Docker with a specific image. |
| Hosted execution or production-style isolation | A hosted sandbox client | Moves the workspace boundary to a provider-managed environment. |
## Local clients
[Section titled “Local clients”](#local-clients)
For most users, start with one of these two sandbox clients:
| Client | Install | Choose it when |
| ------------------------ | ---------------------------- | ------------------------------------------------------------------------------ |
| `UnixLocalSandboxClient` | none | Fastest local iteration on macOS or Linux. Good default for local development. |
| `DockerSandboxClient` | Docker CLI available locally | You want container isolation or a specific image for local parity. |
Unix-local is the easiest way to start developing against a local filesystem. Move to Docker or a hosted provider when you need stronger environment isolation or production-style parity.
To switch from Unix-local to Docker, keep the agent definition the same and change only the client:
Use Docker
```typescript
import { run } from '@openai/agents';
import { SandboxAgent } from '@openai/agents/sandbox';
import { DockerSandboxClient } from '@openai/agents/sandbox/local';
const agent = new SandboxAgent({
name: 'Workspace reviewer',
model: 'gpt-5.5',
instructions: 'Inspect the sandbox workspace before answering.',
});
const result = await run(agent, 'Inspect the workspace.', {
sandbox: {
client: new DockerSandboxClient({ image: 'node:22-bookworm-slim' }),
},
});
console.log(result.finalOutput);
```
The same agent can usually run with either local client:
Switch between local clients
```typescript
import {
DockerSandboxClient,
UnixLocalSandboxClient,
} from '@openai/agents/sandbox/local';
const client = process.env.USE_DOCKER
? new DockerSandboxClient({ image: 'node:22-bookworm-slim' })
: new UnixLocalSandboxClient();
```
### Session ownership
[Section titled “Session ownership”](#session-ownership)
There are two lifecycle styles.
| Style | What you pass | Who closes the session | Use it when |
| --------------- | ---------------------- | ---------------------- | ---------------------------------------------------------------------------------------------- |
| SDK-owned | `sandbox: { client }` | The runner | The sandbox only needs to live for one run. |
| Developer-owned | `sandbox: { session }` | Your code | You need to inspect files afterward, reuse the same live session, or coordinate multiple runs. |
When you create a session yourself, close it yourself:
Own the sandbox session lifecycle
```typescript
import { run } from '@openai/agents';
import { Manifest, SandboxAgent } from '@openai/agents/sandbox';
import { UnixLocalSandboxClient } from '@openai/agents/sandbox/local';
const manifest = new Manifest();
const agent = new SandboxAgent({
name: 'Workspace reviewer',
model: 'gpt-5.5',
instructions: 'Inspect the sandbox workspace before answering.',
});
const client = new UnixLocalSandboxClient();
const session = await client.create({ manifest });
try {
await run(agent, 'First pass.', { sandbox: { session } });
await run(agent, 'Follow-up pass.', { sandbox: { session } });
} finally {
await session.close?.();
}
```
### Resume and snapshots
[Section titled “Resume and snapshots”](#resume-and-snapshots)
Sandbox state and conversation state are separate:
* SDK conversation state lives in `result.history`, an SDK `Session`, `conversationId`, or `previousResponseId`.
* Sandbox state lives in the live sandbox session, serialized `sessionState`, `RunState` sandbox payloads, or snapshots.
Use `sessionState` when you want to reconnect to the same backend session through a sandbox client. Use a snapshot when you want a fresh session seeded from saved workspace contents.
Serialize and resume sandbox state
```typescript
import { Manifest } from '@openai/agents/sandbox';
import { UnixLocalSandboxClient } from '@openai/agents/sandbox/local';
const manifest = new Manifest();
const client = new UnixLocalSandboxClient({
snapshot: { type: 'local', baseDir: '/tmp/my-sandbox-snapshots' },
});
const session = await client.create({ manifest });
const state = await client.serializeSessionState?.(session.state);
await session.close?.();
if (state) {
const restored = await client.resume?.(
await client.deserializeSessionState!(state),
);
await restored?.close?.();
}
```
`RunState` can also preserve runner-managed sandbox state when you pause or resume a larger workflow. Use explicit `sessionState` when the sandbox lifecycle is managed outside a serialized run.
### Manifest materialization
[Section titled “Manifest materialization”](#manifest-materialization)
Manifest entries are prepared before the agent runs. You can tune materialization concurrency per run or per client create call:
Tune manifest materialization concurrency
```typescript
import { run } from '@openai/agents';
import { SandboxAgent } from '@openai/agents/sandbox';
import { UnixLocalSandboxClient } from '@openai/agents/sandbox/local';
const agent = new SandboxAgent({
name: 'Repository inspector',
model: 'gpt-5.5',
instructions: 'Inspect the repository before answering.',
});
await run(agent, 'Inspect the repo.', {
sandbox: {
client: new UnixLocalSandboxClient(),
concurrencyLimits: {
manifestEntries: 4,
localDirFiles: 16,
},
},
});
```
`manifestEntries` limits parallel top-level entry work. `localDirFiles` limits file copy concurrency inside `localDir()` entries.
## Mounts and remote storage
[Section titled “Mounts and remote storage”](#mounts-and-remote-storage)
Mount entries describe what storage to expose; mount strategies describe how a sandbox backend attaches that storage. Import the built-in mount entries and generic strategies from `@openai/agents/sandbox`.
Common mount options:
* `mountPath`: where the storage appears in the sandbox. Relative paths are resolved under the manifest root; absolute paths are used as-is.
* `readOnly`: set this when the sandbox should not write back to the mounted storage.
* `mountStrategy`: use a strategy that matches both the mount entry and the sandbox backend.
Mounts are treated as ephemeral workspace entries. Snapshot and persistence flows detach or skip mounted paths instead of copying mounted remote storage into the saved workspace.
Generic local/container strategies:
| Strategy or pattern | Use it when | Notes |
| -------------------------------- | --------------------------------------------------------------------------------------- | ---------------------------------------------------------------- |
| `inContainerMountStrategy(...)` | The sandbox image can run a mount command such as `rclone`, `mount-s3`, or `blobfuse2`. | Available as a generic strategy; support depends on the backend. |
| `dockerVolumeMountStrategy(...)` | Docker should attach a volume-driver-backed mount before the container starts. | Docker-only. |
| `localBindMountStrategy()` | A local backend should bind an absolute local path into the workspace. | Supported by local workspace materialization where allowed. |
Backend support is intentionally explicit:
| Backend | Mount notes |
| ------------------------ | ---------------------------------------------------------------------------------------------------------------------------------------- |
| `UnixLocalSandboxClient` | Supports local bind-style mounts through the local workspace model. |
| `DockerSandboxClient` | Supports local bind mounts and Docker volume-style strategies where Docker can attach the storage. |
| Hosted providers | Provider-specific strategies live with each provider implementation. Check that provider’s docs for supported mounts and required setup. |
Do not assume a mount entry works on every backend. If a client cannot enforce manifest metadata, identity, or mount behavior, it should fail early instead of silently ignoring that part of the manifest.
## Supported hosted platforms
[Section titled “Supported hosted platforms”](#supported-hosted-platforms)
When you need a hosted environment, the same `SandboxAgent` definition usually carries over and only the sandbox client changes in the `sandbox` run option.
Hosted provider implementations are available from `@openai/agents-extensions` provider subpaths. Check the provider’s docs for exact environment variables, runnable examples, port behavior, PTY support, snapshot behavior, and cleanup behavior.
Install `@openai/agents-extensions` and satisfy its package-level peers. Each provider may also require a provider SDK package or backend setup:
| Client | Import path | Provider requirement |
| ------------------------- | ---------------------------------------------- | ---------------------------------------------------- |
| `BlaxelSandboxClient` | `@openai/agents-extensions/sandbox/blaxel` | npm peer: `@blaxel/core` |
| `CloudflareSandboxClient` | `@openai/agents-extensions/sandbox/cloudflare` | Cloudflare Sandbox bridge Worker URL and Worker auth |
| `DaytonaSandboxClient` | `@openai/agents-extensions/sandbox/daytona` | npm peer: `@daytonaio/sdk` |
| `E2BSandboxClient` | `@openai/agents-extensions/sandbox/e2b` | npm peer: `e2b` or `@e2b/code-interpreter` |
| `ModalSandboxClient` | `@openai/agents-extensions/sandbox/modal` | npm peer: `modal` |
| `RunloopSandboxClient` | `@openai/agents-extensions/sandbox/runloop` | npm peer: `@runloop/api-client` |
| `VercelSandboxClient` | `@openai/agents-extensions/sandbox/vercel` | npm peer: `@vercel/sandbox` |
`CloudflareSandboxClient` does not import a Cloudflare npm SDK. It talks to a deployed Cloudflare Sandbox bridge Worker over HTTP instead.
Hosted sandbox clients expose provider-specific mount strategies. Choose the backend and mount strategy that best fit your storage provider:
| Backend | Mount notes |
| ------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| Docker | Supports `s3Mount()`, `gcsMount()`, `r2Mount()`, `azureBlobMount()`, `boxMount()`, and `s3FilesMount()` with local strategies such as `inContainerMountStrategy()` and `dockerVolumeMountStrategy()`. |
| `ModalSandboxClient` | Supports cloud bucket mounts with `ModalCloudBucketMountStrategy` on S3, R2, and HMAC-authenticated GCS mount entries. |
| `CloudflareSandboxClient` | Supports Cloudflare bucket mounts with `CloudflareBucketMountStrategy` on S3, R2, and HMAC-authenticated GCS mount entries. |
| `BlaxelSandboxClient` | Supports cloud bucket mounts with `BlaxelCloudBucketMountStrategy` on S3, R2, and GCS mount entries. It also supports persistent Blaxel Drives with `BlaxelDriveMount` and `BlaxelDriveMountStrategy`. |
| `DaytonaSandboxClient` | Supports rclone-backed mounts with `DaytonaCloudBucketMountStrategy` on S3, GCS, R2, Azure Blob, and Box mount entries. |
| `E2BSandboxClient` | Supports rclone-backed mounts with `E2BCloudBucketMountStrategy` on S3, GCS, R2, Azure Blob, and Box mount entries. |
| `RunloopSandboxClient` | Supports rclone-backed mounts with `RunloopCloudBucketMountStrategy` on S3, GCS, R2, Azure Blob, and Box mount entries. |
| `VercelSandboxClient` | No hosted-specific mount strategy is currently exposed. Use manifest files, repos, snapshots, or other workspace inputs instead. |
The table below summarizes which remote storage entries each backend can mount directly:
| Backend | AWS S3 | Cloudflare R2 | GCS | Azure Blob Storage | Box | S3 Files |
| ------------------------- | ------ | ------------- | --- | ------------------ | --- | -------- |
| Docker | yes | yes | yes | yes | yes | yes |
| `ModalSandboxClient` | yes | yes | yes | no | no | no |
| `CloudflareSandboxClient` | yes | yes | yes | no | no | no |
| `BlaxelSandboxClient` | yes | yes | yes | no | no | no |
| `DaytonaSandboxClient` | yes | yes | yes | yes | yes | no |
| `E2BSandboxClient` | yes | yes | yes | yes | yes | no |
| `RunloopSandboxClient` | yes | yes | yes | yes | yes | no |
| `VercelSandboxClient` | no | no | no | no | no | no |
### Exposed ports
[Section titled “Exposed ports”](#exposed-ports)
Sandbox clients can expose endpoints through `resolveExposedPort(port)` when the backend supports it.
| Client | Behavior |
| ------------------------ | ----------------------------------------------------------------------- |
| `UnixLocalSandboxClient` | Resolves configured ports to `127.0.0.1`. |
| `DockerSandboxClient` | Publishes configured container ports and resolves their host endpoints. |
Declare the ports in the client options when you need a backend to enforce an allowlist:
Expose a port
```typescript
import { DockerSandboxClient } from '@openai/agents/sandbox/local';
const client = new DockerSandboxClient({
image: 'node:22-bookworm-slim',
exposedPorts: [3000],
});
```
### Capability support matrix
[Section titled “Capability support matrix”](#capability-support-matrix)
| Capability | Unix-local | Docker |
| -------------------- | ---------------------------------------------------------- | ------------------------------------- |
| `exec_command` | Supported | Supported |
| PTY `write_stdin` | Supported | Supported |
| `apply_patch` | Supported | Supported through workspace file APIs |
| `view_image` | Supported | Supported through workspace file APIs |
| `runAs` for commands | Supported when the host can resolve and switch to the user | Limited by container/user setup |
| Local snapshots | Supported | Supported |
| Local/Docker mounts | Local bind-style support | Bind and Docker volume-style support |
Local PTY support uses a small Python 3 bridge in the SDK process. The bridge is only used for `tty: true` sessions, where Node.js does not provide a built-in PTY API and the SDK needs standard POSIX PTY behavior for interactive stdin, signal handling, and exit status reporting. Install `python3` in the environment that runs your SDK code, or set `OPENAI_AGENTS_PYTHON` to a Python 3 executable. This is separate from the Python version, if any, installed inside a Docker sandbox image.
Hosted provider support varies by provider. Check the provider-specific docs for exact options, environment variables, port behavior, PTY support, snapshot behavior, and cleanup behavior.
# Concepts
> Understand manifests, capabilities, permissions, snapshots, sandbox lifecycle, run config, and composition patterns.
Beta feature
Sandbox agents are in beta. API details, defaults, and supported capabilities may change before general availability, and more advanced features are expected over time.
Modern agents work best when they can operate on real files in a filesystem. **Sandbox Agents** can make use of specialized tools and shell commands to search over and manipulate large document sets, edit files, generate artifacts, and run commands. The sandbox provides the model with a persistent workspace that the agent can use to do work on your behalf. Sandbox Agents in the Agents SDK help you run agents paired with a sandbox environment, making it easy to get the right files on the filesystem and orchestrate sandboxes to start, stop, and resume tasks at scale.
You define the workspace around the data the agent needs. It can start from GitHub repos, local files and directories, synthetic task files, remote filesystems such as S3 or Azure Blob Storage, and other sandbox inputs you provide.
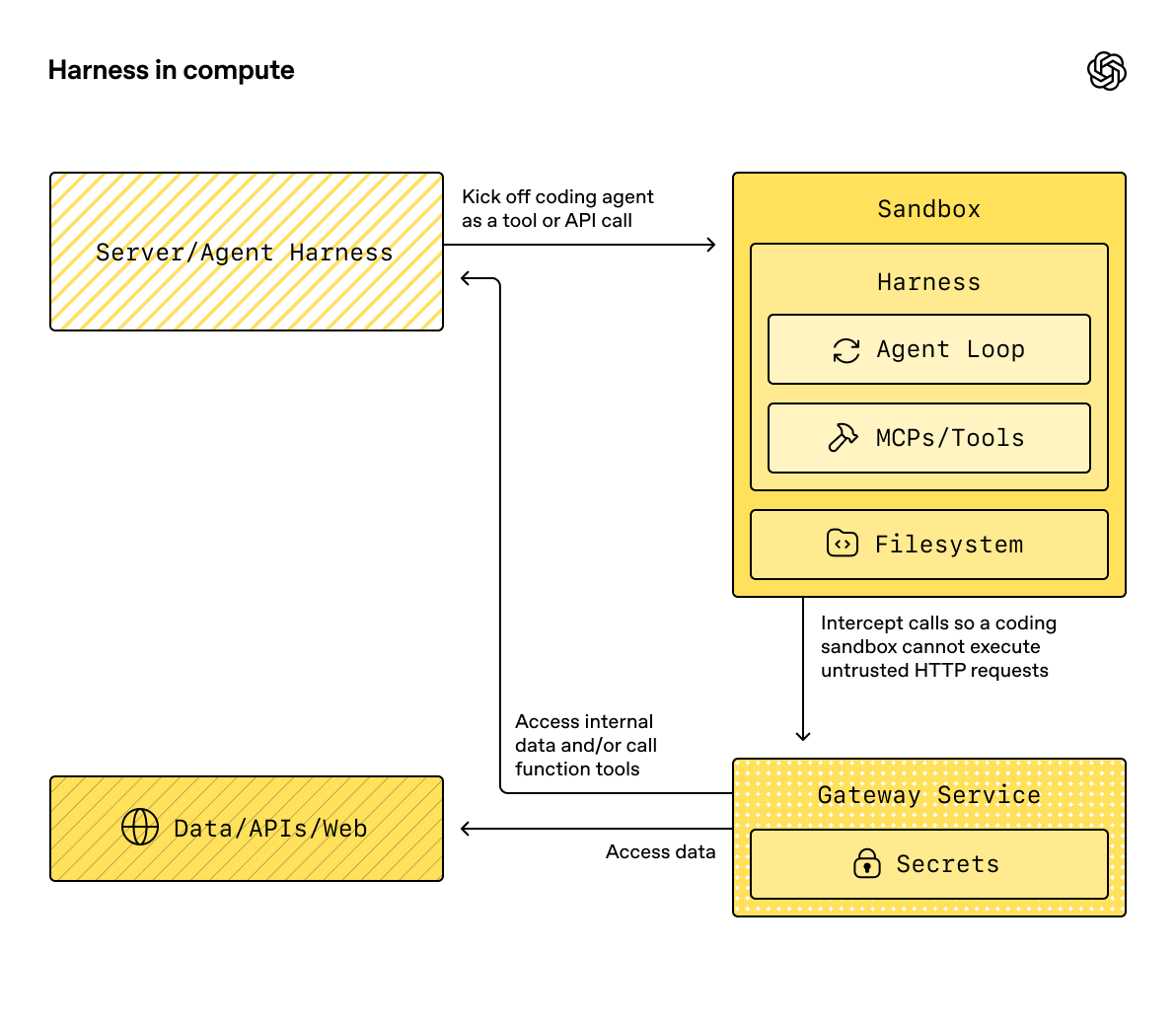
`SandboxAgent` extends `Agent`, so it is still an `Agent`. It keeps the usual agent surface such as `instructions`, `tools`, `handoffs`, `mcpServers`, `modelSettings`, output types, guardrails, and hooks, and it still runs through the normal `run()` and `Runner` APIs. What changes is the execution boundary:
* `SandboxAgent` defines the agent itself: the usual agent configuration plus sandbox-specific defaults like `defaultManifest`, `baseInstructions`, `runAs`, and capabilities such as filesystem tools, shell access, skills, memory, or compaction.
* `Manifest` declares the desired starting contents and layout for a fresh sandbox workspace, including files, repos, mounts, and environment.
* A sandbox session is the live execution environment where commands run and files change.
* The `sandbox` run option decides how the run gets that sandbox session, for example by injecting one directly, reconnecting from serialized sandbox session state, or creating a fresh sandbox session through a sandbox client.
* Saved sandbox state and snapshots let later runs reconnect to prior work or seed a fresh sandbox session from saved contents.
`Manifest` defines the starting contents for a new sandbox workspace. It does not describe the current files in every live sandbox, because reused sessions, serialized session state, and snapshots can all provide or change the workspace at run time.
Throughout this page, “sandbox session” means the live execution environment managed by a sandbox client. The exact boundary depends on the client: Unix-local sessions run in a local workspace on the host, while Docker and hosted clients provide stronger environment isolation. This is different from the SDK’s conversational `Session` interfaces described in [Sessions](/openai-agents-js/guides/sessions).
The outer runtime still owns approvals, tracing, handoffs, and resume bookkeeping. The sandbox session owns commands, file changes, and environment isolation. That split is a core part of the model.
### How the pieces fit together
[Section titled “How the pieces fit together”](#how-the-pieces-fit-together)
A sandbox run combines an agent definition with per-run sandbox configuration. The runner prepares the agent, binds it to a live sandbox session, and can save state for later runs.
**SandboxAgent**Agent plus sandbox defaults
→
**Runner**Prepare instructions and bind capability tools
→
**Sandbox session**Workspace where commands run and files change
→
**Saved state**Resume later or seed a fresh workspace
Sandbox-specific defaults stay on `SandboxAgent`. Per-run sandbox-session choices stay in the `sandbox` run option.
Think about the lifecycle in three phases:
1. Define the agent and starting workspace contents with `SandboxAgent`, `Manifest`, and capabilities.
2. Execute a run by giving `run()` or `Runner` a `sandbox` run option that injects, resumes, or creates the sandbox session.
3. Continue later from runner-managed `RunState`, explicit sandbox `sessionState`, or a saved workspace snapshot.
If shell access is only one occasional tool, start with hosted shell in the [Tools guide](/openai-agents-js/guides/tools). Reach for sandbox agents when workspace isolation, sandbox client choice, or sandbox-session resume behavior are part of the design.
## When to use them
[Section titled “When to use them”](#when-to-use-them)
Sandbox agents are a good fit for workspace-centric workflows, for example:
* **Coding and debugging**: orchestrate automated fixes for issue reports in a GitHub repo and run targeted tests.
* **Document processing and editing**: extract information from a user’s financial documents and create a completed tax-form draft.
* **File-grounded review or analysis**: check onboarding packets, generated reports, or artifact bundles before answering.
* **Isolated multi-agent patterns**: give each reviewer or coding sub-agent its own workspace.
* **Multi-step workspace tasks**: fix a bug in one run and add a regression test later, or resume from snapshot or sandbox session state.
If you do not need access to files or a living filesystem, keep using `Agent`. If shell access is just one occasional capability, add hosted shell; if the workspace boundary itself is part of the feature, use sandbox agents.
## Choose a sandbox client
[Section titled “Choose a sandbox client”](#choose-a-sandbox-client)
Start with `UnixLocalSandboxClient` for local development. Move to `DockerSandboxClient` when you need container isolation or image parity. Move to a hosted provider when you need provider-managed execution.
In most cases, the `SandboxAgent` definition stays the same while the sandbox client and its options change in the `sandbox` run option. See [Sandbox clients](/openai-agents-js/guides/sandbox-agents/clients) for local, Docker, hosted, and remote-mount options.
## Core pieces
[Section titled “Core pieces”](#core-pieces)
| Layer | Main SDK pieces | What it answers |
| ------------------- | ---------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------- |
| Agent definition | `SandboxAgent`, `Manifest`, capabilities | What agent will run, and what fresh-session workspace contract should it start from? |
| Sandbox execution | `sandbox` run option, the sandbox client, and the live sandbox session | How does this run get a live sandbox session, and where does the work execute? |
| Saved sandbox state | `RunState` sandbox payload, `sessionState`, and snapshots | How does this workflow reconnect to prior sandbox work or seed a fresh sandbox session from saved contents? |
The main SDK pieces map onto those layers like this:
| Piece | What it owns | Ask this question |
| ---------------------- | --------------------------------------------------- | --------------------------------------------------------------------------------------------------- |
| `SandboxAgent` | The agent definition | What should this agent do, and which defaults should travel with it? |
| `Manifest` | Fresh-session workspace files and folders | What files and folders should be present on the filesystem when the run starts? |
| `Capability` | Sandbox-native behavior | Which tools, instruction fragments, or runtime behavior should attach to this agent? |
| `sandbox` run option | Per-run sandbox client and sandbox-session source | Should this run inject, resume, or create a sandbox session? |
| `RunState` | Runner-managed saved sandbox state | Am I resuming a prior runner-managed workflow and carrying its sandbox state forward automatically? |
| `sandbox.sessionState` | Explicit serialized sandbox session state | Do I want to resume from sandbox state I already serialized outside `RunState`? |
| `sandbox.snapshot` | Saved workspace contents for fresh sandbox sessions | Should a new sandbox session start from saved files and artifacts? |
A practical design order is:
1. Define the fresh-session workspace contract with a `Manifest` or manifest init object.
2. Define the agent with `SandboxAgent`.
3. Add built-in or custom capabilities.
4. Decide how each run should obtain its sandbox session in `run(agent, input, { sandbox: ... })` or `new Runner({ sandbox: ... })`.
## How a sandbox run is prepared
[Section titled “How a sandbox run is prepared”](#how-a-sandbox-run-is-prepared)
At run time, the runner turns that definition into a concrete sandbox-backed run:
1. It resolves the sandbox session from the `sandbox` run option.
2. It determines the effective workspace inputs for the run.
3. It lets capabilities process the resulting manifest.
4. It builds the final instructions in a fixed order: the SDK’s default sandbox prompt, or `baseInstructions` if you explicitly override it, then `instructions`, then capability instruction fragments, then any remote-mount policy text, then a rendered filesystem tree.
5. It binds capability tools to the live sandbox session and runs the prepared agent through the normal `run()` and `Runner` APIs.
Sandboxing does not change what a turn means. A turn is still a model step, not a single shell command or sandbox action. There is no fixed 1:1 mapping between sandbox-side operations and turns. As a practical rule, another turn is consumed only when the agent runtime needs another model response after sandbox work has happened.
## `SandboxAgent` options
[Section titled “SandboxAgent options”](#sandboxagent-options)
These are the sandbox-specific options on top of the usual `Agent` fields:
| Option | Best use |
| ------------------ | --------------------------------------------------------------------------------------------- |
| `defaultManifest` | The default workspace for fresh sandbox sessions created by the runner. |
| `instructions` | Additional role, workflow, and success criteria appended after the SDK sandbox prompt. |
| `baseInstructions` | Advanced escape hatch that replaces the SDK sandbox prompt. |
| `capabilities` | Sandbox-native tools and behavior that should travel with this agent. |
| `runAs` | User identity for model-facing sandbox tools such as shell commands, file reads, and patches. |
Sandbox client choice, sandbox-session reuse, manifest override, and snapshot selection belong in the `sandbox` run option, not on the agent.
### `defaultManifest`
[Section titled “defaultManifest”](#defaultmanifest)
`defaultManifest` is the default workspace used when the runner creates a fresh sandbox session for this agent. Pass either a `Manifest` instance or the same init object you would pass to `new Manifest(...)`. Use it for the files, repos, helper material, output directories, and mounts the agent should usually start with.
This is only the default. A run can override it with `sandbox.manifest`, and a reused or resumed sandbox session keeps its existing workspace state.
Define a manifest
```typescript
import { file, gitRepo, Manifest } from '@openai/agents/sandbox';
const manifest = new Manifest({
root: '/workspace',
entries: {
'task.md': file({
content: 'Fix the failing test and summarize the change.',
}),
repo: gitRepo({
repo: 'openai/openai-agents-js',
ref: 'main',
}),
},
environment: {
NODE_ENV: 'test',
},
});
```
### `instructions` and `baseInstructions`
[Section titled “instructions and baseInstructions”](#instructions-and-baseinstructions)
Use `instructions` for short rules that should survive different prompts. In a `SandboxAgent`, these instructions are appended after the SDK’s sandbox base prompt, so you keep the built-in sandbox guidance and add your own role, workflow, and success criteria.
Use `baseInstructions` only when you want to replace the SDK sandbox base prompt. Most agents should not set it.
| Put it in… | Use it for | Examples |
| ------------------------------- | -------------------------------------------------------------------------- | ----------------------------------------------------------------------------------- |
| `instructions` | Stable role, workflow rules, and success criteria for the agent. | ”Inspect onboarding documents, then hand off.”, “Write final files into `output/`.” |
| `baseInstructions` | A full replacement for the SDK sandbox base prompt. | Custom low-level sandbox wrapper prompts. |
| the user prompt | The one-off request for this run. | ”Summarize this workspace.” |
| workspace files in the manifest | Longer task specs, repo-local instructions, or bounded reference material. | `repo/task.md`, document bundles, sample packets. |
Avoid copying the user’s one-off task into `instructions`, embedding long reference material that belongs in the manifest, restating tool docs that built-in capabilities already inject, or mixing in local installation notes the model does not need at run time.
### `capabilities`
[Section titled “capabilities”](#capabilities)
Capabilities attach sandbox-native behavior to a `SandboxAgent`. They can shape the workspace before a run starts, append sandbox-specific instructions, expose tools that bind to the live sandbox session, and adjust model behavior or input handling for that agent.
Built-in capabilities include:
| Capability | Add it when | Notes |
| -------------- | ---------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------- |
| `shell()` | The agent needs shell access. | Adds `exec_command`, plus `write_stdin` when the sandbox client supports PTY interaction. |
| `filesystem()` | The agent needs to edit files or inspect local images. | Adds `apply_patch` and `view_image`; patch paths are workspace-root-relative. |
| `skills()` | You want skill discovery and materialization in the sandbox. | Prefer this over mounting `.agents` or `.agents/skills` manually for sandbox-local `SKILL.md` skills. |
| `memory()` | Follow-on runs should read or generate memory artifacts. | Requires `shell()`; live updates also require `filesystem()`. |
| `compaction()` | Long-running flows need context trimming after compaction items. | Adjusts model sampling and input handling. |
By default, `SandboxAgent.capabilities` uses `Capabilities.default()`, which includes `filesystem()`, `shell()`, and `compaction()`. If you pass `capabilities: [...]`, that list replaces the default, so include any default capabilities you still want.
## Concepts
[Section titled “Concepts”](#concepts)
### Manifest
[Section titled “Manifest”](#manifest)
A `Manifest` describes the workspace for a fresh sandbox session. It can set the workspace `root`, declare files and directories, copy in local files, clone Git repos, attach remote storage mounts, set environment variables, define users or groups, and grant access to specific absolute paths outside the workspace.
Manifest environment values are persisted by default. Use ephemeral entries such as `{ value: "...", ephemeral: true }` for API keys, access tokens, or other short-lived credentials that should not be saved with sandbox state.
Manifest entry paths are workspace-relative. They cannot be absolute paths or escape the workspace with `..`, which keeps the workspace contract portable across local, Docker, and hosted clients.
Use manifest entries for the material the agent needs before work begins:
| Manifest entry | Use it for |
| ------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------- |
| `file()`, `dir()` | Small synthetic inputs, helper files, or output directories. |
| `localFile()`, `localDir()` | Host files or directories that should be materialized into the sandbox. |
| `gitRepo()` | A repository that should be fetched into the workspace. |
| mounts such as `s3Mount()`, `gcsMount()`, `r2Mount()`, `azureBlobMount()`, `s3FilesMount()` | External storage that should appear inside the sandbox. |
For local materialization, `localFile()` and `localDir()` source paths must stay inside the local source base directory. The default base is the current working directory of your Node process, and local sandbox clients may provide a client-specific base when they materialize entries. If a source must come from another absolute host directory, add the smallest necessary `Manifest.extraPathGrants` entry.
`extraPathGrants` is also used by local lazy skill discovery. A `localDirLazySkillSource()` that points outside the source base directory is ignored unless the manifest grants that directory. Prefer `readOnly: true` for input bundles such as shared skills, datasets, and reference repositories.
Grant a shared local source
```typescript
import { Manifest, localDir, skills } from '@openai/agents/sandbox';
import { localDirLazySkillSource } from '@openai/agents/sandbox/local';
import { dirname, join } from 'node:path';
import { fileURLToPath } from 'node:url';
const appRoot = dirname(fileURLToPath(import.meta.url));
const repoDir = join(appRoot, 'repo');
const sharedSkillsDir = '/opt/company/agent-skills';
const manifest = new Manifest({
extraPathGrants: [
{
path: sharedSkillsDir,
readOnly: true,
description: 'Shared skill bundle.',
},
],
entries: {
repo: localDir({ src: repoDir }),
},
});
const skillCapability = skills({
lazyFrom: localDirLazySkillSource({
src: sharedSkillsDir,
}),
});
```
Mount entries describe what storage to expose; mount strategies describe how a sandbox backend attaches that storage. See [Sandbox clients](/openai-agents-js/guides/sandbox-agents/clients#mounts-and-remote-storage) for mount options and provider support.
### Permissions
[Section titled “Permissions”](#permissions)
`Permissions` controls filesystem permissions for manifest entries. It is about the files the sandbox materializes, not model permissions, approval policy, or API credentials.
Users are the sandbox identities that can execute work. Add a user to the manifest when you want that identity to exist in the sandbox, then set `SandboxAgent.runAs` when model-facing sandbox tools such as shell commands, file reads, and patches should run as that user.
If you also need file-level sharing rules, combine users with manifest groups and entry `group` metadata. The `runAs` user controls who executes sandbox-native actions; `Permissions` controls which files that user can read, write, or execute once the sandbox has materialized the workspace.
### SnapshotSpec
[Section titled “SnapshotSpec”](#snapshotspec)
`SnapshotSpec` tells a fresh sandbox session where saved workspace contents should be restored from and persisted back to. It is the snapshot policy for the sandbox workspace, while `sessionState` is the serialized connection state for resuming a specific sandbox backend.
Use local snapshots for local durable snapshots and remote snapshots when your app provides a remote snapshot client. Mounted and ephemeral paths are not copied into snapshots as durable workspace contents.
### Sandbox lifecycle
[Section titled “Sandbox lifecycle”](#sandbox-lifecycle)
There are two lifecycle modes: **SDK-owned** and **developer-owned**.
**SDK-owned**Runner owns the live sandbox.
1. 1
Pass `sandbox.client`.
2. 2
Runner creates or resumes a sandbox session.
3. 3
Agent runs and snapshot-backed workspace state can persist.
4. 4
Runner closes runner-owned resources.
**Developer-owned**Your application owns the live sandbox.
1. 1
Create a `session`.
2. 2
Pass `sandbox.session` into the run.
3. 3
Agent uses the existing workspace.
4. 4
Inspect, reuse, then close the session yourself.
Use SDK-owned lifecycle when the sandbox only needs to live for one run. Pass a `client`, optional `manifest`, optional `snapshot`, and client `options`; the runner creates or resumes the sandbox, runs the agent, persists snapshot-backed workspace state, and lets the client clean up runner-owned resources.
Let the runner manage the sandbox session
```typescript
import { run } from '@openai/agents';
import { SandboxAgent } from '@openai/agents/sandbox';
import { UnixLocalSandboxClient } from '@openai/agents/sandbox/local';
const agent = new SandboxAgent({
name: 'Workspace reviewer',
model: 'gpt-5.5',
instructions: 'Inspect the sandbox workspace before answering.',
});
const result = await run(agent, 'Inspect the workspace.', {
sandbox: {
client: new UnixLocalSandboxClient(),
},
});
console.log(result.finalOutput);
```
Use developer-owned lifecycle when you want to eagerly create a sandbox, reuse one live sandbox across multiple runs, inspect files after a run, stream over a sandbox you created yourself, or decide exactly when cleanup happens. Passing `session` tells the runner to use that live sandbox, but not to close it for you.
Manage the sandbox session yourself
```typescript
import { run } from '@openai/agents';
import { Manifest, SandboxAgent } from '@openai/agents/sandbox';
import { UnixLocalSandboxClient } from '@openai/agents/sandbox/local';
const manifest = new Manifest();
const agent = new SandboxAgent({
name: 'Workspace reviewer',
model: 'gpt-5.5',
instructions: 'Inspect the sandbox workspace before answering.',
});
const client = new UnixLocalSandboxClient();
const session = await client.create({ manifest });
try {
await run(agent, 'First task.', { sandbox: { session } });
await run(agent, 'Follow-up task.', { sandbox: { session } });
} finally {
await session.close?.();
}
```
## `sandbox` run options
[Section titled “sandbox run options”](#sandbox-run-options)
The `sandbox` run option holds the per-run options that decide where the sandbox session comes from and how a fresh session should be initialized.
### Sandbox source
[Section titled “Sandbox source”](#sandbox-source)
These options decide whether the runner should reuse, resume, or create the sandbox session:
| Option | Use it when | Notes |
| -------------- | -------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------ |
| `client` | You want the runner to create, resume, and clean up sandbox sessions for you. | Required unless you provide a live sandbox `session`. |
| `session` | You already created a live sandbox session yourself. | The caller owns lifecycle; the runner reuses that live sandbox session. |
| `sessionState` | You have serialized sandbox session state but not a live sandbox session object. | Requires `client`; the runner resumes from that explicit state as an owning session. |
### Fresh-session inputs
[Section titled “Fresh-session inputs”](#fresh-session-inputs)
These options only matter when the runner is creating a fresh sandbox session:
| Option | Use it when | Notes |
| ---------- | --------------------------------------------------------- | ------------------------------------------------------------------------------------------------- |
| `manifest` | You want a one-off fresh-session workspace override. | Accepts a `Manifest` or manifest init object. Falls back to `agent.defaultManifest` when omitted. |
| `snapshot` | A fresh sandbox session should be seeded from a snapshot. | Useful for resume-like flows or remote snapshot clients. |
| `options` | The sandbox client needs creation-time options. | Common for Docker images, provider timeouts, and similar client-specific settings. |
`concurrencyLimits` controls how much sandbox materialization work can run in parallel. Use `manifestEntries` and `localDirFiles` when large manifests or local directory copies need tighter resource control.
### Materialization controls
[Section titled “Materialization controls”](#materialization-controls)
Materialization controls are intentionally per-run. Keep them near the `sandbox` run option so the same `SandboxAgent` can use conservative limits for large local directory copies and looser limits for small manifests.
Use `concurrencyLimits.manifestEntries` when a manifest has many independent entries such as files, directories, repos, and mounts. Use `concurrencyLimits.localDirFiles` when `localDir()` entries contain many files and local copy pressure needs to be capped.
## Full example: coding task
[Section titled “Full example: coding task”](#full-example-coding-task)
This coding-style example is a good default starting point:
Sandbox coding task
```typescript
import { run } from '@openai/agents';
import {
Capabilities,
Manifest,
SandboxAgent,
localDir,
skills,
} from '@openai/agents/sandbox';
import {
UnixLocalSandboxClient,
localDirLazySkillSource,
} from '@openai/agents/sandbox/local';
import { dirname, join } from 'node:path';
import { fileURLToPath } from 'node:url';
const exampleDir = dirname(fileURLToPath(import.meta.url));
const hostRepoDir = join(exampleDir, 'repo');
const hostSkillsDir = join(exampleDir, 'skills');
const manifest = new Manifest({
entries: {
repo: localDir({ src: hostRepoDir }),
},
});
const agent = new SandboxAgent({
name: 'Sandbox engineer',
model: 'gpt-5.5',
instructions:
'Read `repo/task.md` before editing files. Load the `$invoice-total-fixer` skill before changing code. Stay grounded in the repository, preserve existing behavior, and mention the exact verification command you ran. If you edit files with apply_patch, paths are relative to the sandbox workspace root.',
defaultManifest: manifest,
capabilities: [
...Capabilities.default(),
skills({
lazyFrom: localDirLazySkillSource({
src: hostSkillsDir,
}),
}),
],
});
const result = await run(
agent,
'Open `repo/task.md`, fix the issue, run the targeted test, and summarize the change.',
{
sandbox: {
client: new UnixLocalSandboxClient(),
},
},
);
console.log(result.finalOutput);
```
## Common patterns
[Section titled “Common patterns”](#common-patterns)
Start from the full example above. In many cases, the same `SandboxAgent` can stay intact while only the sandbox client, sandbox-session source, or workspace source changes.
### Switch sandbox clients
[Section titled “Switch sandbox clients”](#switch-sandbox-clients)
Keep the agent definition the same and change only the run config. Use Docker when you want container isolation or image parity, or a hosted provider when you want provider-managed execution. See [Sandbox clients](/openai-agents-js/guides/sandbox-agents/clients) for examples and provider options.
### Override the workspace
[Section titled “Override the workspace”](#override-the-workspace)
Keep the agent definition the same and swap only the fresh-session manifest with `sandbox: { client, manifest }`. Use this when the same agent role should run against different repos, packets, or task bundles without rebuilding the agent.
### Inject a sandbox session
[Section titled “Inject a sandbox session”](#inject-a-sandbox-session)
Inject a live sandbox session when you need explicit lifecycle control, post-run inspection, or output copying. Use `sandbox: { session }` for that run, and close the session in your application code.
### Resume from session state
[Section titled “Resume from session state”](#resume-from-session-state)
If you already serialized sandbox state outside `RunState`, let the runner reconnect from that state with `sandbox: { client, sessionState }`. Use this when sandbox state lives in your own storage or job system and you want `Runner` to resume from it directly.
### Start from a snapshot
[Section titled “Start from a snapshot”](#start-from-a-snapshot)
Seed a new sandbox from saved files and artifacts with `sandbox: { client, snapshot }`. Use this when a fresh run should start from saved workspace contents rather than only `agent.defaultManifest`.
### Load skills from Git
[Section titled “Load skills from Git”](#load-skills-from-git)
Swap the local skill source for a repository-backed one with `skills({ from: gitRepo(...) })`. Use this when the skills bundle has its own release cadence or should be shared across sandboxes.
### Expose as tools
[Section titled “Expose as tools”](#expose-as-tools)
Tool-agents can either get their own sandbox boundary or reuse a live sandbox from the parent run. Reuse is useful for a fast read-only explorer agent: it can inspect the exact workspace the parent is using without paying to create, hydrate, or snapshot another sandbox.
When a tool-agent needs real isolation instead, give it its own `runConfig` through `sandboxAgent.asTool(...)`. Use a separate sandbox when the tool-agent should mutate freely, run untrusted commands, or use a different backend or image.
### Combine with local tools and MCP
[Section titled “Combine with local tools and MCP”](#combine-with-local-tools-and-mcp)
Keep the sandbox workspace while still using ordinary tools on the same agent. Sandbox capabilities can coexist with `tools`, `mcpServers`, handoffs, model settings, and output configuration.
## Memory
[Section titled “Memory”](#memory)
Use the `memory()` capability when future sandbox-agent runs should learn from prior runs. Memory is separate from the SDK’s conversational `Session` memory: it distills lessons into files inside the sandbox workspace, then later runs can read those files.
See [Agent memory](/openai-agents-js/guides/sandbox-agents/memory) for setup, read/generate behavior, multi-turn conversations, and layout isolation.
## Composition patterns
[Section titled “Composition patterns”](#composition-patterns)
Once the single-agent pattern is clear, the next design question is where the sandbox boundary belongs in a larger system.
Sandbox agents still compose with the rest of the SDK:
* [Handoffs](/openai-agents-js/guides/handoffs): hand document-heavy work from a non-sandbox intake agent into a sandbox reviewer.
* [Agents as tools](/openai-agents-js/guides/tools#agents-as-tools): expose multiple sandbox agents as tools, usually by passing a sandbox run config on each `asTool(...)` call so each tool gets its own sandbox boundary.
* [MCP](/openai-agents-js/guides/mcp) and normal function tools: sandbox capabilities can coexist with `mcpServers` and ordinary tools.
* [Running agents](/openai-agents-js/guides/running-agents): sandbox runs still use the normal `run()` and `Runner` APIs.
With a handoff, there is still one top-level run and one top-level turn loop. The active agent changes, but the run does not become nested.
With `asTool(...)`, the relationship is different. The outer orchestrator uses one outer turn to decide to call the tool, and that tool call starts a nested run for the sandbox agent. The nested run has its own turn loop, `maxTurns`, approvals, and usually its own sandbox run config. From the outer orchestrator’s point of view, all of that work still sits behind one tool invocation, so the nested turns do not increment the outer run’s turn counter.
## Further reading
[Section titled “Further reading”](#further-reading)
* [Quickstart](/openai-agents-js/guides/sandbox-agents): get one sandbox agent running.
* [Sandbox clients](/openai-agents-js/guides/sandbox-agents/clients): choose local, Docker, hosted, and mount options.
* [Agent memory](/openai-agents-js/guides/sandbox-agents/memory): preserve and reuse lessons from prior sandbox runs.
# Agent memory
> Preserve and reuse lessons from previous sandbox-agent runs.
Memory lets future sandbox-agent runs learn from prior runs. It is separate from the SDK’s conversational [Session](/openai-agents-js/guides/sessions) memory, which stores message history. Memory distills lessons from prior runs into files in the sandbox workspace, so treat generated memory artifacts as retained data and apply the same sensitivity and retention policy you use for the workspace.
Beta feature
Sandbox agents are in beta. API details, defaults, and supported capabilities may change before general availability, and more advanced features are expected over time.
Memory can reduce three kinds of cost for future runs:
1. Agent cost: If the agent took a long time to complete a workflow, the next run should need less exploration. This can reduce token usage and time to completion.
2. User cost: If the user corrected the agent or expressed a preference, future runs can remember that feedback. This can reduce human intervention.
3. Context cost: If the agent completed a task before, and the user wants to build on that task, the user should not need to find the previous thread or re-type all the context. This makes task descriptions shorter.
## Enable memory
[Section titled “Enable memory”](#enable-memory)
Add `memory()` as a capability to the sandbox agent.
Enable memory
```typescript
import {
filesystem,
Manifest,
memory,
SandboxAgent,
shell,
} from '@openai/agents/sandbox';
const manifest = new Manifest({
entries: {
'README.md': {
type: 'file',
content: '# Memory demo\n\nA workspace for follow-up runs.\n',
},
},
});
const agent = new SandboxAgent({
name: 'Memory-enabled reviewer',
model: 'gpt-5.5',
instructions:
'Inspect the workspace, verify important claims, and preserve useful lessons for follow-up runs.',
defaultManifest: manifest,
capabilities: [filesystem(), shell(), memory()],
});
```
If read is enabled, `memory()` requires `shell()`, which lets the agent read and search memory files when the injected summary is not enough. When live memory update is enabled by default, it also requires `filesystem()`, which lets the agent update `memories/MEMORY.md` if the agent discovers stale memory or the user asks it to update memory.
By default, memory artifacts are stored in the sandbox workspace under `memories/`. To reuse them in a later run, preserve and reuse the whole configured memories directory by keeping the same live sandbox session or resuming from a persisted session state or snapshot; a fresh empty sandbox starts with empty memory.
`memory()` enables both reading and generating memories. Use `memory({ generate: false })` for agents that should read memory but should not generate new memories: for example, an internal agent, subagent, checker, or one-off tool agent whose run does not add much signal. Use `memory({ read: null })` when the run should generate memory for later, but the user does not want the run to be influenced by existing memory.
Configure read-only memory
```typescript
import { memory } from '@openai/agents/sandbox';
const readOnlyMemory = memory({
read: { liveUpdate: false },
generate: false,
});
```
## Read memory
[Section titled “Read memory”](#read-memory)
Memory reads use progressive disclosure. At the start of a run, the SDK injects a small summary (`memory_summary.md`) of generally useful tips, user preferences, and available memories into the agent’s developer prompt. This gives the agent enough context to decide whether prior work may be relevant.
When prior work looks relevant, the agent searches the configured memory index (`MEMORY.md` under `memoriesDir`) for keywords from the current task. It opens the corresponding prior rollout summaries under the configured `rollout_summaries/` directory only when the task needs more detail.
Memory can become stale. Agents are instructed to treat memories as guidance only and trust the current environment. By default, memory reads have `liveUpdate` enabled, so if the agent discovers stale memory, it can update the configured `MEMORY.md` in the same run. Disable live updates when the agent should read memory but not modify it during the run, for example if the run is latency sensitive.
## Generate memory
[Section titled “Generate memory”](#generate-memory)
After a run finishes, the sandbox runtime appends that run segment to a conversation file. Accumulated conversation files are processed when the sandbox session closes. These conversation files can include user input, assistant and tool items, interruptions, and final outputs, so use an appropriate memory store and retention policy for sensitive workloads.
Memory generation has two phases:
1. Phase 1: conversation extraction. A memory-generating model processes one accumulated conversation file and generates a conversation summary. System, developer, and reasoning content are omitted. If the conversation is too long, it is truncated to fit within the context window, with the beginning and end preserved. It also generates a raw memory extract: compact notes from the conversation that Phase 2 can consolidate.
2. Phase 2: layout consolidation. A consolidation agent reads raw memories for one memory layout, opens conversation summaries when more evidence is needed, and extracts patterns into `MEMORY.md` and `memory_summary.md`.
The default workspace layout is:
```text
workspace/
├── sessions/
│ └── .jsonl
└── memories/
├── memory_summary.md
├── MEMORY.md
├── raw_memories.md
├── raw_memories/
└── rollout_summaries/
```
You can configure memory generation with `memory({ generate: ... })`:
Configure memory generation
```typescript
import { memory } from '@openai/agents/sandbox';
const memoryCapability = memory({
generate: {
maxRawMemoriesForConsolidation: 128,
phaseOneModel: 'gpt-5.4-mini',
phaseTwoModel: 'gpt-5.4',
extraPrompt:
'Prioritize workflow corrections, verification commands, and user preferences.',
},
});
```
Use `extraPrompt` to tell the memory generator which signals matter most for your use case, such as customer and company details for a GTM agent.
If recent raw memories exceed `maxRawMemoriesForConsolidation`, Phase 2 keeps only memories from the newest conversations and removes older ones. Recency is based on the last time the conversation is updated. This forgetting mechanism helps memories reflect the newest environment.
## Multi-turn conversations
[Section titled “Multi-turn conversations”](#multi-turn-conversations)
For multi-turn sandbox chats, use the normal SDK `Session` together with the same live sandbox session:
Use one SDK session with one sandbox session
```typescript
import { MemorySession, run } from '@openai/agents';
import {
filesystem,
Manifest,
memory,
SandboxAgent,
shell,
} from '@openai/agents/sandbox';
import { UnixLocalSandboxClient } from '@openai/agents/sandbox/local';
const manifest = new Manifest();
const agent = new SandboxAgent({
name: 'Memory-enabled reviewer',
model: 'gpt-5.5',
instructions: 'Inspect the workspace before answering.',
capabilities: [filesystem(), shell(), memory()],
});
const conversation = new MemorySession({ sessionId: 'workspace-review' });
const sandbox = await new UnixLocalSandboxClient().create({ manifest });
try {
await run(agent, 'Analyze data/leads.csv.', {
session: conversation,
sandbox: { session: sandbox },
});
await run(agent, 'Write a follow-up recommendation.', {
session: conversation,
sandbox: { session: sandbox },
});
} finally {
await sandbox.close?.();
}
```
Both runs append to one memory conversation file because they pass the same SDK conversation session and therefore share the same session id. This is different from the sandbox, which identifies the live workspace and is not used as the memory conversation ID. Phase 1 sees the accumulated conversation when the sandbox session closes, so it can extract memory from the whole exchange instead of two isolated turns.
If you want multiple `run(...)` calls to become one memory conversation, pass a stable identifier across those calls. When memory associates a run with a conversation, it resolves in this order:
1. `conversationId`, when you pass one to `run(...)`.
2. the SDK `session` id, when you pass an SDK `Session`.
3. `groupId`, when neither of the above is present.
4. a generated per-run ID, when no stable identifier is present.
## Use different layouts to isolate memory for different agents
[Section titled “Use different layouts to isolate memory for different agents”](#use-different-layouts-to-isolate-memory-for-different-agents)
Memory isolation is based on `MemoryLayoutConfig`, not on agent name. Agents with the same layout and the same memory conversation ID share one memory conversation and one consolidated memory. Agents with different layouts keep separate rollout files, raw memories, `MEMORY.md`, and `memory_summary.md`, even when they share the same sandbox workspace.
Use separate layouts when multiple agents share one sandbox but should not share memory:
Use separate memory layouts
```typescript
import { memory } from '@openai/agents/sandbox';
const engineeringMemory = memory({
layout: {
memoriesDir: 'memories/engineering',
sessionsDir: 'sessions/engineering',
},
});
const financeMemory = memory({
layout: {
memoriesDir: 'memories/finance',
sessionsDir: 'sessions/finance',
},
});
```
This prevents one domain’s analysis from being consolidated into another domain’s memory, and vice versa.
# Sessions
> Persist multi-turn conversation history so agents can resume context across runs.
Sessions give the Agents SDK a **persistent memory layer**. Provide any object that implements the `Session` interface to `Runner.run`, and the SDK handles the rest. When a session is present, the runner automatically:
1. Fetches previously stored conversation items and prepends them to the next turn.
2. Persists new user input and assistant output after each run completes.
3. Keeps the session available for future turns, whether you call the runner with new user text or resume from an interrupted `RunState`.
This removes the need to manually call `toInputList()` or stitch history between turns. The TypeScript SDK ships with two implementations: `OpenAIConversationsSession` for the Conversations API and `MemorySession`, which is intended for local development. Because they share the `Session` interface, you can plug in your own storage backend. For inspiration beyond the Conversations API, explore the sample session backends under `examples/memory/` (Prisma, file-backed, and more). When you use an OpenAI Responses model, wrap any session with `OpenAIResponsesCompactionSession` to automatically shrink stored conversation history via [`responses.compact`](https://platform.openai.com/docs/api-reference/responses/compact).
> Tip: To run the `OpenAIConversationsSession` examples on this page, set the `OPENAI_API_KEY` environment variable (or provide an `apiKey` when constructing the session) so the SDK can call the Conversations API.
Use sessions when you want the SDK to manage client-side memory for you. If you are already using OpenAI server-managed state with `conversationId` or `previousResponseId`, you usually do not also need a session for the same conversation history.
***
## Getting started
[Section titled “Getting started”](#getting-started)
### Quick start
[Section titled “Quick start”](#quick-start)
Use `OpenAIConversationsSession` to sync memory with the [Conversations API](https://platform.openai.com/docs/api-reference/conversations), or swap in any other `Session` implementation.
Use the Conversations API as session memory
```typescript
import { Agent, OpenAIConversationsSession, run } from '@openai/agents';
const agent = new Agent({
name: 'TourGuide',
instructions: 'Answer with compact travel facts.',
});
// Any object that implements the Session interface works here. This example uses
// the built-in OpenAIConversationsSession, but you can swap in a custom Session.
const session = new OpenAIConversationsSession();
const firstTurn = await run(agent, 'What city is the Golden Gate Bridge in?', {
session,
});
console.log(firstTurn.finalOutput); // "San Francisco"
const secondTurn = await run(agent, 'What state is it in?', { session });
console.log(secondTurn.finalOutput); // "California"
```
Reusing the same session instance ensures the agent receives the full conversation history before every turn and automatically persists new items. Switching to a different `Session` implementation requires no other code changes.
For local demos, tests, or process-local chat state, `MemorySession` provides the same interface without talking to OpenAI:
Use MemorySession for local state
```typescript
import { Agent, MemorySession, run } from '@openai/agents';
const agent = new Agent({
name: 'TourGuide',
instructions: 'Answer with compact travel facts.',
});
const session = new MemorySession();
const result = await run(agent, 'What city is the Golden Gate Bridge in?', {
session,
});
console.log(result.finalOutput);
```
`OpenAIConversationsSession` constructor options:
| Option | Type | Notes |
| ---------------- | -------- | -------------------------------------------------------------- |
| `conversationId` | `string` | Reuse an existing conversation instead of creating one lazily. |
| `client` | `OpenAI` | Pass a preconfigured OpenAI client. |
| `apiKey` | `string` | API key used when creating an internal OpenAI client. |
| `baseURL` | `string` | Base URL for OpenAI-compatible endpoints. |
| `organization` | `string` | OpenAI organization ID for requests. |
| `project` | `string` | OpenAI project ID for requests. |
`MemorySession` constructor options:
| Option | Type | Notes |
| -------------- | ------------------ | ------------------------------------------------------------------------ |
| `sessionId` | `string` | Stable identifier for logs or tests. Generated automatically by default. |
| `initialItems` | `AgentInputItem[]` | Seed the session with existing history. |
| `logger` | `Logger` | Override the logger used for debug output. |
`MemorySession` stores everything in local process memory, so it is reset when your process exits.
If you need to pre-create a conversation ID before constructing the session, use `startOpenAIConversationsSession(client?)` and pass the returned ID as `conversationId`.
***
## Core session behavior
[Section titled “Core session behavior”](#core-session-behavior)
### How the runner uses sessions
[Section titled “How the runner uses sessions”](#how-the-runner-uses-sessions)
* **Before each run** it retrieves the session history, merges it with the new turn’s input, and passes the combined list to your agent.
* **After a non-streaming run** one call to `session.addItems()` persists both the original user input and the model outputs from the latest turn.
* **For streaming runs** it writes the user input first and appends streamed outputs once the turn completes.
* **When resuming from `RunResult.state`** (for approvals or other interruptions) keep passing the same `session`. The resumed turn is added to memory without re-preparing the input.
***
### Inspecting and editing history
[Section titled “Inspecting and editing history”](#inspecting-and-editing-history)
Sessions expose simple CRUD helpers so you can build “undo”, “clear chat”, or audit features.
Read and edit stored items
```typescript
import { OpenAIConversationsSession } from '@openai/agents';
import type { AgentInputItem } from '@openai/agents-core';
// Replace OpenAIConversationsSession with any other Session implementation that
// supports get/add/pop/clear if you store history elsewhere.
const session = new OpenAIConversationsSession({
conversationId: 'conv_123', // Resume an existing conversation if you have one.
});
const history = await session.getItems();
console.log(`Loaded ${history.length} prior items.`);
const followUp: AgentInputItem[] = [
{
type: 'message',
role: 'user',
content: [{ type: 'input_text', text: 'Let’s continue later.' }],
},
];
await session.addItems(followUp);
const undone = await session.popItem();
if (undone?.type === 'message') {
console.log(undone.role); // "user"
}
await session.clearSession();
```
`session.getItems()` returns the stored `AgentInputItem[]`. Call `popItem()` to remove the last entry—useful for user corrections before you rerun the agent.
***
## Custom storage and merge behavior
[Section titled “Custom storage and merge behavior”](#custom-storage-and-merge-behavior)
### Bring your own storage
[Section titled “Bring your own storage”](#bring-your-own-storage)
Implement the `Session` interface to back memory with Redis, DynamoDB, SQLite, or another datastore. Only five asynchronous methods are required.
Custom in-memory session implementation
```typescript
import { Agent, run } from '@openai/agents';
import { randomUUID } from '@openai/agents-core/_shims';
import { getLogger } from '@openai/agents-core';
import type { AgentInputItem, Session } from '@openai/agents-core';
/**
* Minimal example of a Session implementation; swap this class for any storage-backed version.
*/
export class CustomMemorySession implements Session {
private readonly sessionId: string;
private readonly logger: ReturnType;
private items: AgentInputItem[];
constructor(
options: {
sessionId?: string;
initialItems?: AgentInputItem[];
logger?: ReturnType;
} = {},
) {
this.sessionId = options.sessionId ?? randomUUID();
this.items = options.initialItems
? options.initialItems.map(cloneAgentItem)
: [];
this.logger = options.logger ?? getLogger('openai-agents:memory-session');
}
async getSessionId(): Promise {
return this.sessionId;
}
async getItems(limit?: number): Promise {
if (limit === undefined) {
const cloned = this.items.map(cloneAgentItem);
this.logger.debug(
`Getting items from memory session (${this.sessionId}): ${JSON.stringify(cloned)}`,
);
return cloned;
}
if (limit <= 0) {
return [];
}
const start = Math.max(this.items.length - limit, 0);
const items = this.items.slice(start).map(cloneAgentItem);
this.logger.debug(
`Getting items from memory session (${this.sessionId}): ${JSON.stringify(items)}`,
);
return items;
}
async addItems(items: AgentInputItem[]): Promise {
if (items.length === 0) {
return;
}
const cloned = items.map(cloneAgentItem);
this.logger.debug(
`Adding items to memory session (${this.sessionId}): ${JSON.stringify(cloned)}`,
);
this.items = [...this.items, ...cloned];
}
async popItem(): Promise {
if (this.items.length === 0) {
return undefined;
}
const item = this.items[this.items.length - 1];
const cloned = cloneAgentItem(item);
this.logger.debug(
`Popping item from memory session (${this.sessionId}): ${JSON.stringify(cloned)}`,
);
this.items = this.items.slice(0, -1);
return cloned;
}
async clearSession(): Promise {
this.logger.debug(`Clearing memory session (${this.sessionId})`);
this.items = [];
}
}
function cloneAgentItem(item: T): T {
return structuredClone(item);
}
const agent = new Agent({
name: 'MemoryDemo',
instructions: 'Remember the running total.',
});
// Using the above custom memory session implementation here
const session = new CustomMemorySession({
sessionId: 'session-123-4567',
});
const first = await run(agent, 'Add 3 to the total.', { session });
console.log(first.finalOutput);
const second = await run(agent, 'Add 4 more.', { session });
console.log(second.finalOutput);
```
Custom sessions let you enforce retention policies, add encryption, or attach metadata to each conversation turn before persisting it.
***
### Control how history and new items merge
[Section titled “Control how history and new items merge”](#control-how-history-and-new-items-merge)
When you pass an array of `AgentInputItem`s as the run input, provide a `sessionInputCallback` to merge them with stored history deterministically. The runner loads the existing history, calls your callback **before the model invocation**, and hands the returned array to the model as the turn’s complete input. This hook is ideal for trimming old items, deduplicating tool results, or highlighting only the context you want the model to see.
Truncate history with sessionInputCallback
```typescript
import { Agent, OpenAIConversationsSession, run } from '@openai/agents';
import type { AgentInputItem } from '@openai/agents-core';
const agent = new Agent({
name: 'Planner',
instructions: 'Track outstanding tasks before responding.',
});
// Any Session implementation can be passed here; customize storage as needed.
const session = new OpenAIConversationsSession();
const todoUpdate: AgentInputItem[] = [
{
type: 'message',
role: 'user',
content: [
{ type: 'input_text', text: 'Add booking a hotel to my todo list.' },
],
},
];
await run(agent, todoUpdate, {
session,
// function that combines session history with new input items before the model call
sessionInputCallback: (history, newItems) => {
const recentHistory = history.slice(-8);
return [...recentHistory, ...newItems];
},
});
```
For string inputs the runner merges history automatically, so the callback is optional. The callback only runs when your turn input is already an item array.
If you are also using `conversationId` or `previousResponseId`, keep at least one new item from the current turn in the callback result. Those server-managed APIs depend on the current-turn delta. If the callback drops every new item, the SDK restores the original new inputs and logs a warning instead of sending an empty delta.
***
## Resumable runs
[Section titled “Resumable runs”](#resumable-runs)
### Handling approvals and resumable runs
[Section titled “Handling approvals and resumable runs”](#handling-approvals-and-resumable-runs)
Human-in-the-loop flows often pause a run to wait for approval:
Resume a run with the same session
```typescript
import { Agent, MemorySession, Runner } from '@openai/agents';
const agent = new Agent({
name: 'Trip Planner',
instructions: 'Plan trips and ask for approval before booking anything.',
});
const runner = new Runner();
const session = new MemorySession();
const result = await runner.run(agent, 'Search the itinerary', {
session,
});
if (result.interruptions?.length) {
// ... collect user feedback, then resume the agent in a later turn.
for (const interruption of result.interruptions) {
result.state.approve(interruption);
}
const continuation = await runner.run(agent, result.state, { session });
console.log(continuation.finalOutput);
}
```
When you resume from a previous `RunState`, the new turn is appended to the same memory record to preserve a single conversation history. Human-in-the-loop (HITL) flows stay fully compatible—approval checkpoints still round-trip through `RunState` while the session keeps the conversation history complete.
***
## Advanced: history compaction
[Section titled “Advanced: history compaction”](#advanced-history-compaction)
### Compact OpenAI Responses history automatically
[Section titled “Compact OpenAI Responses history automatically”](#compact-openai-responses-history-automatically)
`OpenAIResponsesCompactionSession` decorates any `Session` and uses the OpenAI Responses API to replace a long stored history with a shorter equivalent list of conversation items. After each persisted turn the runner passes the latest `responseId` into `runCompaction`, which calls `responses.compact` when your decision hook returns true. Depending on `compactionMode`, the request is built either from the latest Responses API chain or from the session’s current items. The default trigger compacts once at least 10 non-user items have accumulated; override `shouldTriggerCompaction` to base the decision on token counts or custom heuristics. After compaction returns, the decorator clears the underlying session and rewrites it with the reduced item list, so avoid pairing it with `OpenAIConversationsSession`, which uses a different server-managed history flow.
Decorate a session with OpenAIResponsesCompactionSession
```typescript
import {
Agent,
MemorySession,
OpenAIResponsesCompactionSession,
run,
} from '@openai/agents';
const agent = new Agent({
name: 'Support',
instructions: 'Answer briefly and keep track of prior context.',
model: 'gpt-5.4',
});
// Wrap any Session to trigger responses.compact once history grows beyond your threshold.
const session = new OpenAIResponsesCompactionSession({
// You can pass any Session implementation except OpenAIConversationsSession
underlyingSession: new MemorySession(),
// (optional) The model used for calling responses.compact API
model: 'gpt-5.4',
// (optional) your custom logic here
shouldTriggerCompaction: ({ compactionCandidateItems }) => {
return compactionCandidateItems.length >= 12;
},
});
await run(agent, 'Summarize order #8472 in one sentence.', { session });
await run(agent, 'Remind me of the shipping address.', { session });
// Compaction runs automatically after each persisted turn. You can also force it manually.
await session.runCompaction({ force: true });
```
`OpenAIResponsesCompactionSession` constructor options:
| Option | Type | Notes |
| ------------------------- | --------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `client` | `OpenAI` | OpenAI client used for `responses.compact`. |
| `underlyingSession` | `Session` | Backing session store to clear/rewrite with compacted items. Defaults to an in-memory session for demos and must not be `OpenAIConversationsSession`. |
| `model` | `OpenAI.ResponsesModel` | Model used for compaction requests. Defaults to the SDK’s current default OpenAI model. |
| `compactionMode` | `'auto' \| 'previous_response_id' \| 'input'` | Controls whether compaction uses server response chaining or local input items. |
| `shouldTriggerCompaction` | `(context) => boolean \| Promise` | Custom trigger hook based on `responseId`, `compactionMode`, candidate items, and current session items. |
`compactionMode: 'previous_response_id'` is useful when you are already chaining turns with Responses API response IDs. `compactionMode: 'input'` rebuilds compaction requests from the current session items instead, which is helpful when the response chain is unavailable or you want the underlying session contents to be the source of truth.
`runCompaction(args)` options:
| Option | Type | Notes |
| ---------------- | --------------------------------------------- | ----------------------------------------------------------------- |
| `responseId` | `string` | Latest Responses API response id for `previous_response_id` mode. |
| `compactionMode` | `'auto' \| 'previous_response_id' \| 'input'` | Optional per-call override of the configured mode. |
| `store` | `boolean` | Indicates whether the last run stored server state. |
| `force` | `boolean` | Bypass `shouldTriggerCompaction` and compact immediately. |
#### Manual compaction for low-latency streaming
[Section titled “Manual compaction for low-latency streaming”](#manual-compaction-for-low-latency-streaming)
Compaction clears and rewrites the underlying session, so the SDK waits for it before resolving a streaming run. If compaction is heavy, `result.completed` can stay pending for a few seconds after the last output token. For low-latency streaming or faster turn-taking, disable auto-compaction and call `runCompaction` yourself between turns (or during idle time).
Disable auto-compaction and compact between turns
```typescript
import {
Agent,
MemorySession,
OpenAIResponsesCompactionSession,
run,
} from '@openai/agents';
const agent = new Agent({
name: 'Support',
instructions: 'Answer briefly and keep track of prior context.',
model: 'gpt-5.4',
});
// Disable auto-compaction to avoid delaying stream completion.
const session = new OpenAIResponsesCompactionSession({
underlyingSession: new MemorySession(),
shouldTriggerCompaction: () => false,
});
const result = await run(agent, 'Share the latest ticket update.', {
session,
stream: true,
});
// Wait for the streaming run to finish before compacting.
await result.completed;
// Choose force based on your own thresholds or heuristics, between turns or during idle time.
await session.runCompaction({ force: true });
```
You can call `runCompaction({ force: true })` at any time to shrink history before archiving or handoff. Enable debug logs with `DEBUG=openai-agents:openai:compaction` to trace compaction decisions.
# Streaming
> Stream agent output in real time using the Runner
The Agents SDK can deliver output from the model and other execution steps incrementally. Streaming keeps your UI responsive and avoids waiting for the entire final result before updating the user.
## Enabling streaming
[Section titled “Enabling streaming”](#enabling-streaming)
Pass a `{ stream: true }` option to `Runner.run()` to obtain a streaming object rather than a full result:
Enabling streaming
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Storyteller',
instructions:
'You are a storyteller. You will be given a topic and you will tell a story about it.',
});
const result = await run(agent, 'Tell me a story about a cat.', {
stream: true,
});
```
When streaming is enabled the returned `stream` implements the `AsyncIterable` interface. Each yielded event is an object describing what happened within the run. The stream yields one of three event types, each describing a different part of the agent’s execution. Most applications only want the model’s text though, so the stream provides helpers.
### Get the text output
[Section titled “Get the text output”](#get-the-text-output)
Call `stream.toTextStream()` to obtain a stream of the emitted text. When `compatibleWithNodeStreams` is `true` the return value is a regular Node.js `Readable`. We can pipe it directly into `process.stdout` or another destination.
Logging out the text as it arrives
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Storyteller',
instructions:
'You are a storyteller. You will be given a topic and you will tell a story about it.',
});
const result = await run(agent, 'Tell me a story about a cat.', {
stream: true,
});
result
.toTextStream({
compatibleWithNodeStreams: true,
})
.pipe(process.stdout);
```
The promise `stream.completed` resolves once the run and all pending callbacks are completed. Always await it if you want to ensure there is no more output. This includes post-processing work such as session persistence or history compaction hooks that finish after the last text token arrives.
`toTextStream()` only emits assistant text. Tool calls, handoffs, approvals, and other runtime events are available from the full event stream.
### Listen to all events
[Section titled “Listen to all events”](#listen-to-all-events)
You can use a `for await` loop to inspect each event as it arrives. Useful information includes low level model events, any agent switches and SDK specific run information:
Listening to all events
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Storyteller',
instructions:
'You are a storyteller. You will be given a topic and you will tell a story about it.',
});
const result = await run(agent, 'Tell me a story about a cat.', {
stream: true,
});
for await (const event of result) {
// these are the raw events from the model
if (event.type === 'raw_model_stream_event') {
console.log(`${event.type} %o`, event.data);
}
// agent updated events
if (event.type === 'agent_updated_stream_event') {
console.log(`${event.type} %s`, event.agent.name);
}
// Agent SDK specific events
if (event.type === 'run_item_stream_event') {
console.log(`${event.type} %o`, event.item);
}
}
```
See [the streamed example](https://github.com/openai/openai-agents-js/tree/main/examples/agent-patterns/streamed.ts) for a fully worked script that prints both the plain text stream and the raw event stream.
### Responses WebSocket transport (optional)
[Section titled “Responses WebSocket transport (optional)”](#responses-websocket-transport-optional)
The streaming APIs on this page also work with the OpenAI Responses WebSocket transport.
Enable it globally with `setOpenAIResponsesTransport('websocket')`, or use your own `OpenAIProvider` with `useResponsesWebSocket: true`.
You do not need `withResponsesWebSocketSession(...)` or a custom `OpenAIProvider` just to stream over WebSocket. If reconnecting between runs is acceptable, `run()` / `Runner.run(..., { stream: true })` still works after enabling the transport.
Use `withResponsesWebSocketSession(...)` or a custom `OpenAIProvider` / `Runner` when you want connection reuse and more explicit provider lifecycle control.
Continuation with `previousResponseId` uses the same semantics as the HTTP transport. The difference is just the transport and connection lifecycle.
If you build the provider yourself, remember to call `await provider.close()` when shutting down. Websocket-backed model wrappers are cached for reuse by default, and closing the provider releases those connections. `withResponsesWebSocketSession(...)` gives you the same reuse but scopes cleanup to a single callback automatically.
See [`examples/basic/stream-ws.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/basic/stream-ws.ts) for a complete example with streaming, tool calls, approvals, and `previousResponseId`.
## Event types
[Section titled “Event types”](#event-types)
The stream yields three different event types:
### raw\_model\_stream\_event
[Section titled “raw\_model\_stream\_event”](#raw_model_stream_event)
RunRawModelStreamEvent
```typescript
import {
isOpenAIChatCompletionsRawModelStreamEvent,
isOpenAIResponsesRawModelStreamEvent,
type RunStreamEvent,
} from '@openai/agents';
export function logOpenAIRawModelEvent(event: RunStreamEvent) {
if (isOpenAIResponsesRawModelStreamEvent(event)) {
console.log(event.source);
console.log(event.data.event.type);
return;
}
if (isOpenAIChatCompletionsRawModelStreamEvent(event)) {
console.log(event.source);
console.log(event.data.event.object);
}
}
```
Example:
```json
{
"type": "raw_model_stream_event",
"data": {
"type": "output_text_delta",
"delta": "Hello"
}
}
```
If you are using the OpenAI provider, `@openai/agents-openai` and `@openai/agents` both export helpers that narrow raw OpenAI payloads without changing the generic `RunRawModelStreamEvent` contract in `agents-core`.
Narrow OpenAI raw model events
```typescript
import type { RunStreamEvent } from '@openai/agents';
import { isOpenAIResponsesRawModelStreamEvent } from '@openai/agents';
export function isOpenAIResponsesTextDelta(event: RunStreamEvent): boolean {
return (
isOpenAIResponsesRawModelStreamEvent(event) &&
event.data.event.type === 'response.output_text.delta'
);
}
```
When you only need transport-agnostic streaming code, checking `event.type === 'raw_model_stream_event'` is still enough.
If you are using OpenAI models and want to inspect provider-specific payloads without manual casts, the SDK also exports narrowing helpers:
* `isOpenAIResponsesRawModelStreamEvent(event)` for Responses raw events.
* `isOpenAIChatCompletionsRawModelStreamEvent(event)` for Chat Completions chunks.
For these OpenAI model events, `RunRawModelStreamEvent.source` is also populated with either `'openai-responses'` or `'openai-chat-completions'`.
This is especially useful when you want to inspect Responses-only events such as `response.reasoning_summary_text.delta`, `response.output_item.done`, or MCP argument deltas while keeping TypeScript aware of the underlying event shape.
See [`examples/basic/stream-ws.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/basic/stream-ws.ts), [`examples/tools/code-interpreter.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/tools/code-interpreter.ts), and [`examples/connectors/index.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/connectors) for fuller OpenAI-specific streaming patterns.
### run\_item\_stream\_event
[Section titled “run\_item\_stream\_event”](#run_item_stream_event)
RunItemStreamEvent
```typescript
import type { RunItemStreamEvent, RunStreamEvent } from '@openai/agents';
export function isRunItemStreamEvent(
event: RunStreamEvent,
): event is RunItemStreamEvent {
return event.type === 'run_item_stream_event';
}
```
`name` identifies which kind of item was produced:
| `name` | Meaning |
| ---------------------------- | --------------------------------------------------------------------- |
| `message_output_created` | A message output item was created. |
| `handoff_requested` | The model requested a handoff. |
| `handoff_occurred` | The runtime completed a handoff to another agent. |
| `tool_search_called` | A `tool_search_call` item was emitted. |
| `tool_search_output_created` | A `tool_search_output` item with loaded tool definitions was emitted. |
| `tool_called` | A tool call item was emitted. |
| `tool_output` | A tool result item was emitted. |
| `reasoning_item_created` | A reasoning item was emitted. |
| `tool_approval_requested` | A tool call paused for human approval. |
The `tool_search_*` events only appear on Responses runs that use `toolSearchTool()` to load deferred tools during the run.
Example handoff payload:
```json
{
"type": "run_item_stream_event",
"name": "handoff_occurred",
"item": {
"type": "handoff_call",
"id": "h1",
"status": "completed",
"name": "transfer_to_refund_agent"
}
}
```
### agent\_updated\_stream\_event
[Section titled “agent\_updated\_stream\_event”](#agent_updated_stream_event)
RunAgentUpdatedStreamEvent
```typescript
import type {
RunAgentUpdatedStreamEvent,
RunStreamEvent,
} from '@openai/agents';
export function isRunAgentUpdatedStreamEvent(
event: RunStreamEvent,
): event is RunAgentUpdatedStreamEvent {
return event.type === 'agent_updated_stream_event';
}
```
Example:
```json
{
"type": "agent_updated_stream_event",
"agent": {
"name": "Refund Agent"
}
}
```
## Human in the loop while streaming
[Section titled “Human in the loop while streaming”](#human-in-the-loop-while-streaming)
Streaming is compatible with handoffs that pause execution (for example when a tool requires approval). The `interruptions` field on the stream object exposes the pending approvals, and you can continue execution by calling `state.approve()` or `state.reject()` for each of them. After the stream pauses, `stream.completed` resolves and `stream.interruptions` contains the approvals to handle. Executing again with `{ stream: true }` resumes streaming output.
Handling human approval while streaming
```typescript
import { Agent, run } from '@openai/agents';
const agent = new Agent({
name: 'Storyteller',
instructions:
'You are a storyteller. You will be given a topic and you will tell a story about it.',
});
let stream = await run(
agent,
'What is the weather in San Francisco and Oakland?',
{ stream: true },
);
stream.toTextStream({ compatibleWithNodeStreams: true }).pipe(process.stdout);
await stream.completed;
while (stream.interruptions?.length) {
console.log(
'Human-in-the-loop: approval required for the following tool calls:',
);
const state = stream.state;
for (const interruption of stream.interruptions) {
const approved = confirm(
`Agent ${interruption.agent.name} would like to use the tool ${interruption.name} with "${interruption.arguments}". Do you approve?`,
);
if (approved) {
state.approve(interruption);
} else {
state.reject(interruption);
}
}
// Resume execution with streaming output
stream = await run(agent, state, { stream: true });
const textStream = stream.toTextStream({ compatibleWithNodeStreams: true });
textStream.pipe(process.stdout);
await stream.completed;
}
```
A fuller example that interacts with the user is [`human-in-the-loop-stream.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/agent-patterns/human-in-the-loop-stream.ts).
## Stop a stream and continue the same turn
[Section titled “Stop a stream and continue the same turn”](#stop-a-stream-and-continue-the-same-turn)
To stop a streaming run early, abort the `signal` you passed to `run()` or cancel a reader created from `stream.toStream()`. Either way, still await `stream.completed` before treating the run as settled. The SDK may still be persisting the current turn input or finishing other cleanup after your code stops consuming events.
When a stream is cancelled, `stream.cancelled` becomes `true`, and `stream.finalOutput` often remains `undefined` because the current turn never finished. If you want to continue that unfinished turn later, rerun the same agent with `stream.state` instead of appending a fresh user message. That keeps turn counting correct and reuses any `conversationId` or `previousResponseId` already stored in the `RunState`.
If you are also using session persistence, pass the same `session` again on the resumed `run()` call so the conversation keeps writing to the same backing store.
Approval pauses follow the same rule: resolve `stream.interruptions`, then resume from `stream.state` rather than starting a new turn.
## Tips
[Section titled “Tips”](#tips)
* Remember to wait for `stream.completed` before exiting to ensure all output has been flushed.
* The initial `{ stream: true }` option only applies to the call where it is provided. If you re-run with a `RunState` you must specify the option again.
* If your application only cares about the textual result prefer `toTextStream()` to avoid dealing with individual event objects.
With streaming and the event system you can integrate an agent into a chat interface, terminal application or any place where users benefit from incremental updates.
# Tools
> Provide your agents with capabilities via hosted tools or custom function tools
Tools let an Agent **take actions** – fetch data, call external APIs, execute code, or even use a computer. The JavaScript/TypeScript SDK supports seven categories:
> Read this page after [Agents](/openai-agents-js/guides/agents) once you know which agent should own the task and you want to give it capabilities. If you are still deciding between delegation patterns, see [Agent orchestration](/openai-agents-js/guides/multi-agent).
1. **Hosted OpenAI tools** – run alongside the model on OpenAI servers. *(web search, file search, code interpreter, image generation, tool search)*
2. **Built-in execution tools** – SDK-provided tools that execute outside the model. *(computer use and apply\_patch run locally; shell can run locally or in hosted containers)*
3. **Function tools** – wrap any local function with a JSON schema so the LLM can call it.
4. **Agents as tools** – expose an entire Agent as a callable tool.
5. **MCP servers** – attach a Model Context Protocol server (local or remote).
6. **Sandbox capabilities** – attach workspace-scoped shell, filesystem, skills, memory, or compaction tools to a `SandboxAgent`.
7. **Experimental: Codex tool** – wrap the Codex SDK as a function tool to run workspace-aware tasks.
***
## Tool categories
[Section titled “Tool categories”](#tool-categories)
The rest of this guide first covers each tool category, then summarizes cross-cutting tool selection and prompting guidance.
### 1. Hosted tools (OpenAI Responses API)
[Section titled “1. Hosted tools (OpenAI Responses API)”](#1-hosted-tools-openai-responses-api)
When you use the `OpenAIResponsesModel` you can add the following built‑in tools:
| Tool | Type string | Purpose |
| ----------------------- | -------------------- | ----------------------------------------------------------------------------- |
| Web search | `'web_search'` | Internet search. |
| File / retrieval search | `'file_search'` | Query vector stores hosted on OpenAI. |
| Code Interpreter | `'code_interpreter'` | Run code in a sandboxed environment. |
| Image generation | `'image_generation'` | Generate images based on text. |
| Tool search | `'tool_search'` | Load deferred function tools, namespaces, or searchable MCP tools at runtime. |
Hosted tools
```typescript
import {
Agent,
codeInterpreterTool,
fileSearchTool,
imageGenerationTool,
webSearchTool,
} from '@openai/agents';
const agent = new Agent({
name: 'Travel assistant',
tools: [
webSearchTool({ searchContextSize: 'medium' }),
fileSearchTool('VS_ID', { maxNumResults: 3 }),
codeInterpreterTool(),
imageGenerationTool({ size: '1024x1024' }),
],
});
```
The SDK provides helper functions that return hosted tool definitions:
| Helper function | Notes |
| ------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `webSearchTool(options?)` | JS-friendly options such as `searchContextSize`, `userLocation`, and `filters.allowedDomains`. |
| `fileSearchTool(ids, options?)` | Accepts one or more vector store IDs as the first argument, plus options like `maxNumResults`, `includeSearchResults`, `rankingOptions`, and filters. |
| `codeInterpreterTool(options?)` | Defaults to an auto-managed container when no `container` is provided. |
| `imageGenerationTool(options?)` | Supports image generation configuration such as `model`, `size`, `quality`, `background`, `inputFidelity`, `inputImageMask`, `moderation`, `outputCompression`, `partialImages`, and output format. |
| `toolSearchTool(options?)` | Adds the built-in `tool_search` helper. Pair it with deferred function tools or hosted MCP tools that set `deferLoading: true`. Supports hosted execution by default or client execution with `execution: 'client'` plus `execute`. |
These helpers map JavaScript/TypeScript-friendly option names to the underlying OpenAI Responses API tool payloads. Refer to the official [OpenAI tools guide](https://developers.openai.com/api/docs/guides/tools) for the full tool schemas and advanced options like ranking options or semantic filters, and the official [Tool search guide](https://developers.openai.com/api/docs/guides/tools-tool-search) for the current built-in tool-search flow and model availability.
***
### 2. Built-in execution tools
[Section titled “2. Built-in execution tools”](#2-built-in-execution-tools)
These tools are built into the SDK, but execution happens outside the model response itself:
* **Computer use** – implement the `Computer` interface and pass it to `computerTool()`. This always runs against a local `Computer` implementation that you provide.
* **Shell** – either provide a local `Shell` implementation, or configure a hosted container environment with `shellTool({ environment })`.
* **Apply patch** – implement the `Editor` interface and pass it to `applyPatchTool()`. This always runs against a local `Editor` implementation that you provide.
* **Sandbox shell and filesystem tools** – use `shell()`, `filesystem()`, `skills()`, `memory()`, or `compaction()` on a `SandboxAgent` when those actions should run inside a sandbox workspace.
The tool calls are still requested by the model, but your application or configured execution environment performs the work.
Sandbox capability tools are different from process-wide built-in tools: they are bound to the live sandbox session for the current `SandboxAgent` run. Use [Sandbox agents](/openai-agents-js/guides/sandbox-agents) when the tool should operate on the agent’s isolated workspace instead of your application process.
Built-in execution tools
```typescript
import {
Agent,
applyPatchTool,
computerTool,
shellTool,
Computer,
Editor,
Shell,
} from '@openai/agents';
const computer: Computer = {
environment: 'browser',
dimensions: [1024, 768],
screenshot: async () => '',
click: async () => {},
doubleClick: async () => {},
scroll: async () => {},
type: async () => {},
wait: async () => {},
move: async () => {},
keypress: async () => {},
drag: async () => {},
};
const shell: Shell = {
run: async () => ({
output: [
{
stdout: '',
stderr: '',
outcome: { type: 'exit', exitCode: 0 },
},
],
}),
};
const editor: Editor = {
createFile: async () => ({ status: 'completed' }),
updateFile: async () => ({ status: 'completed' }),
deleteFile: async () => ({ status: 'completed' }),
};
const agent = new Agent({
name: 'Local tools agent',
model: 'gpt-5.4',
tools: [
computerTool({ computer }),
shellTool({ shell, needsApproval: true }),
applyPatchTool({ editor, needsApproval: true }),
],
});
```
#### Computer tool specifics
[Section titled “Computer tool specifics”](#computer-tool-specifics)
`computerTool()` accepts either:
* A concrete `Computer` instance.
* An initializer function that creates a `Computer` per run.
* A provider object with `{ create, dispose }` when you need run-scoped setup and teardown.
To use OpenAI’s current computer-use path, set a computer-capable model such as [`gpt-5.4`](https://developers.openai.com/api/docs/models/gpt-5.4). When the request model is explicit, the SDK sends the GA built-in `computer` tool shape. If the effective model still comes from a stored prompt or another older integration, the SDK keeps the legacy `computer_use_preview` wire shape for compatibility unless you explicitly opt into the GA path with `modelSettings.toolChoice: 'computer'`.
GA computer calls can contain batched `actions[]` in a single `computer_call`. The SDK executes them in order, evaluates `needsApproval` against each action, and returns the final screenshot as the tool output. If you build an approval UI from `interruption.rawItem`, read `actions` when present and fall back to `action` for legacy preview items.
Use `needsApproval` when high-impact computer actions should pause for user review, and `onSafetyCheck` when you want to acknowledge or reject the pending safety checks reported for a computer call. For model-side guidance and migration details, see the official [OpenAI computer use guide](https://developers.openai.com/api/docs/guides/tools-computer-use/) and its [migration note](https://developers.openai.com/api/docs/guides/tools-computer-use/#migration-from-computer-use-preview).
#### Shell tool specifics
[Section titled “Shell tool specifics”](#shell-tool-specifics)
`shellTool()` has two modes:
* Local mode: provide `shell`, and optionally `environment: { type: 'local', skills }` plus `needsApproval` and `onApproval` for automatic approval handling.
* Hosted container mode: provide `environment` with `type: 'container_auto'` or `type: 'container_reference'`.
In local mode, `environment.skills` lets you mount local skills by `name`, `description`, and filesystem `path`.
In hosted container mode, configure `shellTool({ environment })` with either:
* `type: 'container_auto'` to create a managed container for the run.
* `type: 'container_reference'` to reuse an existing container by `containerId`.
Hosted `container_auto` environments support:
* `networkPolicy`, including allowlists with `domainSecrets`.
* `fileIds` for mounting uploaded files.
* `memoryLimit` for container sizing.
* `skills`, either by `skill_reference` or inline zip bundles.
Hosted shell environments do not accept `shell`, `needsApproval`, or `onApproval`, because the execution happens in the hosted container environment instead of your local process.
See `examples/tools/local-shell.ts`, `examples/tools/container-shell-skill-ref.ts`, and `examples/tools/container-shell-inline-skill.ts` for end-to-end usage.
#### Apply-patch tool specifics
[Section titled “Apply-patch tool specifics”](#apply-patch-tool-specifics)
`applyPatchTool()` mirrors the local approval flow from `shellTool()`: use `needsApproval` to pause before file edits and `onApproval` when you want an app-level callback to auto-approve or reject.
***
### 3. Function tools
[Section titled “3. Function tools”](#3-function-tools)
You can turn **any** function into a tool with the `tool()` helper.
Function tool with Zod parameters
```typescript
import { tool } from '@openai/agents';
import { z } from 'zod';
const getWeatherTool = tool({
name: 'get_weather',
description: 'Get the weather for a given city',
parameters: z.object({ city: z.string() }),
async execute({ city }) {
return `The weather in ${city} is sunny.`;
},
});
```
#### Options reference
[Section titled “Options reference”](#options-reference)
| Field | Required | Description |
| ---------------------- | -------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `name` | No | Defaults to the function name (e.g., `get_weather`). |
| `description` | Yes | Clear, human-readable description shown to the LLM. |
| `parameters` | Yes | Either a Zod schema or a raw JSON schema object. Zod parameters automatically enable **strict** mode. |
| `strict` | No | When `true` (default), the SDK returns a model error if the arguments don’t validate. Set to `false` for fuzzy matching. |
| `execute` | Yes | `(args, context, details) => string \| unknown \| Promise<...>` – your business logic. Non-string outputs are serialized for the model. `context` is optional `RunContext`; `details` includes metadata like `toolCall`, `resumeState`, and `signal`. |
| `errorFunction` | No | Custom handler `(context, error) => string` for transforming internal errors into a user-visible string. |
| `timeoutMs` | No | Per-call timeout in milliseconds. Must be greater than 0 and less than or equal to `2147483647`. |
| `timeoutBehavior` | No | Timeout mode: `error_as_result` (default) returns a model-visible timeout message, and `raise_exception` throws `ToolTimeoutError`. |
| `timeoutErrorFunction` | No | Custom handler `(context, timeoutError) => string` for timeout output when `timeoutBehavior` is `error_as_result`. |
| `needsApproval` | No | Require human approval before execution. See the [human-in-the-loop guide](/openai-agents-js/guides/human-in-the-loop). |
| `isEnabled` | No | Conditionally expose the tool per run; accepts a boolean or predicate. |
| `inputGuardrails` | No | Guardrails that run before the tool executes; can reject or throw. See [Guardrails](/openai-agents-js/guides/guardrails#tool-guardrails). |
| `outputGuardrails` | No | Guardrails that run after the tool executes; can reject or throw. See [Guardrails](/openai-agents-js/guides/guardrails#tool-guardrails). |
#### Function tool timeouts
[Section titled “Function tool timeouts”](#function-tool-timeouts)
Use `timeoutMs` to bound each function tool invocation.
* `timeoutBehavior: 'error_as_result'` (default) returns `Tool '' timed out after ms.` to the model.
* `timeoutBehavior: 'raise_exception'` throws [`ToolTimeoutError`](/openai-agents-js/openai/agents-core/classes/tooltimeouterror), which you can catch as part of [run exceptions](/openai-agents-js/guides/running-agents#exceptions).
* `timeoutErrorFunction` lets you customize timeout text in `error_as_result` mode.
* Timeouts abort `details.signal`, so long-running tools can stop promptly when they listen for cancellation.
If you invoke a function tool directly, use [`invokeFunctionTool`](/openai-agents-js/openai/agents/functions/invokefunctiontool) to enforce the same timeout behavior as normal agent runs.
#### Non‑strict JSON‑schema tools
[Section titled “Non‑strict JSON‑schema tools”](#nonstrict-jsonschema-tools)
If you need the model to *guess* invalid or partial input you can disable strict mode when using raw JSON schema:
Non-strict JSON schema tools
```typescript
import { tool } from '@openai/agents';
interface LooseToolInput {
text: string;
}
const looseTool = tool({
description: 'Echo input; be forgiving about typos',
strict: false,
parameters: {
type: 'object',
properties: { text: { type: 'string' } },
required: ['text'],
additionalProperties: true,
},
execute: async (input) => {
// because strict is false we need to do our own verification
if (typeof input !== 'object' || input === null || !('text' in input)) {
return 'Invalid input. Please try again';
}
return (input as LooseToolInput).text;
},
});
```
#### Deferred tool loading with tool search
[Section titled “Deferred tool loading with tool search”](#deferred-tool-loading-with-tool-search)
Tool search lets the model load only the tool definitions it needs at runtime instead of sending every schema up front. In the SDK, this is how you work with deferred top-level function tools, `toolNamespace()` groups, and hosted MCP tools configured with `deferLoading: true`.
Use Tool search only with GPT-5.4 and newer model releases that support it in the Responses API.
Deferred tool loading with tool search
```typescript
import { Agent, tool, toolNamespace, toolSearchTool } from '@openai/agents';
import { z } from 'zod';
const customerIdParams = z.object({
customerId: z.string().describe('The customer identifier to look up.'),
});
// Keep a standalone deferred tool at the top level when it represents a
// single searchable capability that does not need a shared namespace.
const shippingLookup = tool({
name: 'get_shipping_eta',
description: 'Look up a shipment ETA by customer identifier.',
parameters: customerIdParams,
deferLoading: true,
async execute({ customerId }) {
return {
customerId,
eta: '2026-03-07',
carrier: 'Priority Express',
};
},
});
// Group related tools into a namespace when one domain description should
// cover several deferred tools and let tool search load them together.
const crmTools = toolNamespace({
name: 'crm',
description: 'CRM tools for customer profile lookups.',
tools: [
tool({
name: 'get_customer_profile',
description: 'Fetch a basic customer profile.',
parameters: customerIdParams,
deferLoading: true,
async execute({ customerId }) {
return {
customerId,
tier: 'enterprise',
};
},
}),
],
});
const agent = new Agent({
name: 'Operations assistant',
model: 'gpt-5.4',
// Mixing namespaced and top-level deferred tools in one request is supported.
tools: [shippingLookup, ...crmTools, toolSearchTool()],
});
```
The example intentionally mixes both styles:
* `shippingLookup` stays top-level because it is one standalone searchable capability.
* `crmTools` uses `toolNamespace()` because related CRM tools share one high-level label and description.
* Mixing namespaced and top-level deferred tools in the same request is supported; tool search can load both namespace paths such as `crm` and top-level paths such as `get_shipping_eta`.
When you use tool search:
* Mark each deferred function tool with `deferLoading: true`.
* Use `toolNamespace({ name, description, tools })` when multiple related tools should share one domain description and be loaded as a group.
* Keep a tool top-level when it is a single independent capability and the tool name itself is a good search target.
* Add `toolSearchTool()` to the same `tools` array whenever any deferred function tool or hosted MCP tool uses `deferLoading: true`.
* Leave `modelSettings.toolChoice` on `'auto'`. The SDK rejects forcing the built-in `tool_search` tool or a deferred function tool by name.
* Hosted execution is the default. If you set `toolSearchTool({ execution: 'client', execute })`, the standard `run()` loop only supports the built-in `{ paths: string[] }` client query shape; custom client-side schemas require your own Responses loop.
* A namespace can mix immediate and deferred members. Immediate members stay callable without tool search, while deferred members in the same namespace are loaded on demand.
* Deferred function tools and `toolNamespace()` are Responses-only. Chat Completions rejects them, and the AI SDK adapter does not support deferred Responses tool-loading flows.
***
### 4. Agents as tools
[Section titled “4. Agents as tools”](#4-agents-as-tools)
Sometimes you want an Agent to *assist* another Agent without fully handing off the conversation. Use `agent.asTool()`:
If you are still choosing between `agent.asTool()` and `handoff()`, compare the patterns in the [Agents guide](/openai-agents-js/guides/agents#composition-patterns) and [Agent orchestration](/openai-agents-js/guides/multi-agent).
Agents as tools
```typescript
import { Agent } from '@openai/agents';
const summarizer = new Agent({
name: 'Summarizer',
instructions: 'Generate a concise summary of the supplied text.',
});
const summarizerTool = summarizer.asTool({
toolName: 'summarize_text',
toolDescription: 'Generate a concise summary of the supplied text.',
});
const mainAgent = new Agent({
name: 'Research assistant',
tools: [summarizerTool],
});
```
Under the hood the SDK:
* Creates a function tool with a single `input` parameter.
* Runs the sub‑agent with that input when the tool is called.
* Returns either the last message or the output extracted by `customOutputExtractor`.
When you run an agent as a tool, Agents SDK creates a runner with the default settings and run the agent with it within the function execution. If you want to provide any properties of `runConfig` or `runOptions`, you can pass them to the `asTool()` method to customize the runner’s behavior.
You can also set `needsApproval` and `isEnabled` on the agent tool via `asTool()` options to integrate with human‑in‑the‑loop flows and conditional tool availability.
Inside `customOutputExtractor`, use `result.agentToolInvocation` to inspect the current `Agent.asTool()` invocation. In that callback the result always comes from `Agent.asTool()`, so `agentToolInvocation` is always defined and exposes `toolName`, `toolCallId`, and `toolArguments`. Use `result.runContext` for the regular app context and `toolInput`. This metadata is scoped to the current nested invocation and is not serialized into `RunState`.
Read agent tool invocation metadata
```typescript
import { Agent } from '@openai/agents';
const billingAgent = new Agent({
name: 'Billing Agent',
instructions: 'Handle billing questions and subscription changes.',
});
const billingTool = billingAgent.asTool({
toolName: 'billing_agent',
toolDescription: 'Handles customer billing questions.',
customOutputExtractor(result) {
console.log('tool', result.agentToolInvocation.toolName);
// Direct invoke() calls may not have a model-generated tool call id.
console.log('call', result.agentToolInvocation.toolCallId);
console.log('args', result.agentToolInvocation.toolArguments);
return String(result.finalOutput ?? '');
},
});
const orchestrator = new Agent({
name: 'Support Orchestrator',
instructions: 'Delegate billing questions to the billing agent tool.',
tools: [billingTool],
});
```
Advanced structured-input options for `agent.asTool()`:
* `inputBuilder`: maps structured tool args to the nested agent input payload.
* `includeInputSchema`: includes the input JSON schema in the nested run for stronger schema-aware behavior.
* `resumeState`: controls context reconciliation strategy when resuming nested serialized `RunState`: `'merge'` (default) merges live approval/context state into the serialized state, `'replace'` uses the current run context instead, and `'preferSerialized'` resumes with the serialized context unchanged.
#### Streaming events from agent tools
[Section titled “Streaming events from agent tools”](#streaming-events-from-agent-tools)
Agent tools can stream all nested run events back to your app. Choose the hook style that fits how you construct the tool:
Streaming agent tools
```typescript
import { Agent } from '@openai/agents';
const billingAgent = new Agent({
name: 'Billing Agent',
instructions: 'Answer billing questions and compute simple charges.',
});
const billingTool = billingAgent.asTool({
toolName: 'billing_agent',
toolDescription: 'Handles customer billing questions.',
// onStream: simplest catch-all when you define the tool inline.
onStream: (event) => {
console.log(`[onStream] ${event.event.type}`, event);
},
});
// on(eventName) lets you subscribe selectively (or use '*' for all).
billingTool.on('run_item_stream_event', (event) => {
console.log('[on run_item_stream_event]', event);
});
billingTool.on('raw_model_stream_event', (event) => {
console.log('[on raw_model_stream_event]', event);
});
const orchestrator = new Agent({
name: 'Support Orchestrator',
instructions: 'Delegate billing questions to the billing agent tool.',
tools: [billingTool],
});
```
* Event types match `RunStreamEvent['type']`: `raw_model_stream_event`, `run_item_stream_event`, `agent_updated_stream_event`.
* `onStream` is the simplest “catch-all” and works well when you declare the tool inline (`tools: [agent.asTool({ onStream })]`). Use it if you do not need per-event routing.
* `on(eventName, handler)` lets you subscribe selectively (or with `'*'`) and is best when you need finer-grained handling or want to attach listeners after creation.
* If you provide either `onStream` or any `on(...)` handler, the agent-as-tool will run in streaming mode automatically; without them it stays on the non-streaming path.
* Handlers are invoked in parallel so a slow `onStream` callback will not block `on(...)` handlers (and vice versa).
* `toolCallId` is provided when the tool was invoked via a model tool call; direct `invoke()` calls or provider quirks may omit it.
***
### 5. MCP servers
[Section titled “5. MCP servers”](#5-mcp-servers)
You can expose tools via [Model Context Protocol (MCP)](https://modelcontextprotocol.io/) servers and attach them to an agent. For instance, you can use `MCPServerStdio` to spawn and connect to the stdio MCP server:
Local MCP server
```typescript
import { Agent, MCPServerStdio } from '@openai/agents';
const server = new MCPServerStdio({
fullCommand: 'pnpm exec mcp-server-filesystem ./sample_files',
});
await server.connect();
const agent = new Agent({
name: 'Assistant',
mcpServers: [server],
});
```
See [`filesystem-example.ts`](https://github.com/openai/openai-agents-js/tree/main/examples/mcp/filesystem-example.ts) for a complete example. Also, if you’re looking for a comprehensitve guide for MCP server tool integration, refer to [MCP guide](/openai-agents-js/guides/mcp) for details. When managing multiple servers (or partial failures), use `connectMcpServers` and the lifecycle guidance in the [MCP guide](/openai-agents-js/guides/mcp#managing-mcp-server-lifecycle).
***
### 6. Experimental: Codex tool
[Section titled “6. Experimental: Codex tool”](#6-experimental-codex-tool)
`@openai/agents-extensions/experimental/codex` provides `codexTool()`, a function tool that routes model tool calls to the Codex SDK so the agent can run workspace-scoped tasks (shell, file edits, MCP tools) autonomously. This surface is experimental and may change.
Install dependencies first:
```bash
npm install @openai/agents-extensions @openai/codex-sdk
```
Quick start:
Experimental Codex tool
```typescript
import { Agent } from '@openai/agents';
import { codexTool } from '@openai/agents-extensions/experimental/codex';
export const codexAgent = new Agent({
name: 'Codex Agent',
instructions:
'Use the codex tool to inspect the workspace and answer the question. When skill names, which usually start with `$`, are mentioned, you must rely on the codex tool to use the skill and answer the question.',
tools: [
codexTool({
sandboxMode: 'workspace-write',
workingDirectory: '/path/to/repo',
defaultThreadOptions: {
model: 'gpt-5.4',
networkAccessEnabled: true,
webSearchEnabled: false,
},
}),
],
});
```
What to know:
* Auth: supply `CODEX_API_KEY` (preferred) or `OPENAI_API_KEY`, or pass `codexOptions.apiKey`.
* Inputs: strict schema—`inputs` must contain at least one `{ type: 'text', text }` or `{ type: 'local_image', path }`.
* Safety: pair `sandboxMode` with `workingDirectory`; set `skipGitRepoCheck` if the directory is not a Git repo.
* Threading: `useRunContextThreadId: true` reads/stores the latest thread id in `runContext.context`, which is useful for cross-turn reuse in your app state.
* Thread ID precedence: tool call `threadId` (if your schema includes it) takes priority, then run-context thread id, then `codexTool({ threadId })`.
* Run context key: defaults to `codexThreadId` for `name: 'codex'`, or `codexThreadId_` for names like `name: 'engineer'` (`codex_engineer` after normalization).
* Mutable context requirement: when `useRunContextThreadId` is enabled, pass a mutable object or `Map` as `run(..., { context })`.
* Naming: tool names are normalized into the `codex` namespace (`engineer` becomes `codex_engineer`), and duplicate Codex tool names in an agent are rejected.
* Streaming: `onStream` mirrors Codex events (reasoning, command execution, MCP tool calls, file changes, web search) so you can log or trace progress.
* Outputs: tool result includes `response`, `usage`, and `threadId`, and Codex token usage is recorded in `RunContext`.
* Structure: `outputSchema` can be a descriptor, JSON schema object, or Zod object. For JSON object schemas, `additionalProperties` must be `false`.
Run-context thread reuse example:
Codex run-context thread reuse
```typescript
import { Agent, run } from '@openai/agents';
import { codexTool } from '@openai/agents-extensions/experimental/codex';
// Derived from codexTool({ name: 'engineer' }) when runContextThreadIdKey is omitted.
type ExampleContext = {
codexThreadId_engineer?: string;
};
const agent = new Agent({
name: 'Codex assistant',
instructions: 'Use the codex tool for workspace tasks.',
tools: [
codexTool({
// `name` is optional for a single Codex tool.
// We set it so the run-context key is tool-specific and to avoid collisions when adding more Codex tools.
name: 'engineer',
// Reuse the same Codex thread across runs that share this context object.
useRunContextThreadId: true,
sandboxMode: 'workspace-write',
workingDirectory: '/path/to/repo',
defaultThreadOptions: {
model: 'gpt-5.4',
approvalPolicy: 'never',
},
}),
],
});
// The default key for useRunContextThreadId with name=engineer is codexThreadId_engineer.
const context: ExampleContext = {};
// First turn creates (or resumes) a Codex thread and stores the thread ID in context.
await run(agent, 'Inspect src/tool.ts and summarize it.', { context });
// Second turn reuses the same thread because it shares the same context object.
await run(agent, 'Now list refactoring opportunities.', { context });
const threadId = context.codexThreadId_engineer;
```
***
## Tool strategy and best practices
[Section titled “Tool strategy and best practices”](#tool-strategy-and-best-practices)
### Tool use behavior
[Section titled “Tool use behavior”](#tool-use-behavior)
Refer to the [Agents guide](/openai-agents-js/guides/agents#forcing-tool-use) for controlling when and how a model must use tools (`modelSettings.toolChoice`, `toolUseBehavior`, etc.).
***
### Best practices
[Section titled “Best practices”](#best-practices)
* **Short, explicit descriptions** – describe *what* the tool does *and when to use it*.
* **Validate inputs** – use Zod schemas for strict JSON validation where possible.
* **Avoid side‑effects in error handlers** – `errorFunction` should return a helpful string, not throw.
* **One responsibility per tool** – small, composable tools lead to better model reasoning.
***
## Related guides
[Section titled “Related guides”](#related-guides)
* [Agents](/openai-agents-js/guides/agents) for defining tool-bearing agents and controlling `toolUseBehavior`.
* [Agent orchestration](/openai-agents-js/guides/multi-agent) for deciding when to use agents as tools versus handoffs.
* [Running agents](/openai-agents-js/guides/running-agents) for execution flow, streaming, and conversation state.
* [Models](/openai-agents-js/guides/models) for hosted OpenAI model configuration and Responses transport choices.
* [Guardrails](/openai-agents-js/guides/guardrails) to validate tool inputs or outputs.
* Dive into the TypeDoc reference for [`tool()`](/openai-agents-js/openai/agents/functions/tool) and the various hosted tool types.
# Tracing
> Learn how to trace your agent runs
The Agents SDK includes built-in tracing, collecting a comprehensive record of events during an agent run: LLM generations, tool calls, handoffs, guardrails, and even custom events that occur. Using the [Traces dashboard](https://platform.openai.com/traces), you can debug, visualize, and monitor your workflows during development and in production.
Note
Tracing is enabled by default in server runtimes (Node.js, Deno, Bun). It is disabled by default in browsers and when `NODE_ENV=test`.
There are two ways to disable tracing in server environments:
1. You can globally disable tracing by setting the env var `OPENAI_AGENTS_DISABLE_TRACING=1`
2. You can disable tracing on a runner by setting [`RunConfig.tracingDisabled`](/openai-agents-js/openai/agents-core/type-aliases/runconfig/#tracingdisabled) to `true` in `new Runner(...)`
***For organizations operating under a Zero Data Retention (ZDR) policy using OpenAI’s APIs, tracing is unavailable.***
## Export loop lifecycle
[Section titled “Export loop lifecycle”](#export-loop-lifecycle)
In supported server runtimes, traces are exported on a regular interval. In some runtimes, including Cloudflare Workers, the automatic export loop is unavailable even though tracing itself is still enabled. In those environments you should call `getGlobalTraceProvider().forceFlush()` as part of your request lifecycle to export queued traces before the runtime is torn down.
This guidance does not apply to browsers because tracing is disabled there by default.
For example, in a Cloudflare Worker, you should wrap your code into a `try/catch/finally` block and use `forceFlush()` with `waitUntil` to ensure that traces are exported before the worker exits.
```typescript
import { getGlobalTraceProvider } from '@openai/agents';
export default {
async fetch(request, env, ctx): Promise {
try {
// your agent code here
return new Response(`success`);
} catch (error) {
console.error(error);
return new Response(String(error), { status: 500 });
} finally {
// make sure to flush any remaining traces before exiting
ctx.waitUntil(getGlobalTraceProvider().forceFlush());
}
},
};
```
## Traces and spans
[Section titled “Traces and spans”](#traces-and-spans)
* **Traces** represent a single end-to-end operation of a “workflow”. They’re composed of Spans. Traces have the following properties:
* `workflow_name`: This is the logical workflow or app. For example “Code generation” or “Customer service”.
* `trace_id`: A unique ID for the trace. Automatically generated if you don’t pass one. Must have the format `trace_<32_alphanumeric>`.
* `group_id`: Optional group ID, to link multiple traces from the same conversation. For example, you might use a chat thread ID.
* `disabled`: If True, the trace will not be recorded.
* `metadata`: Optional metadata for the trace.
* **Spans** represent operations that have a start and end time. Spans have:
* `started_at` and `ended_at` timestamps.
* `trace_id`, to represent the trace they belong to
* `parent_id`, which points to the parent Span of this Span (if any)
* `span_data`, which is information about the Span. For example, `AgentSpanData` contains information about the Agent, `GenerationSpanData` contains information about the LLM generation, etc.
## Default tracing
[Section titled “Default tracing”](#default-tracing)
By default, the SDK traces the following:
* The entire `run()` or `Runner.run()` is wrapped in a `Trace`.
* Each time an agent runs, it is wrapped in `AgentSpan`
* LLM generations are wrapped in `GenerationSpan`
* Function tool calls are each wrapped in `FunctionSpan`
* Guardrails are wrapped in `GuardrailSpan`
* Handoffs are wrapped in `HandoffSpan`
By default, the trace is named “Agent workflow”. You can set this name if you use `withTrace`, or you can can configure the name and other properties with the [`RunConfig.workflowName`](/openai-agents-js/openai/agents-core/type-aliases/runconfig/#workflowname).
In addition, you can set up [custom trace processors](#custom-tracing-processors) to push traces to other destinations (as a replacement, or secondary destination).
### Voice agent tracing
[Section titled “Voice agent tracing”](#voice-agent-tracing)
If you are using `RealtimeAgent` and `RealtimeSession` with the default OpenAI Realtime API, tracing will automatically happen on the Realtime API side unless you disable it on the `RealtimeSession` using `tracingDisabled: true` or using the `OPENAI_AGENTS_DISABLE_TRACING` environment variable.
Check out the [Voice agents guide](/openai-agents-js/guides/voice-agents) for more details.
## Higher level traces
[Section titled “Higher level traces”](#higher-level-traces)
Sometimes, you might want multiple calls to `run()` to be part of a single trace. You can do this by wrapping the entire code in a `withTrace()`.
```typescript
import { Agent, run, withTrace } from '@openai/agents';
const agent = new Agent({
name: 'Joke generator',
instructions: 'Tell funny jokes.',
});
await withTrace('Joke workflow', async () => {
const result = await run(agent, 'Tell me a joke');
const secondResult = await run(
agent,
`Rate this joke: ${result.finalOutput}`,
);
console.log(`Joke: ${result.finalOutput}`);
console.log(`Rating: ${secondResult.finalOutput}`);
});
```
1. Because the two calls to `run` are wrapped in a `withTrace()`, the individual runs will be part of the overall trace rather than creating two traces.
## Creating traces
[Section titled “Creating traces”](#creating-traces)
You can use the [`withTrace()`](/openai-agents-js/openai/agents-core/functions/withtrace/) function to create a trace. Alternatively, you can use `getGlobalTraceProvider().createTrace()` to create a new trace manually and pass it into `withTrace()`.
The current trace is tracked via a [Node.js `AsyncLocalStorage`](https://nodejs.org/api/async_context.html#class-asynclocalstorage) or the respective environment polyfills. This means that it works with concurrency automatically.
## Creating spans
[Section titled “Creating spans”](#creating-spans)
You can use the various `create*Span()` (e.g. `createGenerationSpan()`, `createFunctionSpan()`, etc.) methods to create a span. In general, you don’t need to manually create spans. A [`createCustomSpan()`](/openai-agents-js/openai/agents-core/functions/createcustomspan/) function is available for tracking custom span information.
Spans are automatically part of the current trace, and are nested under the nearest current span, which is tracked via a [Node.js `AsyncLocalStorage`](https://nodejs.org/api/async_context.html#class-asynclocalstorage) or the respective environment polyfills.
## Sensitive data
[Section titled “Sensitive data”](#sensitive-data)
Certain spans may capture potentially sensitive data.
The `createGenerationSpan()` stores the inputs/outputs of the LLM generation, and `createFunctionSpan()` stores the inputs/outputs of function calls. These may contain sensitive data, so you can disable capturing that data via [`RunConfig.traceIncludeSensitiveData`](/openai-agents-js/openai/agents-core/type-aliases/runconfig/#traceincludesensitivedata).
## OpenAI tracing exporter
[Section titled “OpenAI tracing exporter”](#openai-tracing-exporter)
In supported server runtimes, the default tracing setup already exports to OpenAI. Use `setTracingExportApiKey()` when trace export should use a different credential than `OPENAI_API_KEY`.
If you need custom ingest behavior, instantiate [`OpenAITracingExporter`](/openai-agents-js/openai/agents-openai/classes/openaitracingexporter) yourself and install it with `setTraceProcessors(...)` or `addTraceProcessor(...)`. The exporter supports `apiKey`, `endpoint`, `organization`, `project`, `maxRetries`, `baseDelay`, and `maxDelay`.
If you replace the default processors and later want to restore the default OpenAI exporter with a batch processor, call [`setDefaultOpenAITracingExporter()`](/openai-agents-js/openai/agents-openai/functions/setdefaultopenaitracingexporter/).
## Custom tracing processors
[Section titled “Custom tracing processors”](#custom-tracing-processors)
The high level architecture for tracing is:
* At initialization, we create a global [`TraceProvider`](/openai-agents-js/openai/agents-core/classes/traceprovider), which is responsible for creating traces and can be accessed through [`getGlobalTraceProvider()`](/openai-agents-js/openai/agents-core/functions/getglobaltraceprovider/).
* We configure the `TraceProvider` with a [`BatchTraceProcessor`](/openai-agents-js/openai/agents-core/classes/batchtraceprocessor/) that sends traces/spans in batches to a [`OpenAITracingExporter`](/openai-agents-js/openai/agents-openai/classes/openaitracingexporter/), which exports the spans and traces to the OpenAI backend in batches.
To customize this default setup, to send traces to alternative or additional backends or modifying exporter behavior, you have two options:
1. [`addTraceProcessor()`](/openai-agents-js/openai/agents-core/functions/addtraceprocessor) lets you add an **additional** trace processor that will receive traces and spans as they are ready. This lets you do your own processing in addition to sending traces to OpenAI’s backend.
2. [`setTraceProcessors()`](/openai-agents-js/openai/agents-core/functions/settraceprocessors) lets you **replace** the default processors with your own trace processors. This means traces will not be sent to the OpenAI backend unless you include a `TracingProcessor` that does so.
## External tracing processors list
[Section titled “External tracing processors list”](#external-tracing-processors-list)
* [AgentOps](https://docs.agentops.ai/v2/usage/typescript-sdk#openai-agents-integration)
* [Respan](https://www.respan.ai/docs/integrations/openai-agents-sdk)
* [PromptLayer](https://docs.promptlayer.com/languages/integrations#openai-agents-sdk)
# Troubleshooting
> Learn how to troubleshoot issues with the OpenAI Agents SDK.
## Supported environments
[Section titled “Supported environments”](#supported-environments)
The OpenAI Agents SDK is supported on the following server environments:
* Node.js 22+
* Deno 2.35+
* Bun 1.2.5+
### Limited support
[Section titled “Limited support”](#limited-support)
* **Cloudflare Workers**: The Agents SDK can be used in Cloudflare Workers, but currently comes with some limitations:
* The SDK current requires `nodejs_compat` to be enabled
* Traces need to be manually flushed at the end of the request. [See the tracing guide](/openai-agents-js/guides/tracing#export-loop-lifecycle) for more details.
* Due to Cloudflare Workers’ limited support for `AsyncLocalStorage` some traces might not be accurate
* Outbound WebSocket connections must use a fetch-based upgrade (not the global `WebSocket` constructor). For Realtime, use the Cloudflare transport in `@openai/agents-extensions` (`CloudflareRealtimeTransportLayer`).
* **Responses API WebSocket transport**:
* Requires a global `WebSocket` implementation.
* The `WebSocket` implementation must support custom headers for the handshake.
* Many browser-style WebSocket APIs (and some edge runtimes) do not support custom outbound headers. In those environments, use the default HTTP Responses transport instead.
* If you see errors mentioning a missing global `WebSocket` implementation or lack of custom-header support, the runtime websocket implementation is not compatible with the Responses WebSocket transport.
* **Browsers**:
* The core SDK can be bundled for browser use, but tracing is disabled by default there.
* **v8 isolates**:
* While you should be able to bundle the SDK for v8 isolates if you use a bundler with the right browser polyfills, tracing will not work
* v8 isolates have not been extensively tested
## Debug logging
[Section titled “Debug logging”](#debug-logging)
If you are running into problems with the SDK, you can enable debug logging to get more information about what is happening.
Enable debug logging by setting the `DEBUG` environment variable to `openai-agents:*`.
```bash
DEBUG=openai-agents:*
```
Alternatively, you can scope the debugging to specific parts of the SDK:
* `openai-agents:core` — for the main execution logic of the SDK
* `openai-agents:openai` — for the OpenAI API calls
* `openai-agents:realtime` — for the Realtime Agents components
# Voice Agents
> Build realtime voice assistants using RealtimeAgent and RealtimeSession
## Overview
[Section titled “Overview”](#overview)

Voice Agents let you build low-latency spoken interfaces on top of OpenAI speech-to-speech models. The SDK keeps the Realtime API mental model intact, but wraps the raw event flow in `RealtimeAgent`, `RealtimeSession`, and transport helpers that make tools, guardrails, handoffs, and session history easier to work with.
Under the hood, the same Realtime concepts from the official [Realtime API with WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc/), [Realtime conversations](https://developers.openai.com/api/docs/guides/realtime-conversations/), and [voice activity detection](https://developers.openai.com/api/docs/guides/realtime-vad/) guides still apply. The Voice Agents SDK adds a TypeScript-first layer on top of that API so you can stay focused on product logic instead of rebuilding transport and event handling from scratch.
Note
Start with the Quickstart if you are connecting a browser client with WebRTC. Jump to the transport guide first if you are deciding between WebRTC, WebSocket, SIP, Twilio, or Cloudflare Workers.
## Start here
[Section titled “Start here”](#start-here)
[Voice Agents Quickstart ](/openai-agents-js/guides/voice-agents/quickstart)Build your first realtime voice assistant using the OpenAI Agents SDK in minutes.
[Building Voice Agents ](/openai-agents-js/guides/voice-agents/build)Learn how session lifecycle, VAD, interruptions, multimodal input, tools, and history work in the SDK.
[Realtime Transport Layer ](/openai-agents-js/guides/voice-agents/transport)Choose between WebRTC, WebSocket, SIP, or a custom transport, and know when to drop down to raw events.
## What the SDK adds
[Section titled “What the SDK adds”](#what-the-sdk-adds)
* Browser-first WebRTC setup with ephemeral client tokens.
* Server-side WebSocket and SIP transport options.
* Automatic interruption handling and local conversation history updates.
* Multi-agent orchestration through realtime handoffs.
* Function tools, hosted MCP tools, approvals, and delegation patterns.
* Output guardrails and tracing support for live spoken interactions.
## Pick the next page
[Section titled “Pick the next page”](#pick-the-next-page)
| If you need to… | Go here |
| --------------------------------------------------------------------------------- | --------------------------------------------------------------------------- |
| Connect a browser client safely with WebRTC and ephemeral tokens | [Voice Agents Quickstart](/openai-agents-js/guides/voice-agents/quickstart) |
| Understand session lifecycle, VAD, interruptions, image input, tools, and history | [Building Voice Agents](/openai-agents-js/guides/voice-agents/build) |
| Decide between WebRTC, WebSocket, SIP, and custom transports | [Realtime Transport Layer](/openai-agents-js/guides/voice-agents/transport) |
| Run a phone or telephony experience on Twilio | [Realtime Agents on Twilio](/openai-agents-js/extensions/twilio) |
| Connect from Cloudflare Workers or other workerd runtimes | [Realtime Agents on Cloudflare](/openai-agents-js/extensions/cloudflare) |
## Why speech-to-speech
[Section titled “Why speech-to-speech”](#why-speech-to-speech)
Speech-to-speech models process user audio directly, so you do not have to build a separate speech-to-text, text reasoning, and text-to-speech chain for every turn. That keeps latency down and makes interruptions, mixed text and voice input, and tool calls feel much more natural in realtime applications.
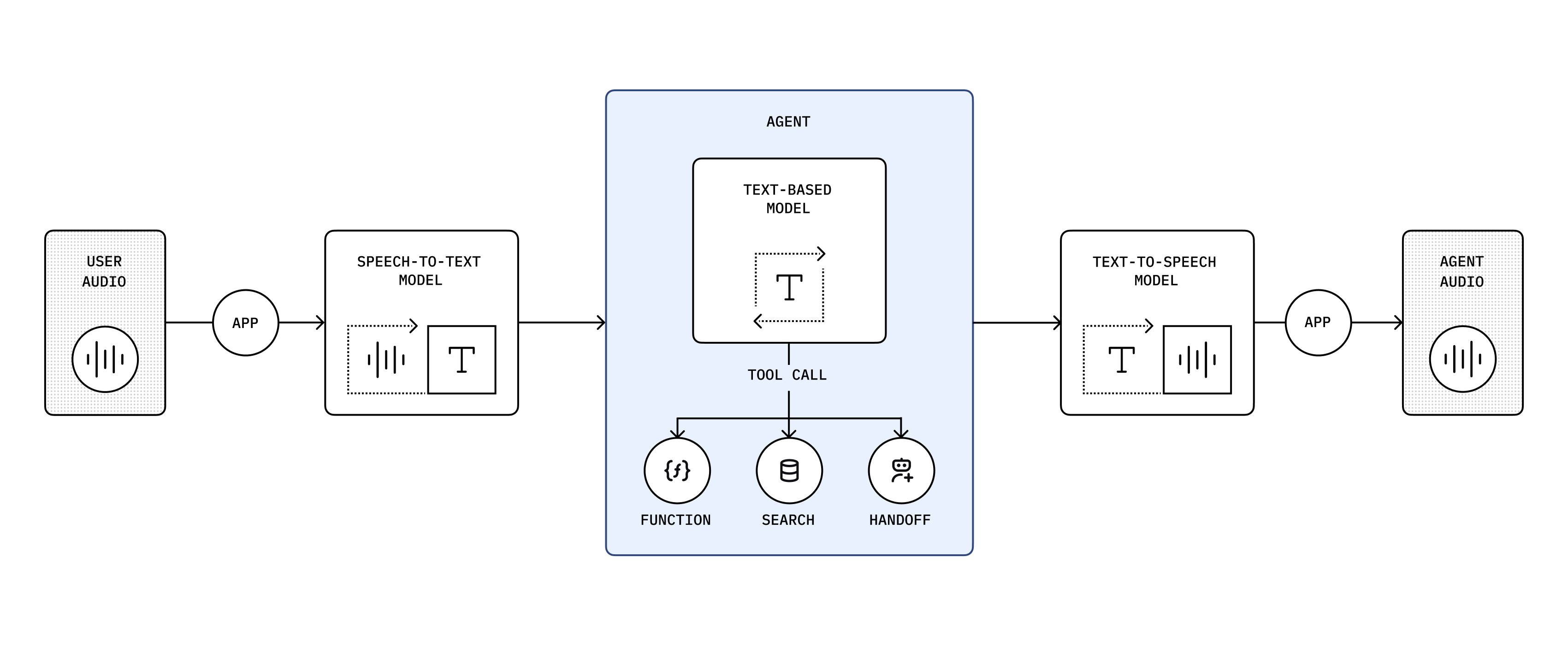
# Building Voice Agents
> Learn how to build voice agents using the OpenAI Agents SDK, how session behavior works, and which realtime features are available.
Caution
Choose your architecture early:
* `OpenAIRealtimeWebRTC` is the simplest browser path and handles audio input/output for you.
* `OpenAIRealtimeWebSocket` gives you more control, but you must manage audio capture and playback yourself.
* Function tools run wherever the `RealtimeSession` runs. If the session runs in the browser, the tool runs in the browser too.
* Realtime handoffs keep the same live session model. Voice changes only work before the session has produced audio output. If you need a different backend model, delegate through a tool instead of a handoff.
## Session setup
[Section titled “Session setup”](#session-setup)
### Audio handling
[Section titled “Audio handling”](#audio-handling)
Some transport layers like the default `OpenAIRealtimeWebRTC` handle audio input and output automatically for you. For other transport mechanisms like `OpenAIRealtimeWebSocket` you have to handle session audio yourself:
```typescript
import {
RealtimeAgent,
RealtimeSession,
TransportLayerAudio,
} from '@openai/agents/realtime';
const agent = new RealtimeAgent({ name: 'My agent' });
const session = new RealtimeSession(agent);
const newlyRecordedAudio = new ArrayBuffer(0);
session.on('audio', (event: TransportLayerAudio) => {
// play your audio
});
// send new audio to the agent
session.sendAudio(newlyRecordedAudio);
```
When the underlying transport supports it, `session.muted` reports the current mute state and `session.mute(true | false)` toggles microphone capture. `OpenAIRealtimeWebSocket` does not implement muting: `session.muted` returns `null` and `session.mute()` throws, so for websocket setups you should pause capture on your side and stop calling `sendAudio()` until the microphone should be live again.
### Session configuration
[Section titled “Session configuration”](#session-configuration)
Configure the session itself when you create [`RealtimeSession`](/openai-agents-js/openai/agents-realtime/classes/realtimesession/), usually through the `model` option and the `config` object. `connect(...)` is for connection-time concerns such as credentials, endpoint URL, and SIP call attachment rather than arbitrary session fields.
```typescript
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Greeter',
instructions: 'Greet the user with cheer and answer questions.',
});
const session = new RealtimeSession(agent, {
model: 'gpt-realtime-2',
config: {
outputModalities: ['audio'],
reasoning: {
effort: 'low',
},
parallelToolCalls: true,
audio: {
input: {
format: 'pcm16',
transcription: {
model: 'gpt-4o-mini-transcribe',
},
},
output: {
format: 'pcm16',
},
},
},
});
```
Under the hood, the SDK normalizes this configuration into the Realtime [`session.update`](https://developers.openai.com/api/reference/resources/realtime/client-events/#session.update) shape. If you need a raw session field that does not have a matching property in [RealtimeSessionConfig](/openai-agents-js/openai/agents-realtime/type-aliases/realtimesessionconfig/), use `providerData` or send a raw `session.update` through `session.transport.sendEvent(...)`.
Prefer the newer SDK config shape with `outputModalities`, `audio.input`, and `audio.output`. Older SDK aliases such as `modalities`, `inputAudioFormat`, `outputAudioFormat`, `inputAudioTranscription`, and `turnDetection` are still normalized for backwards compatibility, but new code should use the nested `audio` structure shown here.
For reasoning-capable Realtime models such as `gpt-realtime-2`, set `reasoning.effort` on the session config. Higher reasoning effort can increase latency and token usage. You can also set `parallelToolCalls` when you want to control whether the model may call multiple tools in parallel.
For speech-to-speech sessions, the usual choice is `outputModalities: ['audio']`, which gives you audio output plus transcripts. Switch to `['text']` only when you want text-only responses.
For parameters that are new and do not have a matching parameter in [RealtimeSessionConfig](/openai-agents-js/openai/agents-realtime/type-aliases/realtimesessionconfig/), you can use `providerData`. Anything passed in `providerData` is forwarded as part of the raw `session` object.
Additional `RealtimeSession` options you can set at construction time:
| Option | Type | Purpose |
| --------------------------------------------- | --------------------------------- | --------------------------------------------------------------------------------------- |
| `context` | `TContext` | Extra local context merged into the session context. |
| `historyStoreAudio` | `boolean` | Store audio data in the local history snapshot (disabled by default). |
| `outputGuardrails` | `RealtimeOutputGuardrail[]` | Output guardrails for the session (see [Guardrails](#guardrails)). |
| `outputGuardrailSettings` | `{ debounceTextLength?: number }` | Guardrail cadence. Defaults to `100`; use `-1` to only run once full text is available. |
| `tracingDisabled` | `boolean` | Disable tracing for the session. |
| `groupId` | `string` | Group traces across sessions or backend runs. Requires `workflowName`. |
| `traceMetadata` | `Record` | Custom metadata to attach to session traces. Requires `workflowName`. |
| `workflowName` | `string` | Friendly name for the trace workflow. |
| `automaticallyTriggerResponseForMcpToolCalls` | `boolean` | Auto-trigger a model response when an MCP tool call completes (default: `true`). |
| `toolErrorFormatter` | `ToolErrorFormatter` | Customize tool approval rejection messages returned to the model. |
`connect(...)` options:
| Option | Type | Purpose |
| -------- | --------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `apiKey` | `string \| (() => string \| Promise)` | API key (or lazy loader) used for this connection. |
| `model` | `OpenAIRealtimeModels \| string` | Present in the transport-level options type. For `RealtimeSession`, set the model in the constructor; raw transports can also use a model at connect time. |
| `url` | `string` | Optional custom Realtime endpoint URL. |
| `callId` | `string` | Attach to an existing SIP-initiated call/session. |
### Conversation lifecycle
[Section titled “Conversation lifecycle”](#conversation-lifecycle)
`RealtimeSession` sits on top of a long-lived Realtime connection. It keeps a local copy of conversation history, listens for transport events, runs tools and output guardrails, and keeps the active agent configuration synchronized with the transport.
The underlying API behavior still matters:
* A successful connection starts with a `session.created` event, and later config changes produce `session.updated`.
* Most session properties can be changed over time, but `model` cannot change mid-conversation, `voice` can only change before the session has produced audio output, and tracing should be decided up front because the Realtime API does not let you modify tracing after it is enabled.
* The Realtime API currently limits a single session to 60 minutes.
* Input audio transcription is asynchronous, so the transcript for the latest utterance can arrive after response generation has already started.
At the SDK layer, `await session.connect()` means “the transport is ready enough to start the conversation”, but the exact point differs by transport:
* In the default browser WebRTC transport, the SDK sends the initial `session.update` as soon as the data channel opens and tries to wait for the corresponding `session.updated` event before resolving `connect()`. This is there to avoid audio reaching the server before your instructions, tools, and modalities are applied. If that acknowledgement never arrives, `connect()` falls back to resolving after a short timeout.
* In the default server-side WebSocket transport, `connect()` resolves once the socket is open and the initial config has been sent. The matching `session.updated` event can therefore arrive after `connect()` has already resolved.
If you need the raw event model, read the official [Realtime conversations guide](https://developers.openai.com/api/docs/guides/realtime-conversations/) alongside this page.
## Interaction flow
[Section titled “Interaction flow”](#interaction-flow)
### Turn detection and voice activity detection
[Section titled “Turn detection and voice activity detection”](#turn-detection-and-voice-activity-detection)
By default, Realtime sessions use built-in voice activity detection (VAD) so the API can decide when the user has started or stopped speaking and when to create a response. The SDK exposes this through `audio.input.turnDetection`.
```typescript
import { RealtimeSession } from '@openai/agents/realtime';
import { agent } from './agent';
const session = new RealtimeSession(agent, {
model: 'gpt-realtime-2',
config: {
audio: {
input: {
turnDetection: {
type: 'semantic_vad',
eagerness: 'medium',
createResponse: true,
interruptResponse: true,
},
},
},
},
});
```
Two common modes are:
* `semantic_vad`, which aims for more natural turn boundaries and can wait a little longer when the user sounds like they are not finished yet.
* `server_vad`, which is more threshold-driven and exposes settings such as `threshold`, `prefixPaddingMs`, `silenceDurationMs`, and `idleTimeoutMs`.
Set `audio.input.turnDetection` to `null` if you want to manage turn boundaries yourself. The official [voice activity detection guide](https://developers.openai.com/api/docs/guides/realtime-vad/) and [Realtime conversations guide](https://developers.openai.com/api/docs/guides/realtime-conversations/#voice-activity-detection) describe the underlying behavior in more detail.
### Interruptions
[Section titled “Interruptions”](#interruptions)
When VAD is enabled, speaking over the agent can interrupt the current response. On the WebSocket transport, the SDK listens for `input_audio_buffer.speech_started`, truncates the assistant audio to what the user actually heard, and emits an `audio_interrupted` event. That event is especially useful when you manage playback yourself in WebSocket setups.
```typescript
import { session } from './agent';
session.on('audio_interrupted', () => {
// handle local playback interruption
});
```
If you want to expose a manual stop button, call `interrupt()` yourself:
```typescript
import { session } from './agent';
session.interrupt();
// this will still trigger the `audio_interrupted` event for you
// to cut off the audio playback when using WebSockets
```
WebRTC and WebSocket both stop the in-progress response, but the low-level mechanics differ by transport. WebRTC clears buffered output audio for you. In WebSocket setups you still need to stop local playback yourself, and the local history updates when the corresponding truncation and conversation events come back from the transport.
### Text input
[Section titled “Text input”](#text-input)
Use `sendMessage()` when you want to send typed input or additional structured user content into the live conversation.
```typescript
import { RealtimeSession, RealtimeAgent } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Assistant',
});
const session = new RealtimeSession(agent, {
model: 'gpt-realtime-2',
});
session.sendMessage('Hello, how are you?');
```
This is useful for mixed text and voice UIs, out-of-band context injection, or pairing spoken input with explicit typed clarifications.
### Image input
[Section titled “Image input”](#image-input)
Realtime speech-to-speech sessions can also include images. In the SDK, use `addImage()` to attach an image to the current conversation.
```typescript
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Assistant',
});
const session = new RealtimeSession(agent, {
model: 'gpt-realtime-2',
});
const imageDataUrl = 'data:image/png;base64,...';
session.addImage(imageDataUrl, { triggerResponse: false });
session.sendMessage('Describe what is in this image.');
```
Passing `triggerResponse: false` lets you batch the image with a later text or audio turn before asking the model to respond. This lines up with the official [Realtime conversations image input guidance](https://developers.openai.com/api/docs/guides/realtime-conversations/#image-inputs).
### Manual response control
[Section titled “Manual response control”](#manual-response-control)
At the higher SDK layer, `sendMessage()` and `addImage()` trigger a response for you by default. Manual response control matters when you are working with raw transport events, push-to-talk flows, or custom moderation / validation steps.
```typescript
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Greeter',
instructions: 'Greet the user with cheer and answer questions.',
});
const session = new RealtimeSession(agent, {
model: 'gpt-realtime-2',
});
session.transport.on('*', (event) => {
// JSON parsed version of the event received on the connection
});
// Send any valid event as JSON. For example triggering a new response
session.transport.sendEvent({
type: 'response.create',
// ...
});
```
There are two common cases:
1. If you disable VAD entirely with `audio.input.turnDetection = null`, you are responsible for committing audio turns and then sending `response.create`.
2. If you keep VAD enabled but set `turnDetection.interruptResponse = false` and `turnDetection.createResponse = false`, the API still detects turns but leaves response creation up to you.
That second pattern is useful when you want to inspect or moderate user input before the model responds. It matches the official [Realtime conversations guidance on disabling automatic responses](https://developers.openai.com/api/docs/guides/realtime-conversations/#keep-vad-but-disable-automatic-responses).
## Agent capabilities
[Section titled “Agent capabilities”](#agent-capabilities)
### Handoffs
[Section titled “Handoffs”](#handoffs)
Similarly to regular agents, you can use handoffs to break your agent into multiple agents and orchestrate between them to improve performance and better scope the problem.
```typescript
import { RealtimeAgent } from '@openai/agents/realtime';
const mathTutorAgent = new RealtimeAgent({
name: 'Math Tutor',
handoffDescription: 'Specialist agent for math questions',
instructions:
'You provide help with math problems. Explain your reasoning at each step and include examples',
});
const agent = new RealtimeAgent({
name: 'Greeter',
instructions: 'Greet the user with cheer and answer questions.',
handoffs: [mathTutorAgent],
});
```
Unlike regular agents, handoffs behave slightly differently for Realtime Agents. When a handoff is performed, the ongoing session is updated with the new agent configuration in place. Because of this, the new agent automatically has access to the ongoing conversation history and input filters are currently not applied.
Because the session stays live, the model for that session does not change during a handoff. Voice changes follow the underlying Realtime API rule: they only work before the session has produced audio output. Realtime handoffs are primarily for swapping between `RealtimeAgent` configurations on the same session; if you need to use a different model, for example a reasoning model like `gpt-5.4`, or delegate to a non-realtime backend agent, use [delegation through tools](#delegation-through-tools).
### Tools
[Section titled “Tools”](#tools)
Just like regular agents, Realtime Agents can call tools to perform actions. Realtime supports **function tools** (executed locally) and **hosted MCP tools** (executed remotely by the Realtime API). You can define a function tool using the same `tool()` helper you would use for a regular agent.
```typescript
import { tool, RealtimeAgent } from '@openai/agents/realtime';
import { z } from 'zod';
const getWeather = tool({
name: 'get_weather',
description: 'Return the weather for a city.',
parameters: z.object({ city: z.string() }),
async execute({ city }) {
return `The weather in ${city} is sunny.`;
},
});
const weatherAgent = new RealtimeAgent({
name: 'Weather assistant',
instructions: 'Answer weather questions.',
tools: [getWeather],
});
```
#### Function tools
[Section titled “Function tools”](#function-tools)
Function tools run in the same environment as your `RealtimeSession`. This means if you are running your session in the browser, the tool executes in the browser. If you need to perform sensitive actions, call your backend from inside the tool and let the server do the privileged work.
This lets a browser-side tool act as a thin backchannel to server-side logic. For example, [`examples/realtime-next`](https://github.com/openai/openai-agents-js/tree/main/examples/realtime-next) defines a `refundBackchannel` tool in the browser that forwards the request and current conversation history to `handleRefundRequest(...)` on the server, where a separate `Runner` can use a different agent or model to evaluate the refund before returning the result to the voice session.
#### Hosted MCP tools
[Section titled “Hosted MCP tools”](#hosted-mcp-tools)
Hosted MCP tools can be configured with `hostedMcpTool` and are executed remotely. When MCP tool availability changes the session emits `mcp_tools_changed`. To prevent the session from auto-triggering a model response after MCP tool calls complete, set `automaticallyTriggerResponseForMcpToolCalls: false`.
The current filtered MCP tool list is also available as `session.availableMcpTools`. Both that property and the `mcp_tools_changed` event reflect only the hosted MCP servers enabled on the active agent, after applying any `allowed_tools` filters from the agent configuration.
Hosted MCP setup is easiest to reason about if you treat secure server selection, headers, and approvals as pre-connect configuration. Before `RealtimeSession.connect()` opens the transport, the SDK resolves the active agent’s hosted MCP tool definitions and includes the supported MCP fields in the initial session config it sends to the Realtime API.
That timing matters most in browser WebRTC apps. The ephemeral client secret is always minted on your server, so any hosted MCP credentials or custom `headers` that must stay secret should be attached in that server-side `POST /v1/realtime/client_secrets` request as part of the initial `session` payload. Do not put long-lived credentials in browser code and plan to add them later after `connect()` starts.
At the Realtime API level, later `session.update` calls can still change tools and other mutable session fields, and the SDK itself sends `session.update` when the active agent changes. In browser apps, though, you should treat secure Hosted MCP initialization as a server-side, pre-connect concern and keep the browser-side `RealtimeSession` config aligned with what your server minted.
#### Background results
[Section titled “Background results”](#background-results)
While the tool is executing the agent will not be able to process new requests from the user. One way to improve the experience is by telling your agent to announce when it is about to execute a tool or say specific phrases to buy the agent some time to execute the tool.
If a function tool should finish without immediately triggering another model response, return `backgroundResult(output)` from `@openai/agents/realtime`. This sends the tool output back to the session while leaving response triggering under your control.
#### Timeouts
[Section titled “Timeouts”](#timeouts)
Function tool timeout options (`timeoutMs`, `timeoutBehavior`, `timeoutErrorFunction`) work the same way in Realtime sessions. With the default `error_as_result`, the timeout message is sent as tool output. With `raise_exception`, the session emits an `error` event with [`ToolTimeoutError`](/openai-agents-js/openai/agents-core/classes/tooltimeouterror) and does not send tool output for that call.
#### Accessing the conversation history
[Section titled “Accessing the conversation history”](#accessing-the-conversation-history)
In addition to the arguments that the agent called a particular tool with, you can also access a snapshot of the current conversation history tracked by the Realtime Session. This can be useful if you need to perform a more complex action based on the current state of the conversation or are planning to use [tools for delegation](#delegation-through-tools).
```typescript
import {
tool,
RealtimeContextData,
RealtimeItem,
} from '@openai/agents/realtime';
import { z } from 'zod';
const parameters = z.object({
request: z.string(),
});
const refundTool = tool({
name: 'Refund Expert',
description: 'Evaluate a refund',
parameters,
execute: async ({ request }, details) => {
// The history might not be available
const history: RealtimeItem[] = details?.context?.history ?? [];
// making your call to process the refund request
},
});
```
Note
The history passed in is a snapshot of the history at the time of the tool call. The transcription of the last thing the user said might not be available yet.
#### Approval before tool execution
[Section titled “Approval before tool execution”](#approval-before-tool-execution)
If you define your tool with `needsApproval: true` the agent emits a `tool_approval_requested` event before executing the tool.
By listening to this event you can show a UI to the user to approve or reject the tool call.
Resolve the request with `await session.approve(request.approvalItem)` or `await session.reject(request.approvalItem)`. For function tools you can pass `{ alwaysApprove: true }` or `{ alwaysReject: true }` to reuse the same decision for repeated calls during the rest of the session, and `session.reject(request.approvalItem, { message: '...' })` to send a custom rejection message back to the model for that specific call. Hosted MCP approvals do not support sticky approve/reject; restrict those tools with the hosted MCP `allowedTools` configuration instead.
If you do not pass a per-call rejection `message`, the session falls back to `toolErrorFormatter` (if configured) and then to the SDK default rejection text.
```typescript
import { session } from './agent';
session.on('tool_approval_requested', (_context, _agent, request) => {
// show a UI to the user to approve or reject the tool call
// you can use the `session.approve(...)` or `session.reject(...)` methods to approve or reject the tool call
session.approve(request.approvalItem); // or session.reject(request.approvalItem);
});
```
Note
While the voice agent is waiting for approval for the tool call, the agent will not be able to process new requests from the user.
### Guardrails
[Section titled “Guardrails”](#guardrails)
Guardrails offer a way to monitor whether what the agent has said violated a set of rules and immediately cut off the response. These checks run against the transcript stream of the agent’s response. In audio sessions, the SDK uses output audio transcripts and transcript deltas, so the important prerequisite is transcript availability rather than a separate text output modality.
The guardrails you provide run asynchronously as a model response is returned, allowing you to cut off the response based on a predefined classification trigger, for example “mentions a specific banned word”.
When a guardrail trips the session emits a `guardrail_tripped` event. The event also provides a `details` object containing the `itemId` that triggered the guardrail.
```typescript
import {
RealtimeOutputGuardrail,
RealtimeAgent,
RealtimeSession,
} from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Greeter',
instructions: 'Greet the user with cheer and answer questions.',
});
const guardrails: RealtimeOutputGuardrail[] = [
{
name: 'No mention of Dom',
async execute({ agentOutput }) {
const domInOutput = agentOutput.includes('Dom');
return {
tripwireTriggered: domInOutput,
outputInfo: { domInOutput },
};
},
},
];
const guardedSession = new RealtimeSession(agent, {
outputGuardrails: guardrails,
});
```
By default guardrails run every 100 characters and again when the final transcript is available. Because speaking the text usually takes longer than generating the transcript, this often lets the guardrail cut off unsafe output before the user hears it.
If you want to modify this behavior you can pass an `outputGuardrailSettings` object to the session.
Set `debounceTextLength: -1` when you only want to evaluate the fully generated transcript once, at the end of the response.
```typescript
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Greeter',
instructions: 'Greet the user with cheer and answer questions.',
});
const guardedSession = new RealtimeSession(agent, {
outputGuardrails: [
/*...*/
],
outputGuardrailSettings: {
debounceTextLength: 500, // run guardrail every 500 characters or set it to -1 to run it only at the end
},
});
```
## Conversation state and delegation
[Section titled “Conversation state and delegation”](#conversation-state-and-delegation)
### Conversation history management
[Section titled “Conversation history management”](#conversation-history-management)
`RealtimeSession` automatically maintains a local `history` snapshot that tracks user messages, assistant output, tool calls, and truncation state. You can render it in the UI, inspect it inside tools, or update it when you need to correct or remove items.
As the conversation changes the session emits `history_updated`. If you need to request history changes, use `updateHistory()`. It asks the transport to diff the current history and send the necessary delete/create events; the local `session.history` view updates as the corresponding conversation events come back.
```typescript
import { RealtimeSession, RealtimeAgent } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Assistant',
});
const session = new RealtimeSession(agent, {
model: 'gpt-realtime-2',
});
await session.connect({ apiKey: '' });
// listening to the history_updated event
session.on('history_updated', (history) => {
// returns the full history of the session
console.log(history);
});
// Option 1: explicit setting
session.updateHistory([
/* specific history */
]);
// Option 2: override based on current state like removing all agent messages
session.updateHistory((currentHistory) => {
return currentHistory.filter(
(item) => !(item.type === 'message' && item.role === 'assistant'),
);
});
```
#### Limitations
[Section titled “Limitations”](#limitations)
1. You cannot currently edit function tool calls after the fact.
2. Assistant text in history depends on available transcripts, including `output_audio.transcript`.
3. Responses truncated by interruption do not retain a final transcript.
4. Input audio transcription is best treated as a rough guide to what the user said, not an exact copy of how the model interpreted the audio.
### Delegation through tools
[Section titled “Delegation through tools”](#delegation-through-tools)
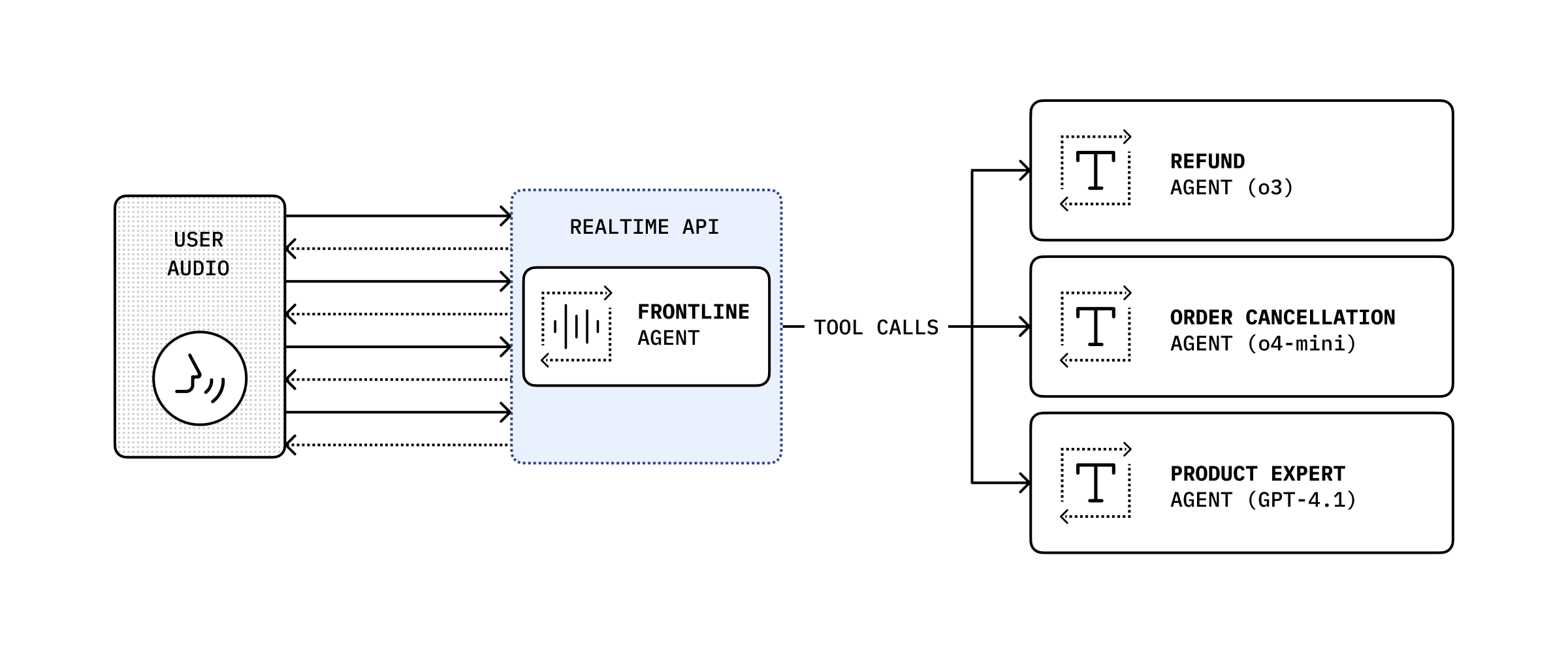
By combining the conversation history with a tool call, you can delegate the conversation to another backend agent to perform a more complex action and then pass it back as the result to the user.
```typescript
import {
RealtimeAgent,
RealtimeContextData,
tool,
} from '@openai/agents/realtime';
import { handleRefundRequest } from './serverAgent';
import z from 'zod';
const refundSupervisorParameters = z.object({
request: z.string(),
});
const refundSupervisor = tool<
typeof refundSupervisorParameters,
RealtimeContextData
>({
name: 'escalateToRefundSupervisor',
description: 'Escalate a refund request to the refund supervisor',
parameters: refundSupervisorParameters,
execute: async ({ request }, details) => {
// This will execute on the server
return handleRefundRequest(request, details?.context?.history ?? []);
},
});
const agent = new RealtimeAgent({
name: 'Customer Support',
instructions:
'You are a customer support agent. If you receive any requests for refunds, you need to delegate to your supervisor.',
tools: [refundSupervisor],
});
```
The code below then runs on the server, in this example via a Next.js Server Action.
```typescript
// This runs on the server
import 'server-only';
import { Agent, run } from '@openai/agents';
import type { RealtimeItem } from '@openai/agents/realtime';
import z from 'zod';
const agent = new Agent({
name: 'Refund Expert',
instructions:
'You are a refund expert. You are given a request to process a refund and you need to determine if the request is valid.',
model: 'gpt-5.4',
outputType: z.object({
reasong: z.string(),
refundApproved: z.boolean(),
}),
});
export async function handleRefundRequest(
request: string,
history: RealtimeItem[],
) {
const input = `
The user has requested a refund.
The request is: ${request}
Current conversation history:
${JSON.stringify(history, null, 2)}
`.trim();
const result = await run(agent, input);
return JSON.stringify(result.finalOutput, null, 2);
}
```
# Voice Agents Quickstart
> Build your first realtime voice assistant using the OpenAI Agents SDK in minutes.
Note
This quickstart uses `@openai/agents`, which is the recommended default for most apps. If you prefer the standalone Realtime package, install `@openai/agents-realtime` and replace imports from `@openai/agents/realtime` with `@openai/agents-realtime` in the examples below.
## Project setup and credentials
[Section titled “Project setup and credentials”](#project-setup-and-credentials)
1. **Create a project**
In this quickstart we will create a voice agent you can use in the browser. If you want to scaffold a new project, you can start with [`Next.js`](https://nextjs.org/docs/getting-started/installation) or [`Vite`](https://vite.dev/guide/installation.html).
```bash
npm create vite@latest my-project -- --template vanilla-ts
```
2. **Install the recommended package** (requires Zod v4)
```bash
npm install @openai/agents zod
```
3. **Generate a client ephemeral token**
As this application will run in the user’s browser, we need a secure way to connect to the model through the Realtime API. The recommended flow matches the official [Realtime API with WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc/) guide: your backend creates a short-lived ephemeral client token, then your browser uses that token to establish the WebRTC connection. For testing purposes you can also generate a token using `curl` and your regular OpenAI API key.
```bash
export OPENAI_API_KEY="sk-proj-...(your own key here)"
curl -X POST https://api.openai.com/v1/realtime/client_secrets \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"session": {
"type": "realtime",
"model": "gpt-realtime-2"
}
}'
```
The response contains a top-level `value` field that starts with the `ek_` prefix, plus the effective `session` object. Use `value` as the client secret when establishing the WebRTC connection. This token is short-lived, so your backend should mint a fresh one when needed. If your browser session needs hosted MCP tools with `authorization` or custom `headers`, include that hosted MCP configuration in the server-side `session` payload you send to `POST /v1/realtime/client_secrets` instead of exposing those credentials in browser code.
Note
Production browser flow: the browser asks your backend for a fresh ephemeral token, your backend calls `POST /v1/realtime/client_secrets` with a server API key, and the browser passes the returned `ek_...` token to `session.connect(...)`.
## Create and connect the voice agent
[Section titled “Create and connect the voice agent”](#create-and-connect-the-voice-agent)
1. **Create your first Agent**
Creating a new [`RealtimeAgent`](/openai-agents-js/openai/agents-realtime/classes/realtimeagent/) is very similar to creating a regular [`Agent`](/openai-agents-js/guides/agents).
```typescript
import { RealtimeAgent } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Assistant',
instructions: 'You are a helpful assistant.',
});
```
2. **Create a session**
Unlike a regular agent, a voice agent is continuously running inside a `RealtimeSession` that handles the conversation and connection to the model over time. This session also manages audio processing, interruptions, and the broader conversation lifecycle that you will configure later on.
```typescript
import { RealtimeSession } from '@openai/agents/realtime';
const session = new RealtimeSession(agent, {
model: 'gpt-realtime-2',
});
```
The `RealtimeSession` constructor takes an `agent` as the first argument. This agent will be the first one your user interacts with.
3. **Connect to the session**
To connect to the session you need to pass the client ephemeral token you generated earlier.
```typescript
await session.connect({ apiKey: 'ek_...(put your own key here)' });
```
In the browser, this connects to the Realtime API using WebRTC and automatically configures microphone capture and audio playback for you. On that default WebRTC path, the SDK sends the initial session configuration as soon as the data channel opens and tries to wait for the matching `session.updated` acknowledgement before `connect()` resolves, with a timeout fallback if that acknowledgement never arrives. If you run `RealtimeSession` in a server runtime such as Node.js, the SDK automatically falls back to WebSocket instead; on the WebSocket path, `connect()` resolves after the socket opens and the initial config has been sent, so `session.updated` may arrive slightly later. You can learn more about the transport choices in the [Realtime Transport Layer](/openai-agents-js/guides/voice-agents/transport) guide.
Note
If you want lower-level control over the peer connection or raw transport events, see the [`/raw-client` example in `examples/realtime-next`](https://github.com/openai/openai-agents-js/tree/main/examples/realtime-next).
## Run and test the app
[Section titled “Run and test the app”](#run-and-test-the-app)
1. **Putting it all together**
```typescript
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
export async function setupCounter(element: HTMLButtonElement) {
// ....
// for quickly start, you can append the following code to the auto-generated TS code
const agent = new RealtimeAgent({
name: 'Assistant',
instructions: 'You are a helpful assistant.',
});
const session = new RealtimeSession(agent);
// Automatically connects your microphone and audio output in the browser via WebRTC.
try {
await session.connect({
// To get this ephemeral key string, you can run the following command or implement the equivalent on the server side:
// curl -s -X POST https://api.openai.com/v1/realtime/client_secrets -H "Authorization: Bearer $OPENAI_API_KEY" -H "Content-Type: application/json" -d '{"session": {"type": "realtime", "model": "gpt-realtime-2"}}' | jq .value
apiKey: 'ek_...(put your own key here)',
});
console.log('You are connected!');
} catch (e) {
console.error(e);
}
}
```
2. **Fire up the app and start talking**
Start your web server and open the page that includes your new Realtime Agent code. You should see a microphone permission request. Once you grant access, you should be able to start talking to your agent.
```bash
npm run dev
```
## Next Steps
[Section titled “Next Steps”](#next-steps)
From here you can start designing and building your own voice agent:
* Add [tools](/openai-agents-js/guides/voice-agents/build#tools), [handoffs](/openai-agents-js/guides/voice-agents/build#handoffs), and [guardrails](/openai-agents-js/guides/voice-agents/build#guardrails).
* Learn how [turn detection and voice activity detection](/openai-agents-js/guides/voice-agents/build#turn-detection-and-voice-activity-detection), [interruptions](/openai-agents-js/guides/voice-agents/build#interruptions), and [manual response control](/openai-agents-js/guides/voice-agents/build#manual-response-control) affect the conversation loop.
* Add [text input](/openai-agents-js/guides/voice-agents/build#text-input), [image input](/openai-agents-js/guides/voice-agents/build#image-input), and [session history management](/openai-agents-js/guides/voice-agents/build#conversation-history-management).
* Choose the right transport for your deployment: [WebRTC](/openai-agents-js/guides/voice-agents/transport#webrtc-is-the-default-browser-choice), [WebSocket](/openai-agents-js/guides/voice-agents/transport#websocket-is-the-default-server-choice), or [a custom transport](/openai-agents-js/guides/voice-agents/transport#bring-your-own-transport).
# Realtime Transport Layer
> Learn about the different transport layers that can be used with Realtime Agents.
Choose the transport based on where the session runs and how much raw media or event control you need.
| Scenario | Recommended transport | Why |
| ----------------------------------------------- | ------------------------------ | ------------------------------------------------------------------------------------------------------ |
| Browser speech-to-speech app | `OpenAIRealtimeWebRTC` | Lowest-friction path. The SDK manages microphone capture, playback, and the WebRTC connection for you. |
| Server-side voice loop or custom audio pipeline | `OpenAIRealtimeWebSocket` | Works well when you already control audio capture/playback and want direct event access. |
| SIP or telephony bridge | `OpenAIRealtimeSIP` | Attaches a `RealtimeSession` to an existing SIP-initiated Realtime call by `callId`. |
| Cloudflare Workers / workerd | Cloudflare extension transport | workerd cannot open outbound WebSockets with the global `WebSocket` constructor. |
| Provider-specific phone flow on Twilio | Twilio extension transport | Handles Twilio audio forwarding and interruption behavior for you. |
Note
If you are building a browser product and do not have a reason to manage raw audio yourself, start with WebRTC. If you are running on the server or bridging another media system, start with WebSocket or SIP.
## Default transport layers
[Section titled “Default transport layers”](#default-transport-layers)
### WebRTC is the default browser choice
[Section titled “WebRTC is the default browser choice”](#webrtc-is-the-default-browser-choice)
The default browser transport uses WebRTC. Audio is captured from the microphone and played back automatically, which is why the [Quickstart](/openai-agents-js/guides/voice-agents/quickstart) can connect with just an ephemeral token and `session.connect(...)`.
On this path, `session.connect()` tries to wait until the initial session configuration has been acknowledged with `session.updated` before it resolves, so your instructions and tools are applied before audio starts flowing. There is still a timeout fallback if that acknowledgement never arrives.
To use your own media stream or audio element, provide an `OpenAIRealtimeWebRTC` instance when creating the session.
```typescript
import {
RealtimeAgent,
RealtimeSession,
OpenAIRealtimeWebRTC,
} from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Greeter',
instructions: 'Greet the user with cheer and answer questions.',
});
async function main() {
const transport = new OpenAIRealtimeWebRTC({
mediaStream: await navigator.mediaDevices.getUserMedia({ audio: true }),
audioElement: document.createElement('audio'),
});
const customSession = new RealtimeSession(agent, { transport });
}
```
For lower-level customization, `OpenAIRealtimeWebRTC` also accepts `changePeerConnection`, which lets you inspect or replace the freshly created `RTCPeerConnection` before the offer is generated.
### WebSocket is the default server choice
[Section titled “WebSocket is the default server choice”](#websocket-is-the-default-server-choice)
Pass `transport: 'websocket'` or an instance of `OpenAIRealtimeWebSocket` when creating the session to use a WebSocket connection instead of WebRTC. This works well for server-side use cases, telephony bridges, and custom audio pipelines.
On the WebSocket path, `session.connect()` resolves once the socket is open and the initial config has been sent. The matching `session.updated` event may arrive slightly later, so do not assume `connect()` means that update has already been echoed back.
```typescript
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Greeter',
instructions: 'Greet the user with cheer and answer questions.',
});
const myRecordedArrayBuffer = new ArrayBuffer(0);
const wsSession = new RealtimeSession(agent, {
transport: 'websocket',
model: 'gpt-realtime-2',
});
await wsSession.connect({ apiKey: process.env.OPENAI_API_KEY! });
wsSession.on('audio', (event) => {
// event.data is a chunk of PCM16 audio
});
wsSession.sendAudio(myRecordedArrayBuffer);
```
Use any recording/playback library to handle the raw PCM16 audio bytes.
For advanced integrations, `OpenAIRealtimeWebSocket` accepts `createWebSocket()` so you can supply your own socket implementation, and `skipOpenEventListeners` when that custom connector is responsible for transitioning the socket into the connected state. The Cloudflare transport in `@openai/agents-extensions` is built on these hooks.
### SIP is for call providers and telephony bridges
[Section titled “SIP is for call providers and telephony bridges”](#sip-is-for-call-providers-and-telephony-bridges)
Use `OpenAIRealtimeSIP` when you want a `RealtimeSession` to attach to an existing SIP-initiated Realtime call. It is a thin SIP-aware transport: audio is handled by the SIP call itself, and you connect the SDK session by `callId`.
1. Accept the incoming call by generating an initial session configuration with `OpenAIRealtimeSIP.buildInitialConfig()`. This ensures the SIP invitation and the later SDK session start from the same defaults.
2. Attach a `RealtimeSession` that uses the `OpenAIRealtimeSIP` transport and connect with the `callId` issued by the provider webhook.
3. If you need provider-specific media forwarding or event bridging, use an integration transport such as the Twilio extension.
Caution
SIP call acceptance only supports a subset of Realtime turn-detection fields. `OpenAIRealtimeSIP.buildInitialConfig()` throws locally if your config includes `threshold`, `prefixPaddingMs`, or `silenceDurationMs` (or their snake\_case equivalents) because the Realtime Calls API rejects those `session.audio.input.turn_detection` properties for SIP sessions.
```typescript
import OpenAI from 'openai';
import {
OpenAIRealtimeSIP,
RealtimeAgent,
RealtimeSession,
type RealtimeSessionOptions,
} from '@openai/agents/realtime';
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY!,
webhookSecret: process.env.OPENAI_WEBHOOK_SECRET!,
});
const agent = new RealtimeAgent({
name: 'Receptionist',
instructions:
'Welcome the caller, answer scheduling questions, and hand off if the caller requests a human.',
});
const sessionOptions: Partial = {
model: 'gpt-realtime-2',
config: {
audio: {
input: {
turnDetection: { type: 'semantic_vad', interruptResponse: true },
},
},
},
};
export async function acceptIncomingCall(callId: string): Promise {
const initialConfig = await OpenAIRealtimeSIP.buildInitialConfig(
agent,
sessionOptions,
);
await openai.realtime.calls.accept(callId, initialConfig);
}
export async function attachRealtimeSession(
callId: string,
): Promise {
const session = new RealtimeSession(agent, {
transport: new OpenAIRealtimeSIP(),
...sessionOptions,
});
session.on('history_added', (item) => {
console.log('Realtime update:', item.type);
});
await session.connect({
apiKey: process.env.OPENAI_API_KEY!,
callId,
});
return session;
}
```
### Cloudflare Workers and workerd
[Section titled “Cloudflare Workers and workerd”](#cloudflare-workers-and-workerd)
Cloudflare Workers and other workerd runtimes cannot open outbound WebSockets using the global `WebSocket` constructor. Use the Cloudflare transport from the extensions package, which performs the `fetch()`-based upgrade internally.
```typescript
import { CloudflareRealtimeTransportLayer } from '@openai/agents-extensions';
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'My Agent',
});
// Create a transport that connects to OpenAI Realtime via Cloudflare/workerd's fetch-based upgrade.
const cfTransport = new CloudflareRealtimeTransportLayer({
url: 'wss://api.openai.com/v1/realtime?model=gpt-realtime-2',
});
const session = new RealtimeSession(agent, {
// Set your own transport.
transport: cfTransport,
});
```
For the full setup, read [Realtime Agents on Cloudflare](/openai-agents-js/extensions/cloudflare).
### Twilio phone calls
[Section titled “Twilio phone calls”](#twilio-phone-calls)
You can connect a `RealtimeSession` to Twilio using either raw WebSockets or the dedicated Twilio transport in `@openai/agents-extensions`. The dedicated transport is the better default when you want the SDK to handle interruption timing and audio forwarding for Twilio Media Streams.
For the full setup, read [Realtime Agents on Twilio](/openai-agents-js/extensions/twilio).
### Bring your own transport
[Section titled “Bring your own transport”](#bring-your-own-transport)
If you want to use a different speech-to-speech API or have your own custom transport mechanism, you can implement the `RealtimeTransportLayer` interface and emit the `RealtimeTransportEventTypes` events yourself.
## Access raw Realtime events when you need them
[Section titled “Access raw Realtime events when you need them”](#access-raw-realtime-events-when-you-need-them)
If you want more direct access to the underlying Realtime API, you have two options.
### Option 1 - Accessing the transport layer
[Section titled “Option 1 - Accessing the transport layer”](#option-1---accessing-the-transport-layer)
If you still want to benefit from all of the capabilities of the `RealtimeSession` you can access your transport layer through `session.transport`.
The transport layer emits every event it receives under the `*` event and you can send raw events using `sendEvent()`. This is the escape hatch for low-level operations such as `session.update`, `response.create`, or `response.cancel`.
```typescript
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Greeter',
instructions: 'Greet the user with cheer and answer questions.',
});
const session = new RealtimeSession(agent, {
model: 'gpt-realtime-2',
});
session.transport.on('*', (event) => {
// JSON parsed version of the event received on the connection
});
// Send any valid event as JSON. For example triggering a new response
session.transport.sendEvent({
type: 'response.create',
// ...
});
```
### Option 2 - Only using the transport layer
[Section titled “Option 2 - Only using the transport layer”](#option-2---only-using-the-transport-layer)
If you do not need automatic tool execution, guardrails, or local history management, you can also use the transport layer as a “thin” client that just manages connection and interruptions.
```typescript
import { OpenAIRealtimeWebRTC } from '@openai/agents/realtime';
const client = new OpenAIRealtimeWebRTC();
const audioBuffer = new ArrayBuffer(0);
await client.connect({
apiKey: '',
model: 'gpt-realtime-2',
initialSessionConfig: {
instructions: 'Speak like a pirate',
outputModalities: ['audio'],
audio: {
input: {
format: 'pcm16',
},
output: {
format: 'pcm16',
voice: 'ash',
},
},
},
});
// optionally for WebSockets
client.on('audio', (newAudio) => {});
client.sendAudio(audioBuffer);
```
# Agent
The class representing an AI agent configured with instructions, tools, guardrails, handoffs and more.
We strongly recommend passing `instructions`, which is the “system prompt” for the agent. In addition, you can pass `handoffDescription`, which is a human-readable description of the agent, used when the agent is used inside tools/handoffs.
Agents are generic on the context type. The context is a (mutable) object you create. It is passed to tool functions, handoffs, guardrails, etc.
## Extends
[Section titled “Extends”](#extends)
* [`AgentHooks`](/openai-agents-js/openai/agents-core/classes/agenthooks/)<`TContext`, `TOutput`>
## Type Parameters
[Section titled “Type Parameters”](#type-parameters)
| Type Parameter | Default type |
| ----------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| `TContext` | [`UnknownContext`](/openai-agents-js/openai/agents-core/type-aliases/unknowncontext/) |
| `TOutput` *extends* [`AgentOutputType`](/openai-agents-js/openai/agents-core/type-aliases/agentoutputtype/) | [`TextOutput`](/openai-agents-js/openai/agents-core/type-aliases/textoutput/) |
## Implements
[Section titled “Implements”](#implements)
* [`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/)<`TContext`, `TOutput`>
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new Agent(config): Agent;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type | Description |
| -------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `config` | { `handoffDescription?`: `string`; `handoffOutputTypeWarningEnabled?`: `boolean`; `handoffs?`: ( \| `Agent`<`any`, `any`> \| [`Handoff`](/openai-agents-js/openai/agents-core/classes/handoff/)<`any`, `TOutput`>)\[]; `inputGuardrails?`: [`InputGuardrail`](/openai-agents-js/openai/agents-core/interfaces/inputguardrail/)\[]; `instructions?`: `string` \| ((`runContext`, `agent`) => `string` \| `Promise`<`string`>); `mcpConfig?`: { `convertSchemasToStrict?`: `boolean`; `errorFunction?`: \| [`MCPToolErrorFunction`](/openai-agents-js/openai/agents-core/type-aliases/mcptoolerrorfunction/) \| `null`; `includeServerInToolNames?`: `boolean`; }; `mcpServers?`: [`MCPServer`](/openai-agents-js/openai/agents-core/interfaces/mcpserver/)\[]; `model?`: \| `string` \| [`Model`](/openai-agents-js/openai/agents-core/interfaces/model/); `modelSettings?`: [`ModelSettings`](/openai-agents-js/openai/agents-core/type-aliases/modelsettings/); `name`: `string`; `outputGuardrails?`: [`OutputGuardrail`](/openai-agents-js/openai/agents-core/interfaces/outputguardrail/)<`TOutput`, `TContext`>\[]; `outputType?`: `TOutput`; `prompt?`: `Prompt` \| ((`runContext`, `agent`) => `Prompt` \| `Promise`<`Prompt`>); `resetToolChoice?`: `boolean`; `tools?`: [`Tool`](/openai-agents-js/openai/agents-core/type-aliases/tool/)<`TContext`>\[]; `toolUseBehavior?`: [`ToolUseBehavior`](/openai-agents-js/openai/agents-core/type-aliases/toolusebehavior/); } | ‐ |
| `config.handoffDescription?` | `string` | A description of the agent. This is used when the agent is used as a handoff, so that an LLM knows what it does and when to invoke it. |
| `config.handoffOutputTypeWarningEnabled?` | `boolean` | The warning log would be enabled when multiple output types by handoff agents are detected. |
| `config.handoffs?` | ( \| `Agent`<`any`, `any`> \| [`Handoff`](/openai-agents-js/openai/agents-core/classes/handoff/)<`any`, `TOutput`>)\[] | Handoffs are sub-agents that the agent can delegate to. You can provide a list of handoffs, and the agent can choose to delegate to them if relevant. Allows for separation of concerns and modularity. |
| `config.inputGuardrails?` | [`InputGuardrail`](/openai-agents-js/openai/agents-core/interfaces/inputguardrail/)\[] | A list of checks that run in parallel to the agent by default; set `runInParallel` to false to block LLM/tool calls until the guardrail completes. Runs only if the agent is the first agent in the chain. |
| `config.instructions?` | `string` \| ((`runContext`, `agent`) => `string` \| `Promise`<`string`>) | The instructions for the agent. Will be used as the “system prompt” when this agent is invoked. Describes what the agent should do, and how it responds.Can either be a string, or a function that dynamically generates instructions for the agent. If you provide a function, it will be called with the context and the agent instance. It must return a string. |
| `config.mcpConfig?` | { `convertSchemasToStrict?`: `boolean`; `errorFunction?`: \| [`MCPToolErrorFunction`](/openai-agents-js/openai/agents-core/type-aliases/mcptoolerrorfunction/) \| `null`; `includeServerInToolNames?`: `boolean`; } | Configuration for MCP servers used by this agent. |
| `config.mcpConfig.convertSchemasToStrict?` | `boolean` | Try to convert MCP tool schemas to strict JSON schema. |
| `config.mcpConfig.errorFunction?` | \| [`MCPToolErrorFunction`](/openai-agents-js/openai/agents-core/type-aliases/mcptoolerrorfunction/) \| `null` | Optional function to convert MCP tool failures into model-visible messages. Set to null to rethrow errors instead of converting them. Server-level errorFunction values take precedence. |
| `config.mcpConfig.includeServerInToolNames?` | `boolean` | Prefix local MCP tool names with their server name before exposing them to the model. The SDK still invokes the original MCP tool name on the original server. |
| `config.mcpServers?` | [`MCPServer`](/openai-agents-js/openai/agents-core/interfaces/mcpserver/)\[] | A list of [Model Context Protocol](https://modelcontextprotocol.io/) servers the agent can use. Every time the agent runs, it will include tools from these servers in the list of available tools.NOTE: You are expected to manage the lifecycle of these servers. Specifically, you must call `server.connect()` before passing it to the agent, and `server.close()` when the server is no longer needed. Consider using `connectMcpServers` or `MCPServers` to keep open/close in the same place. |
| `config.model?` | \| `string` \| [`Model`](/openai-agents-js/openai/agents-core/interfaces/model/) | The model implementation to use when invoking the LLM.By default, if not set, the agent will use the default model returned by getDefaultModel (currently “gpt-5.4-mini”). |
| `config.modelSettings?` | [`ModelSettings`](/openai-agents-js/openai/agents-core/type-aliases/modelsettings/) | Configures model-specific tuning parameters (e.g. temperature, top\_p, etc.) |
| `config.name` | `string` | ‐ |
| `config.outputGuardrails?` | [`OutputGuardrail`](/openai-agents-js/openai/agents-core/interfaces/outputguardrail/)<`TOutput`, `TContext`>\[] | A list of checks that run on the final output of the agent, after generating a response. Runs only if the agent produces a final output. |
| `config.outputType?` | `TOutput` | The type of the output object. If not provided, the output will be a string. |
| `config.prompt?` | `Prompt` \| ((`runContext`, `agent`) => `Prompt` \| `Promise`<`Prompt`>) | The prompt template to use for the agent (OpenAI Responses API only).Can either be a prompt template object, or a function that returns a prompt template object. If a function is provided, it will be called with the run context and the agent instance. It must return a prompt template object. |
| `config.resetToolChoice?` | `boolean` | Whether to reset the tool choice to the default value after a tool has been called. Defaults to `true`. This ensures that the agent doesn’t enter an infinite loop of tool usage. |
| `config.tools?` | [`Tool`](/openai-agents-js/openai/agents-core/type-aliases/tool/)<`TContext`>\[] | A list of tools the agent can use. |
| `config.toolUseBehavior?` | [`ToolUseBehavior`](/openai-agents-js/openai/agents-core/type-aliases/toolusebehavior/) | This lets you configure how tool use is handled.- run\_llm\_again: The default behavior. Tools are run, and then the LLM receives the results and gets to respond.
- stop\_on\_first\_tool: The output of the first tool call is used as the final output. This means that the LLM does not process the result of the tool call.
- A list of tool names: The agent will stop running if any of the tools in the list are called. The final output will be the output of the first matching tool call. The LLM does not process the result of the tool call.
- A function: if you pass a function, it will be called with the run context and the list of tool results. It must return a `ToolsToFinalOutputResult`, which determines whether the tool call resulted in a final output.NOTE: This configuration is specific to `FunctionTools`. Hosted tools, such as file search, web search, etc. are always processed by the LLM |
#### Returns
[Section titled “Returns”](#returns)
`Agent`<`TContext`, `TOutput`>
#### Overrides
[Section titled “Overrides”](#overrides)
[`AgentHooks`](/openai-agents-js/openai/agents-core/classes/agenthooks/).[`constructor`](/openai-agents-js/openai/agents-core/classes/agenthooks/#constructor)
## Properties
[Section titled “Properties”](#properties)
### handoffDescription
[Section titled “handoffDescription”](#handoffdescription)
```ts
handoffDescription: string;
```
A description of the agent. This is used when the agent is used as a handoff, so that an LLM knows what it does and when to invoke it.
#### Implementation of
[Section titled “Implementation of”](#implementation-of)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`handoffDescription`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#handoffdescription)
***
### handoffs
[Section titled “handoffs”](#handoffs)
```ts
handoffs: (
| Agent
| Handoff)[];
```
Handoffs are sub-agents that the agent can delegate to. You can provide a list of handoffs, and the agent can choose to delegate to them if relevant. Allows for separation of concerns and modularity.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-1)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`handoffs`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#handoffs)
***
### inputGuardrails
[Section titled “inputGuardrails”](#inputguardrails)
```ts
inputGuardrails: InputGuardrail[];
```
A list of checks that run in parallel to the agent by default; set `runInParallel` to false to block LLM/tool calls until the guardrail completes. Runs only if the agent is the first agent in the chain.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-2)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`inputGuardrails`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#inputguardrails)
***
### instructions
[Section titled “instructions”](#instructions)
```ts
instructions: string | ((runContext, agent) => string | Promise);
```
The instructions for the agent. Will be used as the “system prompt” when this agent is invoked. Describes what the agent should do, and how it responds.
Can either be a string, or a function that dynamically generates instructions for the agent. If you provide a function, it will be called with the context and the agent instance. It must return a string.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-3)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`instructions`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#instructions)
***
### mcpConfig
[Section titled “mcpConfig”](#mcpconfig)
```ts
mcpConfig: object;
```
Configuration for MCP servers used by this agent.
| Name | Type | Description |
| --------------------------- | -------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `convertSchemasToStrict?` | `boolean` | Try to convert MCP tool schemas to strict JSON schema. |
| `errorFunction?` | \| [`MCPToolErrorFunction`](/openai-agents-js/openai/agents-core/type-aliases/mcptoolerrorfunction/) \| `null` | Optional function to convert MCP tool failures into model-visible messages. Set to null to rethrow errors instead of converting them. Server-level errorFunction values take precedence. |
| `includeServerInToolNames?` | `boolean` | Prefix local MCP tool names with their server name before exposing them to the model. The SDK still invokes the original MCP tool name on the original server. |
#### Implementation of
[Section titled “Implementation of”](#implementation-of-4)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`mcpConfig`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#mcpconfig)
***
### mcpServers
[Section titled “mcpServers”](#mcpservers)
```ts
mcpServers: MCPServer[];
```
A list of [Model Context Protocol](https://modelcontextprotocol.io/) servers the agent can use. Every time the agent runs, it will include tools from these servers in the list of available tools.
NOTE: You are expected to manage the lifecycle of these servers. Specifically, you must call `server.connect()` before passing it to the agent, and `server.close()` when the server is no longer needed. Consider using `connectMcpServers` or `MCPServers` to keep open/close in the same place.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-5)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`mcpServers`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#mcpservers)
***
### model
[Section titled “model”](#model)
```ts
model:
| string
| Model;
```
The model implementation to use when invoking the LLM.
By default, if not set, the agent will use the default model returned by getDefaultModel (currently “gpt-5.4-mini”).
#### Implementation of
[Section titled “Implementation of”](#implementation-of-6)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`model`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#model)
***
### modelSettings
[Section titled “modelSettings”](#modelsettings)
```ts
modelSettings: ModelSettings;
```
Configures model-specific tuning parameters (e.g. temperature, top\_p, etc.)
#### Implementation of
[Section titled “Implementation of”](#implementation-of-7)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`modelSettings`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#modelsettings)
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of-8)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`name`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#name)
***
### outputGuardrails
[Section titled “outputGuardrails”](#outputguardrails)
```ts
outputGuardrails: OutputGuardrail, TContext>[];
```
A list of checks that run on the final output of the agent, after generating a response. Runs only if the agent produces a final output.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-9)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`outputGuardrails`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#outputguardrails)
***
### outputType
[Section titled “outputType”](#outputtype)
```ts
outputType: TOutput;
```
The type of the output object. If not provided, the output will be a string.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-10)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`outputType`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#outputtype)
***
### prompt?
[Section titled “prompt?”](#prompt)
```ts
optional prompt?: Prompt | ((runContext, agent) => Prompt | Promise);
```
The prompt template to use for the agent (OpenAI Responses API only).
Can either be a prompt template object, or a function that returns a prompt template object. If a function is provided, it will be called with the run context and the agent instance. It must return a prompt template object.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-11)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`prompt`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#prompt)
***
### resetToolChoice
[Section titled “resetToolChoice”](#resettoolchoice)
```ts
resetToolChoice: boolean;
```
Whether to reset the tool choice to the default value after a tool has been called. Defaults to `true`. This ensures that the agent doesn’t enter an infinite loop of tool usage.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-12)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`resetToolChoice`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#resettoolchoice)
***
### tools
[Section titled “tools”](#tools)
```ts
tools: Tool[];
```
A list of tools the agent can use.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-13)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`tools`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#tools)
***
### toolUseBehavior
[Section titled “toolUseBehavior”](#toolusebehavior)
```ts
toolUseBehavior: ToolUseBehavior;
```
This lets you configure how tool use is handled.
* run\_llm\_again: The default behavior. Tools are run, and then the LLM receives the results and gets to respond.
* stop\_on\_first\_tool: The output of the first tool call is used as the final output. This means that the LLM does not process the result of the tool call.
* A list of tool names: The agent will stop running if any of the tools in the list are called. The final output will be the output of the first matching tool call. The LLM does not process the result of the tool call.
* A function: if you pass a function, it will be called with the run context and the list of tool results. It must return a `ToolsToFinalOutputResult`, which determines whether the tool call resulted in a final output.
NOTE: This configuration is specific to `FunctionTools`. Hosted tools, such as file search, web search, etc. are always processed by the LLM
#### Implementation of
[Section titled “Implementation of”](#implementation-of-14)
[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/).[`toolUseBehavior`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/#toolusebehavior)
***
### DEFAULT\_MODEL\_PLACEHOLDER
[Section titled “DEFAULT\_MODEL\_PLACEHOLDER”](#default_model_placeholder)
```ts
static DEFAULT_MODEL_PLACEHOLDER: string = '';
```
## Accessors
[Section titled “Accessors”](#accessors)
### outputSchemaName
[Section titled “outputSchemaName”](#outputschemaname)
#### Get Signature
[Section titled “Get Signature”](#get-signature)
```ts
get outputSchemaName(): string;
```
Output schema name.
##### Returns
[Section titled “Returns”](#returns-1)
`string`
## Methods
[Section titled “Methods”](#methods)
### asTool()
[Section titled “asTool()”](#astool)
#### Call Signature
[Section titled “Call Signature”](#call-signature)
```ts
asTool(this, options): AgentTool>;
```
Transform this agent into a tool, callable by other agents.
This is different from handoffs in two ways:
1. In handoffs, the new agent receives the conversation history. In this tool, the new agent receives generated input.
2. In handoffs, the new agent takes over the conversation. In this tool, the new agent is called as a tool, and the conversation is continued by the original agent.
##### Type Parameters
[Section titled “Type Parameters”](#type-parameters-1)
| Type Parameter | Default type |
| ------------------------------------------------- | ------------------------------ |
| `TAgent` *extends* `Agent`<`TContext`, `TOutput`> | `Agent`<`TContext`, `TOutput`> |
##### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type | Description |
| --------- | --------------------------------------------------- | --------------------- |
| `this` | `TAgent` | ‐ |
| `options` | `AgentToolOptionsWithDefault`<`TContext`, `TAgent`> | Options for the tool. |
##### Returns
[Section titled “Returns”](#returns-2)
`AgentTool`<`TContext`, `TAgent`, `ZodObject`<{ `input`: `ZodString`; }, `$strip`>>
A tool that runs the agent and returns the output text.
#### Call Signature
[Section titled “Call Signature”](#call-signature-1)
```ts
asTool(this, options): AgentTool;
```
Transform this agent into a tool, callable by other agents.
This is different from handoffs in two ways:
1. In handoffs, the new agent receives the conversation history. In this tool, the new agent receives generated input.
2. In handoffs, the new agent takes over the conversation. In this tool, the new agent is called as a tool, and the conversation is continued by the original agent.
##### Type Parameters
[Section titled “Type Parameters”](#type-parameters-2)
| Type Parameter | Default type |
| -------------------------------------------------- | ------------------------------------------------ |
| `TAgent` *extends* `Agent`<`TContext`, `TOutput`> | `Agent`<`TContext`, `TOutput`> |
| `TParameters` *extends* `AgentToolInputParameters` | `ZodObject`<{ `input`: `ZodString`; }, `$strip`> |
##### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type | Description |
| --------- | --------------------------------------------------------------------- | --------------------- |
| `this` | `TAgent` | ‐ |
| `options` | `AgentToolOptionsWithParameters`<`TContext`, `TAgent`, `TParameters`> | Options for the tool. |
##### Returns
[Section titled “Returns”](#returns-3)
`AgentTool`<`TContext`, `TAgent`, `TParameters`>
A tool that runs the agent and returns the output text.
***
### clone()
[Section titled “clone()”](#clone)
```ts
clone(config): Agent;
```
Makes a copy of the agent, with the given arguments changed. For example, you could do:
```plaintext
const newAgent = agent.clone({ instructions: 'New instructions' })
```
#### Parameters
[Section titled “Parameters”](#parameters-3)
| Parameter | Type | Description |
| --------- | ----------------------------------------------------------------------------------------------------------------------------- | ---------------------------------- |
| `config` | `Partial`<[`AgentConfiguration`](/openai-agents-js/openai/agents-core/interfaces/agentconfiguration/)<`TContext`, `TOutput`>> | A partial configuration to change. |
#### Returns
[Section titled “Returns”](#returns-4)
`Agent`<`TContext`, `TOutput`>
A new agent with the given changes.
***
### emit()
[Section titled “emit()”](#emit)
```ts
emit(type, ...args): boolean;
```
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-3)
| Type Parameter |
| ------------------------------------------------------------ |
| `K` *extends* keyof `AgentHookEvents`<`TContext`, `TOutput`> |
#### Parameters
[Section titled “Parameters”](#parameters-4)
| Parameter | Type |
| --------- | ---------------------------------------------- |
| `type` | `K` |
| …`args` | `AgentHookEvents`<`TContext`, `TOutput`>\[`K`] |
#### Returns
[Section titled “Returns”](#returns-5)
`boolean`
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`AgentHooks`](/openai-agents-js/openai/agents-core/classes/agenthooks/).[`emit`](/openai-agents-js/openai/agents-core/classes/agenthooks/#emit)
***
### getAllTools()
[Section titled “getAllTools()”](#getalltools)
```ts
getAllTools(runContext): Promise[]>;
```
ALl agent tools, including the MCPl and function tools.
#### Parameters
[Section titled “Parameters”](#parameters-5)
| Parameter | Type |
| ------------ | ------------------------------------------------------------------------------------ |
| `runContext` | [`RunContext`](/openai-agents-js/openai/agents-core/classes/runcontext/)<`TContext`> |
#### Returns
[Section titled “Returns”](#returns-6)
`Promise`<[`Tool`](/openai-agents-js/openai/agents-core/type-aliases/tool/)<`TContext`>\[]>
all configured tools
***
### getEnabledHandoffs()
[Section titled “getEnabledHandoffs()”](#getenabledhandoffs)
```ts
getEnabledHandoffs(runContext): Promise[]>;
```
Returns the handoffs that should be exposed to the model for the current run.
Handoffs that provide an `isEnabled` function returning `false` are omitted.
#### Parameters
[Section titled “Parameters”](#parameters-6)
| Parameter | Type |
| ------------ | ------------------------------------------------------------------------------------ |
| `runContext` | [`RunContext`](/openai-agents-js/openai/agents-core/classes/runcontext/)<`TContext`> |
#### Returns
[Section titled “Returns”](#returns-7)
`Promise`<[`Handoff`](/openai-agents-js/openai/agents-core/classes/handoff/)<`any`, `any`>\[]>
***
### getMcpTools()
[Section titled “getMcpTools()”](#getmcptools)
```ts
getMcpTools(runContext): Promise[]>;
```
Fetches the available tools from the MCP servers.
#### Parameters
[Section titled “Parameters”](#parameters-7)
| Parameter | Type |
| ------------ | ------------------------------------------------------------------------------------ |
| `runContext` | [`RunContext`](/openai-agents-js/openai/agents-core/classes/runcontext/)<`TContext`> |
#### Returns
[Section titled “Returns”](#returns-8)
`Promise`<[`Tool`](/openai-agents-js/openai/agents-core/type-aliases/tool/)<`TContext`>\[]>
the MCP powered tools
***
### getPrompt()
[Section titled “getPrompt()”](#getprompt)
```ts
getPrompt(runContext): Promise;
```
Returns the prompt template for the agent, if defined.
If the agent has a function as its prompt, this function will be called with the runContext and the agent instance.
#### Parameters
[Section titled “Parameters”](#parameters-8)
| Parameter | Type |
| ------------ | ------------------------------------------------------------------------------------ |
| `runContext` | [`RunContext`](/openai-agents-js/openai/agents-core/classes/runcontext/)<`TContext`> |
#### Returns
[Section titled “Returns”](#returns-9)
`Promise`<`Prompt` | `undefined`>
***
### getSystemPrompt()
[Section titled “getSystemPrompt()”](#getsystemprompt)
```ts
getSystemPrompt(runContext): Promise;
```
Returns the system prompt for the agent.
If the agent has a function as its instructions, this function will be called with the runContext and the agent instance.
#### Parameters
[Section titled “Parameters”](#parameters-9)
| Parameter | Type |
| ------------ | ------------------------------------------------------------------------------------ |
| `runContext` | [`RunContext`](/openai-agents-js/openai/agents-core/classes/runcontext/)<`TContext`> |
#### Returns
[Section titled “Returns”](#returns-10)
`Promise`<`string` | `undefined`>
***
### hasExplicitToolConfig()
[Section titled “hasExplicitToolConfig()”](#hasexplicittoolconfig)
```ts
hasExplicitToolConfig(): boolean;
```
#### Returns
[Section titled “Returns”](#returns-11)
`boolean`
***
### off()
[Section titled “off()”](#off)
```ts
off(type, listener): EventEmitter>;
```
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-4)
| Type Parameter |
| ------------------------------------------------------------ |
| `K` *extends* keyof `AgentHookEvents`<`TContext`, `TOutput`> |
#### Parameters
[Section titled “Parameters”](#parameters-10)
| Parameter | Type |
| ---------- | ------------------- |
| `type` | `K` |
| `listener` | (…`args`) => `void` |
#### Returns
[Section titled “Returns”](#returns-12)
`EventEmitter`<`AgentHookEvents`<`TContext`, `TOutput`>>
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`AgentHooks`](/openai-agents-js/openai/agents-core/classes/agenthooks/).[`off`](/openai-agents-js/openai/agents-core/classes/agenthooks/#off)
***
### on()
[Section titled “on()”](#on)
```ts
on(type, listener): EventEmitter>;
```
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-5)
| Type Parameter |
| ------------------------------------------------------------ |
| `K` *extends* keyof `AgentHookEvents`<`TContext`, `TOutput`> |
#### Parameters
[Section titled “Parameters”](#parameters-11)
| Parameter | Type |
| ---------- | ------------------- |
| `type` | `K` |
| `listener` | (…`args`) => `void` |
#### Returns
[Section titled “Returns”](#returns-13)
`EventEmitter`<`AgentHookEvents`<`TContext`, `TOutput`>>
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`AgentHooks`](/openai-agents-js/openai/agents-core/classes/agenthooks/).[`on`](/openai-agents-js/openai/agents-core/classes/agenthooks/#on)
***
### once()
[Section titled “once()”](#once)
```ts
once(type, listener): EventEmitter>;
```
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-6)
| Type Parameter |
| ------------------------------------------------------------ |
| `K` *extends* keyof `AgentHookEvents`<`TContext`, `TOutput`> |
#### Parameters
[Section titled “Parameters”](#parameters-12)
| Parameter | Type |
| ---------- | ------------------- |
| `type` | `K` |
| `listener` | (…`args`) => `void` |
#### Returns
[Section titled “Returns”](#returns-14)
`EventEmitter`<`AgentHookEvents`<`TContext`, `TOutput`>>
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`AgentHooks`](/openai-agents-js/openai/agents-core/classes/agenthooks/).[`once`](/openai-agents-js/openai/agents-core/classes/agenthooks/#once)
***
### processFinalOutput()
[Section titled “processFinalOutput()”](#processfinaloutput)
```ts
processFinalOutput(output): ResolvedAgentOutput;
```
Processes the final output of the agent.
#### Parameters
[Section titled “Parameters”](#parameters-13)
| Parameter | Type | Description |
| --------- | -------- | ------------------------ |
| `output` | `string` | The output of the agent. |
#### Returns
[Section titled “Returns”](#returns-15)
`ResolvedAgentOutput`<`TOutput`>
The parsed out.
***
### toJSON()
[Section titled “toJSON()”](#tojson)
```ts
toJSON(): object;
```
Returns a JSON representation of the agent, which is serializable.
#### Returns
[Section titled “Returns”](#returns-16)
`object`
A JSON object containing the agent’s name.
##### name
[Section titled “name”](#name-1)
```ts
name: string;
```
***
### create()
[Section titled “create()”](#create)
```ts
static create(config): Agent>;
```
Create an Agent with handoffs and automatically infer the union type for TOutput from the handoff agents’ output types.
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-7)
| Type Parameter | Default type |
| ------------------------------------------------------------------------------------------------------------------------------------------------ | ------------ |
| `TOutput` *extends* [`AgentOutputType`](/openai-agents-js/openai/agents-core/type-aliases/agentoutputtype/)<`unknown`> | `"text"` |
| `Handoffs` *extends* readonly ( \| `Agent`<`any`, `any`> \| [`Handoff`](/openai-agents-js/openai/agents-core/classes/handoff/)<`any`, `any`>)\[] | \[] |
#### Parameters
[Section titled “Parameters”](#parameters-14)
| Parameter | Type |
| --------- | ------------------------------------------------------------------------------------------------------------------------------ |
| `config` | [`AgentConfigWithHandoffs`](/openai-agents-js/openai/agents-core/type-aliases/agentconfigwithhandoffs/)<`TOutput`, `Handoffs`> |
#### Returns
[Section titled “Returns”](#returns-17)
`Agent`<`unknown`, `TOutput` | `HandoffsOutputUnion`<`Handoffs`>>
# AgentHooks
Event emitter that every Agent instance inherits from and that emits events for the lifecycle of the agent.
## Extends
[Section titled “Extends”](#extends)
* `EventEmitterDelegate`<`AgentHookEvents`<`TContext`, `TOutput`>>
## Extended by
[Section titled “Extended by”](#extended-by)
* [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)
## Type Parameters
[Section titled “Type Parameters”](#type-parameters)
| Type Parameter | Default type |
| ----------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| `TContext` | [`UnknownContext`](/openai-agents-js/openai/agents-core/type-aliases/unknowncontext/) |
| `TOutput` *extends* [`AgentOutputType`](/openai-agents-js/openai/agents-core/type-aliases/agentoutputtype/) | [`TextOutput`](/openai-agents-js/openai/agents-core/type-aliases/textoutput/) |
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new AgentHooks(): AgentHooks;
```
#### Returns
[Section titled “Returns”](#returns)
`AgentHooks`<`TContext`, `TOutput`>
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
```ts
EventEmitterDelegate>.constructor
```
## Methods
[Section titled “Methods”](#methods)
### emit()
[Section titled “emit()”](#emit)
```ts
emit(type, ...args): boolean;
```
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-1)
| Type Parameter |
| ------------------------------------------------------------ |
| `K` *extends* keyof `AgentHookEvents`<`TContext`, `TOutput`> |
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | ---------------------------------------------- |
| `type` | `K` |
| …`args` | `AgentHookEvents`<`TContext`, `TOutput`>\[`K`] |
#### Returns
[Section titled “Returns”](#returns-1)
`boolean`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
```ts
EventEmitterDelegate.emit
```
***
### off()
[Section titled “off()”](#off)
```ts
off(type, listener): EventEmitter>;
```
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-2)
| Type Parameter |
| ------------------------------------------------------------ |
| `K` *extends* keyof `AgentHookEvents`<`TContext`, `TOutput`> |
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ---------- | ------------------- |
| `type` | `K` |
| `listener` | (…`args`) => `void` |
#### Returns
[Section titled “Returns”](#returns-2)
`EventEmitter`<`AgentHookEvents`<`TContext`, `TOutput`>>
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
```ts
EventEmitterDelegate.off
```
***
### on()
[Section titled “on()”](#on)
```ts
on(type, listener): EventEmitter>;
```
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-3)
| Type Parameter |
| ------------------------------------------------------------ |
| `K` *extends* keyof `AgentHookEvents`<`TContext`, `TOutput`> |
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| ---------- | ------------------- |
| `type` | `K` |
| `listener` | (…`args`) => `void` |
#### Returns
[Section titled “Returns”](#returns-3)
`EventEmitter`<`AgentHookEvents`<`TContext`, `TOutput`>>
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
```ts
EventEmitterDelegate.on
```
***
### once()
[Section titled “once()”](#once)
```ts
once(type, listener): EventEmitter>;
```
#### Type Parameters
[Section titled “Type Parameters”](#type-parameters-4)
| Type Parameter |
| ------------------------------------------------------------ |
| `K` *extends* keyof `AgentHookEvents`<`TContext`, `TOutput`> |
#### Parameters
[Section titled “Parameters”](#parameters-3)
| Parameter | Type |
| ---------- | ------------------- |
| `type` | `K` |
| `listener` | (…`args`) => `void` |
#### Returns
[Section titled “Returns”](#returns-4)
`EventEmitter`<`AgentHookEvents`<`TContext`, `TOutput`>>
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
```ts
EventEmitterDelegate.once
```
# AgentsError
Base class for all errors thrown by the library.
## Extends
[Section titled “Extends”](#extends)
* `Error`
## Extended by
[Section titled “Extended by”](#extended-by)
* [`GuardrailExecutionError`](/openai-agents-js/openai/agents-core/classes/guardrailexecutionerror/)
* [`InputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents-core/classes/inputguardrailtripwiretriggered/)
* [`MaxTurnsExceededError`](/openai-agents-js/openai/agents-core/classes/maxturnsexceedederror/)
* [`ModelBehaviorError`](/openai-agents-js/openai/agents-core/classes/modelbehaviorerror/)
* [`ModelRefusalError`](/openai-agents-js/openai/agents-core/classes/modelrefusalerror/)
* [`OutputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents-core/classes/outputguardrailtripwiretriggered/)
* [`ToolInputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents-core/classes/toolinputguardrailtripwiretriggered/)
* [`ToolOutputGuardrailTripwireTriggered`](/openai-agents-js/openai/agents-core/classes/tooloutputguardrailtripwiretriggered/)
* [`ToolCallError`](/openai-agents-js/openai/agents-core/classes/toolcallerror/)
* [`ToolTimeoutError`](/openai-agents-js/openai/agents-core/classes/tooltimeouterror/)
* [`UserError`](/openai-agents-js/openai/agents-core/classes/usererror/)
* [`SystemError`](/openai-agents-js/openai/agents-core/classes/systemerror/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new AgentsError(message, state?): AgentsError;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `message` | `string` |
| `state?` | [`RunState`](/openai-agents-js/openai/agents-core/classes/runstate/)<`any`, [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`any`, `any`>> |
#### Returns
[Section titled “Returns”](#returns)
`AgentsError`
#### Overrides
[Section titled “Overrides”](#overrides)
```ts
Error.constructor
```
## Properties
[Section titled “Properties”](#properties)
### message
[Section titled “message”](#message)
```ts
message: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
```ts
Error.message
```
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
```ts
Error.name
```
***
### stack?
[Section titled “stack?”](#stack)
```ts
optional stack?: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
```ts
Error.stack
```
***
### state?
[Section titled “state?”](#state)
```ts
optional state?: RunState>;
```
***
### stackTraceLimit
[Section titled “stackTraceLimit”](#stacktracelimit)
```ts
static stackTraceLimit: number;
```
The `Error.stackTraceLimit` property specifies the number of stack frames collected by a stack trace (whether generated by `new Error().stack` or `Error.captureStackTrace(obj)`).
The default value is `10` but may be set to any valid JavaScript number. Changes will affect any stack trace captured *after* the value has been changed.
If set to a non-number value, or set to a negative number, stack traces will not capture any frames.
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
```ts
Error.stackTraceLimit
```
## Methods
[Section titled “Methods”](#methods)
### captureStackTrace()
[Section titled “captureStackTrace()”](#capturestacktrace)
```ts
static captureStackTrace(targetObject, constructorOpt?): void;
```
Creates a `.stack` property on `targetObject`, which when accessed returns a string representing the location in the code at which `Error.captureStackTrace()` was called.
```js
const myObject = {};
Error.captureStackTrace(myObject);
myObject.stack; // Similar to `new Error().stack`
```
The first line of the trace will be prefixed with `${myObject.name}: ${myObject.message}`.
The optional `constructorOpt` argument accepts a function. If given, all frames above `constructorOpt`, including `constructorOpt`, will be omitted from the generated stack trace.
The `constructorOpt` argument is useful for hiding implementation details of error generation from the user. For instance:
```js
function a() {
b();
}
function b() {
c();
}
function c() {
// Create an error without stack trace to avoid calculating the stack trace twice.
const { stackTraceLimit } = Error;
Error.stackTraceLimit = 0;
const error = new Error();
Error.stackTraceLimit = stackTraceLimit;
// Capture the stack trace above function b
Error.captureStackTrace(error, b); // Neither function c, nor b is included in the stack trace
throw error;
}
a();
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ----------------- | ---------- |
| `targetObject` | `object` |
| `constructorOpt?` | `Function` |
#### Returns
[Section titled “Returns”](#returns-1)
`void`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
```ts
Error.captureStackTrace
```
***
### prepareStackTrace()
[Section titled “prepareStackTrace()”](#preparestacktrace)
```ts
static prepareStackTrace(err, stackTraces): any;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| ------------- | ------------- |
| `err` | `Error` |
| `stackTraces` | `CallSite`\[] |
#### Returns
[Section titled “Returns”](#returns-2)
`any`
#### See
[Section titled “See”](#see)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
```ts
Error.prepareStackTrace
```
# BatchTraceProcessor
Interface for processing traces
## Implements
[Section titled “Implements”](#implements)
* [`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new BatchTraceProcessor(exporter, __namedParameters?): BatchTraceProcessor;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| ------------------- | ------------------------------------------------------------------------------------- |
| `exporter` | [`TracingExporter`](/openai-agents-js/openai/agents-core/interfaces/tracingexporter/) |
| `__namedParameters` | `BatchTraceProcessorOptions` |
#### Returns
[Section titled “Returns”](#returns)
`BatchTraceProcessor`
## Methods
[Section titled “Methods”](#methods)
### forceFlush()
[Section titled “forceFlush()”](#forceflush)
```ts
forceFlush(): Promise;
```
Called when a trace is being flushed
#### Returns
[Section titled “Returns”](#returns-1)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of)
[`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/).[`forceFlush`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/#forceflush)
***
### onSpanEnd()
[Section titled “onSpanEnd()”](#onspanend)
```ts
onSpanEnd(span): Promise;
```
Called when a span is ended
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| --------- | ------ |
| `span` | `Span` |
#### Returns
[Section titled “Returns”](#returns-2)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-1)
[`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/).[`onSpanEnd`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/#onspanend)
***
### onSpanStart()
[Section titled “onSpanStart()”](#onspanstart)
```ts
onSpanStart(_span): Promise;
```
Called when a span is started
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| --------- | ------ |
| `_span` | `Span` |
#### Returns
[Section titled “Returns”](#returns-3)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-2)
[`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/).[`onSpanStart`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/#onspanstart)
***
### onTraceEnd()
[Section titled “onTraceEnd()”](#ontraceend)
```ts
onTraceEnd(_trace): Promise;
```
Called when a trace is ended
#### Parameters
[Section titled “Parameters”](#parameters-3)
| Parameter | Type |
| --------- | -------------------------------------------------------------- |
| `_trace` | [`Trace`](/openai-agents-js/openai/agents-core/classes/trace/) |
#### Returns
[Section titled “Returns”](#returns-4)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-3)
[`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/).[`onTraceEnd`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/#ontraceend)
***
### onTraceStart()
[Section titled “onTraceStart()”](#ontracestart)
```ts
onTraceStart(trace): Promise;
```
Called when a trace is started
#### Parameters
[Section titled “Parameters”](#parameters-4)
| Parameter | Type |
| --------- | -------------------------------------------------------------- |
| `trace` | [`Trace`](/openai-agents-js/openai/agents-core/classes/trace/) |
#### Returns
[Section titled “Returns”](#returns-5)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-4)
[`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/).[`onTraceStart`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/#ontracestart)
***
### shutdown()
[Section titled “shutdown()”](#shutdown)
```ts
shutdown(timeout?): Promise;
```
Called when the trace processor is shutting down
#### Parameters
[Section titled “Parameters”](#parameters-5)
| Parameter | Type |
| ---------- | -------- |
| `timeout?` | `number` |
#### Returns
[Section titled “Returns”](#returns-6)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-5)
[`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/).[`shutdown`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/#shutdown)
***
### start()
[Section titled “start()”](#start)
```ts
start(): void;
```
Called when the trace processor should start processing traces. Only available if the processor is performing tasks like exporting traces in a loop to start the loop
#### Returns
[Section titled “Returns”](#returns-7)
`void`
#### Implementation of
[Section titled “Implementation of”](#implementation-of-6)
[`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/).[`start`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/#start)
# ConsoleSpanExporter
Prints the traces and spans to the console
## Implements
[Section titled “Implements”](#implements)
* [`TracingExporter`](/openai-agents-js/openai/agents-core/interfaces/tracingexporter/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new ConsoleSpanExporter(): ConsoleSpanExporter;
```
#### Returns
[Section titled “Returns”](#returns)
`ConsoleSpanExporter`
## Methods
[Section titled “Methods”](#methods)
### export()
[Section titled “export()”](#export)
```ts
export(items): Promise;
```
Export the given traces and spans
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type | Description |
| --------- | ----------------------------------------------------------------------------- | ------------------------------ |
| `items` | (`Span` \| [`Trace`](/openai-agents-js/openai/agents-core/classes/trace/))\[] | The traces and spans to export |
#### Returns
[Section titled “Returns”](#returns-1)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of)
[`TracingExporter`](/openai-agents-js/openai/agents-core/interfaces/tracingexporter/).[`export`](/openai-agents-js/openai/agents-core/interfaces/tracingexporter/#export)
# GuardrailExecutionError
Error thrown when a guardrail execution fails.
## Extends
[Section titled “Extends”](#extends)
* [`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new GuardrailExecutionError(
message,
error,
state?): GuardrailExecutionError;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `message` | `string` |
| `error` | `Error` |
| `state?` | [`RunState`](/openai-agents-js/openai/agents-core/classes/runstate/)<`any`, [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`any`, `any`>> |
#### Returns
[Section titled “Returns”](#returns)
`GuardrailExecutionError`
#### Overrides
[Section titled “Overrides”](#overrides)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`constructor`](/openai-agents-js/openai/agents-core/classes/agentserror/#constructor)
## Properties
[Section titled “Properties”](#properties)
### error
[Section titled “error”](#error)
```ts
error: Error;
```
***
### message
[Section titled “message”](#message)
```ts
message: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`message`](/openai-agents-js/openai/agents-core/classes/agentserror/#message)
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`name`](/openai-agents-js/openai/agents-core/classes/agentserror/#name)
***
### stack?
[Section titled “stack?”](#stack)
```ts
optional stack?: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stack`](/openai-agents-js/openai/agents-core/classes/agentserror/#stack)
***
### state?
[Section titled “state?”](#state)
```ts
optional state?: RunState>;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`state`](/openai-agents-js/openai/agents-core/classes/agentserror/#state)
***
### stackTraceLimit
[Section titled “stackTraceLimit”](#stacktracelimit)
```ts
static stackTraceLimit: number;
```
The `Error.stackTraceLimit` property specifies the number of stack frames collected by a stack trace (whether generated by `new Error().stack` or `Error.captureStackTrace(obj)`).
The default value is `10` but may be set to any valid JavaScript number. Changes will affect any stack trace captured *after* the value has been changed.
If set to a non-number value, or set to a negative number, stack traces will not capture any frames.
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stackTraceLimit`](/openai-agents-js/openai/agents-core/classes/agentserror/#stacktracelimit)
## Methods
[Section titled “Methods”](#methods)
### captureStackTrace()
[Section titled “captureStackTrace()”](#capturestacktrace)
```ts
static captureStackTrace(targetObject, constructorOpt?): void;
```
Creates a `.stack` property on `targetObject`, which when accessed returns a string representing the location in the code at which `Error.captureStackTrace()` was called.
```js
const myObject = {};
Error.captureStackTrace(myObject);
myObject.stack; // Similar to `new Error().stack`
```
The first line of the trace will be prefixed with `${myObject.name}: ${myObject.message}`.
The optional `constructorOpt` argument accepts a function. If given, all frames above `constructorOpt`, including `constructorOpt`, will be omitted from the generated stack trace.
The `constructorOpt` argument is useful for hiding implementation details of error generation from the user. For instance:
```js
function a() {
b();
}
function b() {
c();
}
function c() {
// Create an error without stack trace to avoid calculating the stack trace twice.
const { stackTraceLimit } = Error;
Error.stackTraceLimit = 0;
const error = new Error();
Error.stackTraceLimit = stackTraceLimit;
// Capture the stack trace above function b
Error.captureStackTrace(error, b); // Neither function c, nor b is included in the stack trace
throw error;
}
a();
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ----------------- | ---------- |
| `targetObject` | `object` |
| `constructorOpt?` | `Function` |
#### Returns
[Section titled “Returns”](#returns-1)
`void`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`captureStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#capturestacktrace)
***
### prepareStackTrace()
[Section titled “prepareStackTrace()”](#preparestacktrace)
```ts
static prepareStackTrace(err, stackTraces): any;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| ------------- | ------------- |
| `err` | `Error` |
| `stackTraces` | `CallSite`\[] |
#### Returns
[Section titled “Returns”](#returns-2)
`any`
#### See
[Section titled “See”](#see)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-6)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`prepareStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#preparestacktrace)
# Handoff
## Type Parameters
[Section titled “Type Parameters”](#type-parameters)
| Type Parameter | Default type |
| ----------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| `TContext` | [`UnknownContext`](/openai-agents-js/openai/agents-core/type-aliases/unknowncontext/) |
| `TOutput` *extends* [`AgentOutputType`](/openai-agents-js/openai/agents-core/type-aliases/agentoutputtype/) | [`TextOutput`](/openai-agents-js/openai/agents-core/type-aliases/textoutput/) |
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new Handoff(agent, onInvokeHandoff): Handoff;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `agent` | [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`TContext`, `TOutput`> |
| `onInvokeHandoff` | (`context`, `args`) => \| [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`TContext`, `TOutput`> \| `Promise`<[`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`TContext`, `TOutput`>> |
#### Returns
[Section titled “Returns”](#returns)
`Handoff`<`TContext`, `TOutput`>
## Properties
[Section titled “Properties”](#properties)
### agent
[Section titled “agent”](#agent)
```ts
agent: Agent;
```
The agent that is being handed off to.
***
### agentName
[Section titled “agentName”](#agentname)
```ts
agentName: string;
```
The name of the agent that is being handed off to.
***
### inputFilter?
[Section titled “inputFilter?”](#inputfilter)
```ts
optional inputFilter?: HandoffInputFilter;
```
A function that filters the inputs that are passed to the next agent. By default, the new agent sees the entire conversation history. In some cases, you may want to filter inputs e.g. to remove older inputs, or remove tools from existing inputs.
The function will receive the entire conversation hisstory so far, including the input item that triggered the handoff and a tool call output item representing the handoff tool’s output.
You are free to modify the input history or new items as you see fit. The next agent that runs will receive \`handoffInputData.allItems
***
### inputJsonSchema
[Section titled “inputJsonSchema”](#inputjsonschema)
```ts
inputJsonSchema: JsonObjectSchema;
```
The JSON schema for the handoff input. Can be empty if the handoff does not take an input
***
### isEnabled
[Section titled “isEnabled”](#isenabled)
```ts
isEnabled: HandoffEnabledFunction;
```
***
### onInvokeHandoff
[Section titled “onInvokeHandoff”](#oninvokehandoff)
```ts
onInvokeHandoff: (context, args) =>
| Agent
| Promise>;
```
The function that invokes the handoff. The parameters passed are:
1. The handoff run context
2. The arguments from the LLM, as a JSON string. Empty string if inputJsonSchema is empty.
Must return an agent
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| --------- | ------------------------------------------------------------------------------------ |
| `context` | [`RunContext`](/openai-agents-js/openai/agents-core/classes/runcontext/)<`TContext`> |
| `args` | `string` |
#### Returns
[Section titled “Returns”](#returns-1)
\| [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`TContext`, `TOutput`> | `Promise`<[`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`TContext`, `TOutput`>>
***
### strictJsonSchema
[Section titled “strictJsonSchema”](#strictjsonschema)
```ts
strictJsonSchema: boolean = true;
```
Whether the input JSON schema is in strict mode. We **strongly** recommend setting this to true, as it increases the likelihood of correct JSON input.
***
### toolDescription
[Section titled “toolDescription”](#tooldescription)
```ts
toolDescription: string;
```
The description of the tool that represents the handoff.
***
### toolName
[Section titled “toolName”](#toolname)
```ts
toolName: string;
```
The name of the tool that represents the handoff.
## Methods
[Section titled “Methods”](#methods)
### getHandoffAsFunctionTool()
[Section titled “getHandoffAsFunctionTool()”](#gethandoffasfunctiontool)
```ts
getHandoffAsFunctionTool(): object;
```
Returns a function tool definition that can be used to invoke the handoff.
#### Returns
[Section titled “Returns”](#returns-2)
`object`
##### description
[Section titled “description”](#description)
```ts
description: string;
```
##### name
[Section titled “name”](#name)
```ts
name: string;
```
##### parameters
[Section titled “parameters”](#parameters-2)
```ts
parameters: JsonObjectSchema;
```
##### strict
[Section titled “strict”](#strict)
```ts
strict: boolean;
```
##### type
[Section titled “type”](#type)
```ts
type: "function";
```
# InputGuardrailTripwireTriggered
Error thrown when an input guardrail tripwire is triggered.
## Extends
[Section titled “Extends”](#extends)
* [`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new InputGuardrailTripwireTriggered(
message,
result,
state?): InputGuardrailTripwireTriggered;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | ----------------------------------------------------------------------------------------------- |
| `message` | `string` |
| `result` | [`InputGuardrailResult`](/openai-agents-js/openai/agents-core/interfaces/inputguardrailresult/) |
| `state?` | [`RunState`](/openai-agents-js/openai/agents-core/classes/runstate/)<`any`, `any`> |
#### Returns
[Section titled “Returns”](#returns)
`InputGuardrailTripwireTriggered`
#### Overrides
[Section titled “Overrides”](#overrides)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`constructor`](/openai-agents-js/openai/agents-core/classes/agentserror/#constructor)
## Properties
[Section titled “Properties”](#properties)
### message
[Section titled “message”](#message)
```ts
message: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`message`](/openai-agents-js/openai/agents-core/classes/agentserror/#message)
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`name`](/openai-agents-js/openai/agents-core/classes/agentserror/#name)
***
### result
[Section titled “result”](#result)
```ts
result: InputGuardrailResult;
```
***
### stack?
[Section titled “stack?”](#stack)
```ts
optional stack?: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stack`](/openai-agents-js/openai/agents-core/classes/agentserror/#stack)
***
### state?
[Section titled “state?”](#state)
```ts
optional state?: RunState>;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`state`](/openai-agents-js/openai/agents-core/classes/agentserror/#state)
***
### stackTraceLimit
[Section titled “stackTraceLimit”](#stacktracelimit)
```ts
static stackTraceLimit: number;
```
The `Error.stackTraceLimit` property specifies the number of stack frames collected by a stack trace (whether generated by `new Error().stack` or `Error.captureStackTrace(obj)`).
The default value is `10` but may be set to any valid JavaScript number. Changes will affect any stack trace captured *after* the value has been changed.
If set to a non-number value, or set to a negative number, stack traces will not capture any frames.
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stackTraceLimit`](/openai-agents-js/openai/agents-core/classes/agentserror/#stacktracelimit)
## Methods
[Section titled “Methods”](#methods)
### captureStackTrace()
[Section titled “captureStackTrace()”](#capturestacktrace)
```ts
static captureStackTrace(targetObject, constructorOpt?): void;
```
Creates a `.stack` property on `targetObject`, which when accessed returns a string representing the location in the code at which `Error.captureStackTrace()` was called.
```js
const myObject = {};
Error.captureStackTrace(myObject);
myObject.stack; // Similar to `new Error().stack`
```
The first line of the trace will be prefixed with `${myObject.name}: ${myObject.message}`.
The optional `constructorOpt` argument accepts a function. If given, all frames above `constructorOpt`, including `constructorOpt`, will be omitted from the generated stack trace.
The `constructorOpt` argument is useful for hiding implementation details of error generation from the user. For instance:
```js
function a() {
b();
}
function b() {
c();
}
function c() {
// Create an error without stack trace to avoid calculating the stack trace twice.
const { stackTraceLimit } = Error;
Error.stackTraceLimit = 0;
const error = new Error();
Error.stackTraceLimit = stackTraceLimit;
// Capture the stack trace above function b
Error.captureStackTrace(error, b); // Neither function c, nor b is included in the stack trace
throw error;
}
a();
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ----------------- | ---------- |
| `targetObject` | `object` |
| `constructorOpt?` | `Function` |
#### Returns
[Section titled “Returns”](#returns-1)
`void`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`captureStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#capturestacktrace)
***
### prepareStackTrace()
[Section titled “prepareStackTrace()”](#preparestacktrace)
```ts
static prepareStackTrace(err, stackTraces): any;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| ------------- | ------------- |
| `err` | `Error` |
| `stackTraces` | `CallSite`\[] |
#### Returns
[Section titled “Returns”](#returns-2)
`any`
#### See
[Section titled “See”](#see)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-6)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`prepareStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#preparestacktrace)
# MaxTurnsExceededError
Error thrown when the maximum number of turns is exceeded.
## Extends
[Section titled “Extends”](#extends)
* [`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new MaxTurnsExceededError(message, state?): MaxTurnsExceededError;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `message` | `string` |
| `state?` | [`RunState`](/openai-agents-js/openai/agents-core/classes/runstate/)<`any`, [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`any`, `any`>> |
#### Returns
[Section titled “Returns”](#returns)
`MaxTurnsExceededError`
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`constructor`](/openai-agents-js/openai/agents-core/classes/agentserror/#constructor)
## Properties
[Section titled “Properties”](#properties)
### message
[Section titled “message”](#message)
```ts
message: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`message`](/openai-agents-js/openai/agents-core/classes/agentserror/#message)
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`name`](/openai-agents-js/openai/agents-core/classes/agentserror/#name)
***
### stack?
[Section titled “stack?”](#stack)
```ts
optional stack?: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stack`](/openai-agents-js/openai/agents-core/classes/agentserror/#stack)
***
### state?
[Section titled “state?”](#state)
```ts
optional state?: RunState>;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`state`](/openai-agents-js/openai/agents-core/classes/agentserror/#state)
***
### stackTraceLimit
[Section titled “stackTraceLimit”](#stacktracelimit)
```ts
static stackTraceLimit: number;
```
The `Error.stackTraceLimit` property specifies the number of stack frames collected by a stack trace (whether generated by `new Error().stack` or `Error.captureStackTrace(obj)`).
The default value is `10` but may be set to any valid JavaScript number. Changes will affect any stack trace captured *after* the value has been changed.
If set to a non-number value, or set to a negative number, stack traces will not capture any frames.
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stackTraceLimit`](/openai-agents-js/openai/agents-core/classes/agentserror/#stacktracelimit)
## Methods
[Section titled “Methods”](#methods)
### captureStackTrace()
[Section titled “captureStackTrace()”](#capturestacktrace)
```ts
static captureStackTrace(targetObject, constructorOpt?): void;
```
Creates a `.stack` property on `targetObject`, which when accessed returns a string representing the location in the code at which `Error.captureStackTrace()` was called.
```js
const myObject = {};
Error.captureStackTrace(myObject);
myObject.stack; // Similar to `new Error().stack`
```
The first line of the trace will be prefixed with `${myObject.name}: ${myObject.message}`.
The optional `constructorOpt` argument accepts a function. If given, all frames above `constructorOpt`, including `constructorOpt`, will be omitted from the generated stack trace.
The `constructorOpt` argument is useful for hiding implementation details of error generation from the user. For instance:
```js
function a() {
b();
}
function b() {
c();
}
function c() {
// Create an error without stack trace to avoid calculating the stack trace twice.
const { stackTraceLimit } = Error;
Error.stackTraceLimit = 0;
const error = new Error();
Error.stackTraceLimit = stackTraceLimit;
// Capture the stack trace above function b
Error.captureStackTrace(error, b); // Neither function c, nor b is included in the stack trace
throw error;
}
a();
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ----------------- | ---------- |
| `targetObject` | `object` |
| `constructorOpt?` | `Function` |
#### Returns
[Section titled “Returns”](#returns-1)
`void`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-6)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`captureStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#capturestacktrace)
***
### prepareStackTrace()
[Section titled “prepareStackTrace()”](#preparestacktrace)
```ts
static prepareStackTrace(err, stackTraces): any;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| ------------- | ------------- |
| `err` | `Error` |
| `stackTraces` | `CallSite`\[] |
#### Returns
[Section titled “Returns”](#returns-2)
`any`
#### See
[Section titled “See”](#see)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-7)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`prepareStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#preparestacktrace)
# MCPServers
Manages MCP server lifecycle and exposes only connected servers.
## Properties
[Section titled “Properties”](#properties)
### \[asyncDispose]
[Section titled “\[asyncDispose\]”](#asyncdispose)
```ts
[asyncDispose]: () => Promise;
```
#### Returns
[Section titled “Returns”](#returns)
`Promise`<`void`>
## Accessors
[Section titled “Accessors”](#accessors)
### active
[Section titled “active”](#active)
#### Get Signature
[Section titled “Get Signature”](#get-signature)
```ts
get active(): MCPServer[];
```
##### Returns
[Section titled “Returns”](#returns-1)
[`MCPServer`](/openai-agents-js/openai/agents-core/interfaces/mcpserver/)\[]
***
### all
[Section titled “all”](#all)
#### Get Signature
[Section titled “Get Signature”](#get-signature-1)
```ts
get all(): MCPServer[];
```
##### Returns
[Section titled “Returns”](#returns-2)
[`MCPServer`](/openai-agents-js/openai/agents-core/interfaces/mcpserver/)\[]
***
### errors
[Section titled “errors”](#errors)
#### Get Signature
[Section titled “Get Signature”](#get-signature-2)
```ts
get errors(): ReadonlyMap;
```
##### Returns
[Section titled “Returns”](#returns-3)
`ReadonlyMap`<[`MCPServer`](/openai-agents-js/openai/agents-core/interfaces/mcpserver/), `Error`>
***
### failed
[Section titled “failed”](#failed)
#### Get Signature
[Section titled “Get Signature”](#get-signature-3)
```ts
get failed(): MCPServer[];
```
##### Returns
[Section titled “Returns”](#returns-4)
[`MCPServer`](/openai-agents-js/openai/agents-core/interfaces/mcpserver/)\[]
## Methods
[Section titled “Methods”](#methods)
### close()
[Section titled “close()”](#close)
```ts
close(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-5)
`Promise`<`void`>
***
### reconnect()
[Section titled “reconnect()”](#reconnect)
```ts
reconnect(options?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | ------------------------------------------------------------------------------------------------------------- |
| `options` | [`MCPServersReconnectOptions`](/openai-agents-js/openai/agents-core/type-aliases/mcpserversreconnectoptions/) |
#### Returns
[Section titled “Returns”](#returns-6)
`Promise`<[`MCPServer`](/openai-agents-js/openai/agents-core/interfaces/mcpserver/)\[]>
***
### open()
[Section titled “open()”](#open)
```ts
static open(servers, options?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ---------- | ------------------------------------------------------------------------------------------- |
| `servers` | [`MCPServer`](/openai-agents-js/openai/agents-core/interfaces/mcpserver/)\[] |
| `options?` | [`MCPServersOptions`](/openai-agents-js/openai/agents-core/type-aliases/mcpserversoptions/) |
#### Returns
[Section titled “Returns”](#returns-7)
`Promise`<`MCPServers`>
# MCPServerSSE
Extended MCP server surface for servers that expose resources.
## Extends
[Section titled “Extends”](#extends)
* `BaseMCPServerSSE`
## Implements
[Section titled “Implements”](#implements)
* [`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new MCPServerSSE(options): MCPServerSSE;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | --------------------- |
| `options` | `MCPServerSSEOptions` |
#### Returns
[Section titled “Returns”](#returns)
`MCPServerSSE`
#### Overrides
[Section titled “Overrides”](#overrides)
```ts
BaseMCPServerSSE.constructor
```
## Properties
[Section titled “Properties”](#properties)
### cacheToolsList
[Section titled “cacheToolsList”](#cachetoolslist)
```ts
cacheToolsList: boolean;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`cacheToolsList`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#cachetoolslist)
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
```ts
BaseMCPServerSSE.cacheToolsList
```
***
### errorFunction?
[Section titled “errorFunction?”](#errorfunction)
```ts
optional errorFunction?:
| MCPToolErrorFunction
| null;
```
Optional function to convert MCP tool failures into model-visible messages. Set to null to rethrow errors instead of converting them.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-1)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`errorFunction`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#errorfunction)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
```ts
BaseMCPServerSSE.errorFunction
```
***
### toolFilter?
[Section titled “toolFilter?”](#toolfilter)
```ts
optional toolFilter?:
| MCPToolFilterStatic
| MCPToolFilterCallable;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of-2)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`toolFilter`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#toolfilter)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
```ts
BaseMCPServerSSE.toolFilter
```
***
### toolMetaResolver?
[Section titled “toolMetaResolver?”](#toolmetaresolver)
```ts
optional toolMetaResolver?: MCPToolMetaResolver;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of-3)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`toolMetaResolver`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#toolmetaresolver)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
```ts
BaseMCPServerSSE.toolMetaResolver
```
## Accessors
[Section titled “Accessors”](#accessors)
### name
[Section titled “name”](#name)
#### Get Signature
[Section titled “Get Signature”](#get-signature)
```ts
get name(): string;
```
##### Returns
[Section titled “Returns”](#returns-1)
`string`
#### Implementation of
[Section titled “Implementation of”](#implementation-of-4)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`name`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#name)
#### Overrides
[Section titled “Overrides”](#overrides-1)
```ts
BaseMCPServerSSE.name
```
## Methods
[Section titled “Methods”](#methods)
### callTool()
[Section titled “callTool()”](#calltool)
```ts
callTool(
toolName,
args,
meta?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ---------- | --------------------------------------- |
| `toolName` | `string` |
| `args` | `Record`<`string`, `unknown`> \| `null` |
| `meta?` | `Record`<`string`, `unknown`> \| `null` |
#### Returns
[Section titled “Returns”](#returns-2)
`Promise`<`object`\[]>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-5)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`callTool`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#calltool)
#### Overrides
[Section titled “Overrides”](#overrides-2)
```ts
BaseMCPServerSSE.callTool
```
***
### close()
[Section titled “close()”](#close)
```ts
close(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-3)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-6)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`close`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#close)
#### Overrides
[Section titled “Overrides”](#overrides-3)
```ts
BaseMCPServerSSE.close
```
***
### connect()
[Section titled “connect()”](#connect)
```ts
connect(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-4)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-7)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`connect`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#connect)
#### Overrides
[Section titled “Overrides”](#overrides-4)
```ts
BaseMCPServerSSE.connect
```
***
### invalidateToolsCache()
[Section titled “invalidateToolsCache()”](#invalidatetoolscache)
```ts
invalidateToolsCache(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-5)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-8)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`invalidateToolsCache`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#invalidatetoolscache)
#### Overrides
[Section titled “Overrides”](#overrides-5)
```ts
BaseMCPServerSSE.invalidateToolsCache
```
***
### listResources()
[Section titled “listResources()”](#listresources)
```ts
listResources(params?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------- |
| `params?` | [`MCPListResourcesParams`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesparams/) |
#### Returns
[Section titled “Returns”](#returns-6)
`Promise`<[`MCPListResourcesResult`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-9)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listresources)
#### Overrides
[Section titled “Overrides”](#overrides-6)
```ts
BaseMCPServerSSE.listResources
```
***
### listResourceTemplates()
[Section titled “listResourceTemplates()”](#listresourcetemplates)
```ts
listResourceTemplates(params?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-3)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------- |
| `params?` | [`MCPListResourcesParams`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesparams/) |
#### Returns
[Section titled “Returns”](#returns-7)
`Promise`<[`MCPListResourceTemplatesResult`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcetemplatesresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-10)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listResourceTemplates`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listresourcetemplates)
#### Overrides
[Section titled “Overrides”](#overrides-7)
```ts
BaseMCPServerSSE.listResourceTemplates
```
***
### listTools()
[Section titled “listTools()”](#listtools)
```ts
listTools(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-8)
`Promise`<`object`\[]>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-11)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listTools`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listtools)
#### Overrides
[Section titled “Overrides”](#overrides-8)
```ts
BaseMCPServerSSE.listTools
```
***
### readResource()
[Section titled “readResource()”](#readresource)
```ts
readResource(uri): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-4)
| Parameter | Type |
| --------- | -------- |
| `uri` | `string` |
#### Returns
[Section titled “Returns”](#returns-9)
`Promise`<[`MCPReadResourceResult`](/openai-agents-js/openai/agents-core/interfaces/mcpreadresourceresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-12)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`readResource`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#readresource)
#### Overrides
[Section titled “Overrides”](#overrides-9)
```ts
BaseMCPServerSSE.readResource
```
# MCPServerStdio
Public interface of an MCP server that provides tools. You can use this class to pass MCP server settings to your agent.
## Extends
[Section titled “Extends”](#extends)
* `BaseMCPServerStdio`
## Implements
[Section titled “Implements”](#implements)
* [`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new MCPServerStdio(options): MCPServerStdio;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | ----------------------- |
| `options` | `MCPServerStdioOptions` |
#### Returns
[Section titled “Returns”](#returns)
`MCPServerStdio`
#### Overrides
[Section titled “Overrides”](#overrides)
```ts
BaseMCPServerStdio.constructor
```
## Properties
[Section titled “Properties”](#properties)
### cacheToolsList
[Section titled “cacheToolsList”](#cachetoolslist)
```ts
cacheToolsList: boolean;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`cacheToolsList`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#cachetoolslist)
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
```ts
BaseMCPServerStdio.cacheToolsList
```
***
### errorFunction?
[Section titled “errorFunction?”](#errorfunction)
```ts
optional errorFunction?:
| MCPToolErrorFunction
| null;
```
Optional function to convert MCP tool failures into model-visible messages. Set to null to rethrow errors instead of converting them.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-1)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`errorFunction`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#errorfunction)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
```ts
BaseMCPServerStdio.errorFunction
```
***
### toolFilter?
[Section titled “toolFilter?”](#toolfilter)
```ts
optional toolFilter?:
| MCPToolFilterStatic
| MCPToolFilterCallable;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of-2)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`toolFilter`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#toolfilter)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
```ts
BaseMCPServerStdio.toolFilter
```
***
### toolMetaResolver?
[Section titled “toolMetaResolver?”](#toolmetaresolver)
```ts
optional toolMetaResolver?: MCPToolMetaResolver;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of-3)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`toolMetaResolver`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#toolmetaresolver)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
```ts
BaseMCPServerStdio.toolMetaResolver
```
## Accessors
[Section titled “Accessors”](#accessors)
### name
[Section titled “name”](#name)
#### Get Signature
[Section titled “Get Signature”](#get-signature)
```ts
get name(): string;
```
##### Returns
[Section titled “Returns”](#returns-1)
`string`
#### Implementation of
[Section titled “Implementation of”](#implementation-of-4)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`name`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#name)
#### Overrides
[Section titled “Overrides”](#overrides-1)
```ts
BaseMCPServerStdio.name
```
## Methods
[Section titled “Methods”](#methods)
### callTool()
[Section titled “callTool()”](#calltool)
```ts
callTool(
toolName,
args,
meta?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ---------- | --------------------------------------- |
| `toolName` | `string` |
| `args` | `Record`<`string`, `unknown`> \| `null` |
| `meta?` | `Record`<`string`, `unknown`> \| `null` |
#### Returns
[Section titled “Returns”](#returns-2)
`Promise`<`object`\[]>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-5)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`callTool`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#calltool)
#### Overrides
[Section titled “Overrides”](#overrides-2)
```ts
BaseMCPServerStdio.callTool
```
***
### close()
[Section titled “close()”](#close)
```ts
close(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-3)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-6)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`close`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#close)
#### Overrides
[Section titled “Overrides”](#overrides-3)
```ts
BaseMCPServerStdio.close
```
***
### connect()
[Section titled “connect()”](#connect)
```ts
connect(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-4)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-7)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`connect`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#connect)
#### Overrides
[Section titled “Overrides”](#overrides-4)
```ts
BaseMCPServerStdio.connect
```
***
### invalidateToolsCache()
[Section titled “invalidateToolsCache()”](#invalidatetoolscache)
```ts
invalidateToolsCache(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-5)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-8)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`invalidateToolsCache`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#invalidatetoolscache)
#### Overrides
[Section titled “Overrides”](#overrides-5)
```ts
BaseMCPServerStdio.invalidateToolsCache
```
***
### listResources()
[Section titled “listResources()”](#listresources)
```ts
listResources(params?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------- |
| `params?` | [`MCPListResourcesParams`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesparams/) |
#### Returns
[Section titled “Returns”](#returns-6)
`Promise`<[`MCPListResourcesResult`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-9)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listresources)
#### Overrides
[Section titled “Overrides”](#overrides-6)
```ts
BaseMCPServerStdio.listResources
```
***
### listResourceTemplates()
[Section titled “listResourceTemplates()”](#listresourcetemplates)
```ts
listResourceTemplates(params?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-3)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------- |
| `params?` | [`MCPListResourcesParams`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesparams/) |
#### Returns
[Section titled “Returns”](#returns-7)
`Promise`<[`MCPListResourceTemplatesResult`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcetemplatesresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-10)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listResourceTemplates`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listresourcetemplates)
#### Overrides
[Section titled “Overrides”](#overrides-7)
```ts
BaseMCPServerStdio.listResourceTemplates
```
***
### listTools()
[Section titled “listTools()”](#listtools)
```ts
listTools(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-8)
`Promise`<`object`\[]>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-11)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listTools`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listtools)
#### Overrides
[Section titled “Overrides”](#overrides-8)
```ts
BaseMCPServerStdio.listTools
```
***
### readResource()
[Section titled “readResource()”](#readresource)
```ts
readResource(uri): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-4)
| Parameter | Type |
| --------- | -------- |
| `uri` | `string` |
#### Returns
[Section titled “Returns”](#returns-9)
`Promise`<[`MCPReadResourceResult`](/openai-agents-js/openai/agents-core/interfaces/mcpreadresourceresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-12)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`readResource`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#readresource)
#### Overrides
[Section titled “Overrides”](#overrides-9)
```ts
BaseMCPServerStdio.readResource
```
# MCPServerStreamableHttp
Extended MCP server surface for servers that expose resources.
## Extends
[Section titled “Extends”](#extends)
* `BaseMCPServerStreamableHttp`
## Implements
[Section titled “Implements”](#implements)
* [`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new MCPServerStreamableHttp(options): MCPServerStreamableHttp;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | -------------------------------- |
| `options` | `MCPServerStreamableHttpOptions` |
#### Returns
[Section titled “Returns”](#returns)
`MCPServerStreamableHttp`
#### Overrides
[Section titled “Overrides”](#overrides)
```ts
BaseMCPServerStreamableHttp.constructor
```
## Properties
[Section titled “Properties”](#properties)
### cacheToolsList
[Section titled “cacheToolsList”](#cachetoolslist)
```ts
cacheToolsList: boolean;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`cacheToolsList`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#cachetoolslist)
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
```ts
BaseMCPServerStreamableHttp.cacheToolsList
```
***
### errorFunction?
[Section titled “errorFunction?”](#errorfunction)
```ts
optional errorFunction?:
| MCPToolErrorFunction
| null;
```
Optional function to convert MCP tool failures into model-visible messages. Set to null to rethrow errors instead of converting them.
#### Implementation of
[Section titled “Implementation of”](#implementation-of-1)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`errorFunction`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#errorfunction)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
```ts
BaseMCPServerStreamableHttp.errorFunction
```
***
### toolFilter?
[Section titled “toolFilter?”](#toolfilter)
```ts
optional toolFilter?:
| MCPToolFilterStatic
| MCPToolFilterCallable;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of-2)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`toolFilter`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#toolfilter)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
```ts
BaseMCPServerStreamableHttp.toolFilter
```
***
### toolMetaResolver?
[Section titled “toolMetaResolver?”](#toolmetaresolver)
```ts
optional toolMetaResolver?: MCPToolMetaResolver;
```
#### Implementation of
[Section titled “Implementation of”](#implementation-of-3)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`toolMetaResolver`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#toolmetaresolver)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
```ts
BaseMCPServerStreamableHttp.toolMetaResolver
```
## Accessors
[Section titled “Accessors”](#accessors)
### name
[Section titled “name”](#name)
#### Get Signature
[Section titled “Get Signature”](#get-signature)
```ts
get name(): string;
```
##### Returns
[Section titled “Returns”](#returns-1)
`string`
#### Implementation of
[Section titled “Implementation of”](#implementation-of-4)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`name`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#name)
#### Overrides
[Section titled “Overrides”](#overrides-1)
```ts
BaseMCPServerStreamableHttp.name
```
***
### sessionId
[Section titled “sessionId”](#sessionid)
#### Get Signature
[Section titled “Get Signature”](#get-signature-1)
```ts
get sessionId(): string | undefined;
```
##### Returns
[Section titled “Returns”](#returns-2)
`string` | `undefined`
#### Overrides
[Section titled “Overrides”](#overrides-2)
```ts
BaseMCPServerStreamableHttp.sessionId
```
## Methods
[Section titled “Methods”](#methods)
### callTool()
[Section titled “callTool()”](#calltool)
```ts
callTool(
toolName,
args,
meta?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ---------- | --------------------------------------- |
| `toolName` | `string` |
| `args` | `Record`<`string`, `unknown`> \| `null` |
| `meta?` | `Record`<`string`, `unknown`> \| `null` |
#### Returns
[Section titled “Returns”](#returns-3)
`Promise`<`object`\[]>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-5)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`callTool`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#calltool)
#### Overrides
[Section titled “Overrides”](#overrides-3)
```ts
BaseMCPServerStreamableHttp.callTool
```
***
### close()
[Section titled “close()”](#close)
```ts
close(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-4)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-6)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`close`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#close)
#### Overrides
[Section titled “Overrides”](#overrides-4)
```ts
BaseMCPServerStreamableHttp.close
```
***
### connect()
[Section titled “connect()”](#connect)
```ts
connect(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-5)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-7)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`connect`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#connect)
#### Overrides
[Section titled “Overrides”](#overrides-5)
```ts
BaseMCPServerStreamableHttp.connect
```
***
### invalidateToolsCache()
[Section titled “invalidateToolsCache()”](#invalidatetoolscache)
```ts
invalidateToolsCache(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-6)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-8)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`invalidateToolsCache`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#invalidatetoolscache)
#### Overrides
[Section titled “Overrides”](#overrides-6)
```ts
BaseMCPServerStreamableHttp.invalidateToolsCache
```
***
### listResources()
[Section titled “listResources()”](#listresources)
```ts
listResources(params?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------- |
| `params?` | [`MCPListResourcesParams`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesparams/) |
#### Returns
[Section titled “Returns”](#returns-7)
`Promise`<[`MCPListResourcesResult`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-9)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listresources)
#### Overrides
[Section titled “Overrides”](#overrides-7)
```ts
BaseMCPServerStreamableHttp.listResources
```
***
### listResourceTemplates()
[Section titled “listResourceTemplates()”](#listresourcetemplates)
```ts
listResourceTemplates(params?): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-3)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------- |
| `params?` | [`MCPListResourcesParams`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcesparams/) |
#### Returns
[Section titled “Returns”](#returns-8)
`Promise`<[`MCPListResourceTemplatesResult`](/openai-agents-js/openai/agents-core/interfaces/mcplistresourcetemplatesresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-10)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listResourceTemplates`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listresourcetemplates)
#### Overrides
[Section titled “Overrides”](#overrides-8)
```ts
BaseMCPServerStreamableHttp.listResourceTemplates
```
***
### listTools()
[Section titled “listTools()”](#listtools)
```ts
listTools(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-9)
`Promise`<`object`\[]>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-11)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`listTools`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#listtools)
#### Overrides
[Section titled “Overrides”](#overrides-9)
```ts
BaseMCPServerStreamableHttp.listTools
```
***
### readResource()
[Section titled “readResource()”](#readresource)
```ts
readResource(uri): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-4)
| Parameter | Type |
| --------- | -------- |
| `uri` | `string` |
#### Returns
[Section titled “Returns”](#returns-10)
`Promise`<[`MCPReadResourceResult`](/openai-agents-js/openai/agents-core/interfaces/mcpreadresourceresult/)>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-12)
[`MCPServerWithResources`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/).[`readResource`](/openai-agents-js/openai/agents-core/interfaces/mcpserverwithresources/#readresource)
#### Overrides
[Section titled “Overrides”](#overrides-10)
```ts
BaseMCPServerStreamableHttp.readResource
```
# MemorySession
Simple in-memory session store intended for demos or tests. Not recommended for production use.
## Implements
[Section titled “Implements”](#implements)
* [`SessionHistoryRewriteAwareSession`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new MemorySession(options?): MemorySession;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | ---------------------- |
| `options` | `MemorySessionOptions` |
#### Returns
[Section titled “Returns”](#returns)
`MemorySession`
## Methods
[Section titled “Methods”](#methods)
### addItems()
[Section titled “addItems()”](#additems)
```ts
addItems(items): Promise;
```
Append new items to the conversation history.
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type | Description |
| --------- | ---------------------------------------------------------------------------------------- | ------------------------------------ |
| `items` | [`AgentInputItem`](/openai-agents-js/openai/agents-core/type-aliases/agentinputitem/)\[] | Items to add to the session history. |
#### Returns
[Section titled “Returns”](#returns-1)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of)
[`SessionHistoryRewriteAwareSession`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/).[`addItems`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/#additems)
***
### applyHistoryMutations()
[Section titled “applyHistoryMutations()”](#applyhistorymutations)
```ts
applyHistoryMutations(args): Promise;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| --------- | ----------------------------------------------------------------------------------------------------------- |
| `args` | [`SessionHistoryRewriteArgs`](/openai-agents-js/openai/agents-core/type-aliases/sessionhistoryrewriteargs/) |
#### Returns
[Section titled “Returns”](#returns-2)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-1)
[`SessionHistoryRewriteAwareSession`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/).[`applyHistoryMutations`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/#applyhistorymutations)
***
### clearSession()
[Section titled “clearSession()”](#clearsession)
```ts
clearSession(): Promise;
```
Remove all items that belong to the session and reset its state.
#### Returns
[Section titled “Returns”](#returns-3)
`Promise`<`void`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-2)
[`SessionHistoryRewriteAwareSession`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/).[`clearSession`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/#clearsession)
***
### getItems()
[Section titled “getItems()”](#getitems)
```ts
getItems(limit?): Promise;
```
Retrieve items from the conversation history.
#### Parameters
[Section titled “Parameters”](#parameters-3)
| Parameter | Type | Description |
| --------- | -------- | --------------------------------------------------------------------------------------------------------------------------- |
| `limit?` | `number` | The maximum number of items to return. When provided the most recent limit items should be returned in chronological order. |
#### Returns
[Section titled “Returns”](#returns-4)
`Promise`<[`AgentInputItem`](/openai-agents-js/openai/agents-core/type-aliases/agentinputitem/)\[]>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-3)
[`SessionHistoryRewriteAwareSession`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/).[`getItems`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/#getitems)
***
### getSessionId()
[Section titled “getSessionId()”](#getsessionid)
```ts
getSessionId(): Promise;
```
Ensure and return the identifier for this session.
#### Returns
[Section titled “Returns”](#returns-5)
`Promise`<`string`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-4)
[`SessionHistoryRewriteAwareSession`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/).[`getSessionId`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/#getsessionid)
***
### popItem()
[Section titled “popItem()”](#popitem)
```ts
popItem(): Promise<
| AgentInputItem
| undefined>;
```
Remove and return the most recent item from the conversation history if it exists.
#### Returns
[Section titled “Returns”](#returns-6)
`Promise`< | [`AgentInputItem`](/openai-agents-js/openai/agents-core/type-aliases/agentinputitem/) | `undefined`>
#### Implementation of
[Section titled “Implementation of”](#implementation-of-5)
[`SessionHistoryRewriteAwareSession`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/).[`popItem`](/openai-agents-js/openai/agents-core/interfaces/sessionhistoryrewriteawaresession/#popitem)
# ModelBehaviorError
Error thrown when a model behavior is unexpected.
## Extends
[Section titled “Extends”](#extends)
* [`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new ModelBehaviorError(message, state?): ModelBehaviorError;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `message` | `string` |
| `state?` | [`RunState`](/openai-agents-js/openai/agents-core/classes/runstate/)<`any`, [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`any`, `any`>> |
#### Returns
[Section titled “Returns”](#returns)
`ModelBehaviorError`
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`constructor`](/openai-agents-js/openai/agents-core/classes/agentserror/#constructor)
## Properties
[Section titled “Properties”](#properties)
### message
[Section titled “message”](#message)
```ts
message: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`message`](/openai-agents-js/openai/agents-core/classes/agentserror/#message)
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`name`](/openai-agents-js/openai/agents-core/classes/agentserror/#name)
***
### stack?
[Section titled “stack?”](#stack)
```ts
optional stack?: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stack`](/openai-agents-js/openai/agents-core/classes/agentserror/#stack)
***
### state?
[Section titled “state?”](#state)
```ts
optional state?: RunState>;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`state`](/openai-agents-js/openai/agents-core/classes/agentserror/#state)
***
### stackTraceLimit
[Section titled “stackTraceLimit”](#stacktracelimit)
```ts
static stackTraceLimit: number;
```
The `Error.stackTraceLimit` property specifies the number of stack frames collected by a stack trace (whether generated by `new Error().stack` or `Error.captureStackTrace(obj)`).
The default value is `10` but may be set to any valid JavaScript number. Changes will affect any stack trace captured *after* the value has been changed.
If set to a non-number value, or set to a negative number, stack traces will not capture any frames.
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stackTraceLimit`](/openai-agents-js/openai/agents-core/classes/agentserror/#stacktracelimit)
## Methods
[Section titled “Methods”](#methods)
### captureStackTrace()
[Section titled “captureStackTrace()”](#capturestacktrace)
```ts
static captureStackTrace(targetObject, constructorOpt?): void;
```
Creates a `.stack` property on `targetObject`, which when accessed returns a string representing the location in the code at which `Error.captureStackTrace()` was called.
```js
const myObject = {};
Error.captureStackTrace(myObject);
myObject.stack; // Similar to `new Error().stack`
```
The first line of the trace will be prefixed with `${myObject.name}: ${myObject.message}`.
The optional `constructorOpt` argument accepts a function. If given, all frames above `constructorOpt`, including `constructorOpt`, will be omitted from the generated stack trace.
The `constructorOpt` argument is useful for hiding implementation details of error generation from the user. For instance:
```js
function a() {
b();
}
function b() {
c();
}
function c() {
// Create an error without stack trace to avoid calculating the stack trace twice.
const { stackTraceLimit } = Error;
Error.stackTraceLimit = 0;
const error = new Error();
Error.stackTraceLimit = stackTraceLimit;
// Capture the stack trace above function b
Error.captureStackTrace(error, b); // Neither function c, nor b is included in the stack trace
throw error;
}
a();
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ----------------- | ---------- |
| `targetObject` | `object` |
| `constructorOpt?` | `Function` |
#### Returns
[Section titled “Returns”](#returns-1)
`void`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-6)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`captureStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#capturestacktrace)
***
### prepareStackTrace()
[Section titled “prepareStackTrace()”](#preparestacktrace)
```ts
static prepareStackTrace(err, stackTraces): any;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| ------------- | ------------- |
| `err` | `Error` |
| `stackTraces` | `CallSite`\[] |
#### Returns
[Section titled “Returns”](#returns-2)
`any`
#### See
[Section titled “See”](#see)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-7)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`prepareStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#preparestacktrace)
# ModelRefusalError
Error thrown when the model refuses to produce output.
## Extends
[Section titled “Extends”](#extends)
* [`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new ModelRefusalError(refusal, state?): ModelRefusalError;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | --------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `refusal` | `string` |
| `state?` | [`RunState`](/openai-agents-js/openai/agents-core/classes/runstate/)<`any`, [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`any`, `any`>> |
#### Returns
[Section titled “Returns”](#returns)
`ModelRefusalError`
#### Overrides
[Section titled “Overrides”](#overrides)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`constructor`](/openai-agents-js/openai/agents-core/classes/agentserror/#constructor)
## Properties
[Section titled “Properties”](#properties)
### message
[Section titled “message”](#message)
```ts
message: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`message`](/openai-agents-js/openai/agents-core/classes/agentserror/#message)
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`name`](/openai-agents-js/openai/agents-core/classes/agentserror/#name)
***
### refusal
[Section titled “refusal”](#refusal)
```ts
refusal: string;
```
The refusal text returned by the model.
***
### stack?
[Section titled “stack?”](#stack)
```ts
optional stack?: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stack`](/openai-agents-js/openai/agents-core/classes/agentserror/#stack)
***
### state?
[Section titled “state?”](#state)
```ts
optional state?: RunState>;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`state`](/openai-agents-js/openai/agents-core/classes/agentserror/#state)
***
### stackTraceLimit
[Section titled “stackTraceLimit”](#stacktracelimit)
```ts
static stackTraceLimit: number;
```
The `Error.stackTraceLimit` property specifies the number of stack frames collected by a stack trace (whether generated by `new Error().stack` or `Error.captureStackTrace(obj)`).
The default value is `10` but may be set to any valid JavaScript number. Changes will affect any stack trace captured *after* the value has been changed.
If set to a non-number value, or set to a negative number, stack traces will not capture any frames.
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stackTraceLimit`](/openai-agents-js/openai/agents-core/classes/agentserror/#stacktracelimit)
## Methods
[Section titled “Methods”](#methods)
### captureStackTrace()
[Section titled “captureStackTrace()”](#capturestacktrace)
```ts
static captureStackTrace(targetObject, constructorOpt?): void;
```
Creates a `.stack` property on `targetObject`, which when accessed returns a string representing the location in the code at which `Error.captureStackTrace()` was called.
```js
const myObject = {};
Error.captureStackTrace(myObject);
myObject.stack; // Similar to `new Error().stack`
```
The first line of the trace will be prefixed with `${myObject.name}: ${myObject.message}`.
The optional `constructorOpt` argument accepts a function. If given, all frames above `constructorOpt`, including `constructorOpt`, will be omitted from the generated stack trace.
The `constructorOpt` argument is useful for hiding implementation details of error generation from the user. For instance:
```js
function a() {
b();
}
function b() {
c();
}
function c() {
// Create an error without stack trace to avoid calculating the stack trace twice.
const { stackTraceLimit } = Error;
Error.stackTraceLimit = 0;
const error = new Error();
Error.stackTraceLimit = stackTraceLimit;
// Capture the stack trace above function b
Error.captureStackTrace(error, b); // Neither function c, nor b is included in the stack trace
throw error;
}
a();
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ----------------- | ---------- |
| `targetObject` | `object` |
| `constructorOpt?` | `Function` |
#### Returns
[Section titled “Returns”](#returns-1)
`void`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`captureStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#capturestacktrace)
***
### prepareStackTrace()
[Section titled “prepareStackTrace()”](#preparestacktrace)
```ts
static prepareStackTrace(err, stackTraces): any;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| ------------- | ------------- |
| `err` | `Error` |
| `stackTraces` | `CallSite`\[] |
#### Returns
[Section titled “Returns”](#returns-2)
`any`
#### See
[Section titled “See”](#see)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-6)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`prepareStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#preparestacktrace)
# NoopSpan
## Extends
[Section titled “Extends”](#extends)
* [`Span`](/openai-agents-js/openai/agents-core/classes/span/)<`TSpanData`>
## Type Parameters
[Section titled “Type Parameters”](#type-parameters)
| Type Parameter |
| ----------------------------------------------------------------------------------------------- |
| `TSpanData` *extends* [`SpanData`](/openai-agents-js/openai/agents-core/type-aliases/spandata/) |
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new NoopSpan(data, processor): NoopSpan;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| ----------- | --------------------------------------------------------------------------------------- |
| `data` | `TSpanData` |
| `processor` | [`TracingProcessor`](/openai-agents-js/openai/agents-core/interfaces/tracingprocessor/) |
#### Returns
[Section titled “Returns”](#returns)
`NoopSpan`<`TSpanData`>
#### Overrides
[Section titled “Overrides”](#overrides)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`constructor`](/openai-agents-js/openai/agents-core/classes/span/#constructor)
## Properties
[Section titled “Properties”](#properties)
### type
[Section titled “type”](#type)
```ts
type: "trace.span";
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`type`](/openai-agents-js/openai/agents-core/classes/span/#type)
## Accessors
[Section titled “Accessors”](#accessors)
### endedAt
[Section titled “endedAt”](#endedat)
#### Get Signature
[Section titled “Get Signature”](#get-signature)
```ts
get endedAt(): string | null;
```
##### Returns
[Section titled “Returns”](#returns-1)
`string` | `null`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`endedAt`](/openai-agents-js/openai/agents-core/classes/span/#endedat)
***
### error
[Section titled “error”](#error)
#### Get Signature
[Section titled “Get Signature”](#get-signature-1)
```ts
get error():
| SpanError
| null;
```
##### Returns
[Section titled “Returns”](#returns-2)
\| [`SpanError`](/openai-agents-js/openai/agents-core/type-aliases/spanerror/) | `null`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`error`](/openai-agents-js/openai/agents-core/classes/span/#error)
***
### parentId
[Section titled “parentId”](#parentid)
#### Get Signature
[Section titled “Get Signature”](#get-signature-2)
```ts
get parentId(): string | null;
```
##### Returns
[Section titled “Returns”](#returns-3)
`string` | `null`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`parentId`](/openai-agents-js/openai/agents-core/classes/span/#parentid)
***
### previousSpan
[Section titled “previousSpan”](#previousspan)
#### Get Signature
[Section titled “Get Signature”](#get-signature-3)
```ts
get previousSpan():
| Span
| undefined;
```
##### Returns
[Section titled “Returns”](#returns-4)
\| [`Span`](/openai-agents-js/openai/agents-core/classes/span/)<`any`> | `undefined`
#### Set Signature
[Section titled “Set Signature”](#set-signature)
```ts
set previousSpan(span): void;
```
##### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| --------- | ------------------------------------------------------------------------------------- |
| `span` | \| [`Span`](/openai-agents-js/openai/agents-core/classes/span/)<`any`> \| `undefined` |
##### Returns
[Section titled “Returns”](#returns-5)
`void`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`previousSpan`](/openai-agents-js/openai/agents-core/classes/span/#previousspan)
***
### spanData
[Section titled “spanData”](#spandata)
#### Get Signature
[Section titled “Get Signature”](#get-signature-4)
```ts
get spanData(): TData;
```
##### Returns
[Section titled “Returns”](#returns-6)
`TData`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`spanData`](/openai-agents-js/openai/agents-core/classes/span/#spandata)
***
### spanId
[Section titled “spanId”](#spanid)
#### Get Signature
[Section titled “Get Signature”](#get-signature-5)
```ts
get spanId(): string;
```
##### Returns
[Section titled “Returns”](#returns-7)
`string`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-6)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`spanId`](/openai-agents-js/openai/agents-core/classes/span/#spanid)
***
### startedAt
[Section titled “startedAt”](#startedat)
#### Get Signature
[Section titled “Get Signature”](#get-signature-6)
```ts
get startedAt(): string | null;
```
##### Returns
[Section titled “Returns”](#returns-8)
`string` | `null`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-7)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`startedAt`](/openai-agents-js/openai/agents-core/classes/span/#startedat)
***
### traceId
[Section titled “traceId”](#traceid)
#### Get Signature
[Section titled “Get Signature”](#get-signature-7)
```ts
get traceId(): string;
```
##### Returns
[Section titled “Returns”](#returns-9)
`string`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-8)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`traceId`](/openai-agents-js/openai/agents-core/classes/span/#traceid)
***
### traceMetadata
[Section titled “traceMetadata”](#tracemetadata)
#### Get Signature
[Section titled “Get Signature”](#get-signature-8)
```ts
get traceMetadata(): Record | undefined;
```
##### Returns
[Section titled “Returns”](#returns-10)
`Record`<`string`, `any`> | `undefined`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-9)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`traceMetadata`](/openai-agents-js/openai/agents-core/classes/span/#tracemetadata)
***
### tracingApiKey
[Section titled “tracingApiKey”](#tracingapikey)
#### Get Signature
[Section titled “Get Signature”](#get-signature-9)
```ts
get tracingApiKey(): string | undefined;
```
##### Returns
[Section titled “Returns”](#returns-11)
`string` | `undefined`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-10)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`tracingApiKey`](/openai-agents-js/openai/agents-core/classes/span/#tracingapikey)
## Methods
[Section titled “Methods”](#methods)
### clone()
[Section titled “clone()”](#clone)
```ts
clone(): Span;
```
#### Returns
[Section titled “Returns”](#returns-12)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/)<`TSpanData`>
#### Inherited from
[Section titled “Inherited from”](#inherited-from-11)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`clone`](/openai-agents-js/openai/agents-core/classes/span/#clone)
***
### end()
[Section titled “end()”](#end)
```ts
end(): void;
```
#### Returns
[Section titled “Returns”](#returns-13)
`void`
#### Overrides
[Section titled “Overrides”](#overrides-1)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`end`](/openai-agents-js/openai/agents-core/classes/span/#end)
***
### setError()
[Section titled “setError()”](#seterror)
```ts
setError(): void;
```
#### Returns
[Section titled “Returns”](#returns-14)
`void`
#### Overrides
[Section titled “Overrides”](#overrides-2)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`setError`](/openai-agents-js/openai/agents-core/classes/span/#seterror)
***
### start()
[Section titled “start()”](#start)
```ts
start(): void;
```
#### Returns
[Section titled “Returns”](#returns-15)
`void`
#### Overrides
[Section titled “Overrides”](#overrides-3)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`start`](/openai-agents-js/openai/agents-core/classes/span/#start)
***
### toJSON()
[Section titled “toJSON()”](#tojson)
```ts
toJSON(): null;
```
#### Returns
[Section titled “Returns”](#returns-16)
`null`
#### Overrides
[Section titled “Overrides”](#overrides-4)
[`Span`](/openai-agents-js/openai/agents-core/classes/span/).[`toJSON`](/openai-agents-js/openai/agents-core/classes/span/#tojson)
# NoopTrace
## Extends
[Section titled “Extends”](#extends)
* [`Trace`](/openai-agents-js/openai/agents-core/classes/trace/)
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new NoopTrace(): NoopTrace;
```
#### Returns
[Section titled “Returns”](#returns)
`NoopTrace`
#### Overrides
[Section titled “Overrides”](#overrides)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`constructor`](/openai-agents-js/openai/agents-core/classes/trace/#constructor)
## Properties
[Section titled “Properties”](#properties)
### groupId
[Section titled “groupId”](#groupid)
```ts
groupId: string | null = null;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`groupId`](/openai-agents-js/openai/agents-core/classes/trace/#groupid)
***
### metadata?
[Section titled “metadata?”](#metadata)
```ts
optional metadata?: Record;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`metadata`](/openai-agents-js/openai/agents-core/classes/trace/#metadata)
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`name`](/openai-agents-js/openai/agents-core/classes/trace/#name)
***
### traceId
[Section titled “traceId”](#traceid)
```ts
traceId: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`traceId`](/openai-agents-js/openai/agents-core/classes/trace/#traceid)
***
### tracingApiKey?
[Section titled “tracingApiKey?”](#tracingapikey)
```ts
optional tracingApiKey?: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`tracingApiKey`](/openai-agents-js/openai/agents-core/classes/trace/#tracingapikey)
***
### type
[Section titled “type”](#type)
```ts
type: "trace";
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`type`](/openai-agents-js/openai/agents-core/classes/trace/#type)
## Methods
[Section titled “Methods”](#methods)
### clone()
[Section titled “clone()”](#clone)
```ts
clone(): Trace;
```
#### Returns
[Section titled “Returns”](#returns-1)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-6)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`clone`](/openai-agents-js/openai/agents-core/classes/trace/#clone)
***
### end()
[Section titled “end()”](#end)
```ts
end(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-2)
`Promise`<`void`>
#### Overrides
[Section titled “Overrides”](#overrides-1)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`end`](/openai-agents-js/openai/agents-core/classes/trace/#end)
***
### start()
[Section titled “start()”](#start)
```ts
start(): Promise;
```
#### Returns
[Section titled “Returns”](#returns-3)
`Promise`<`void`>
#### Overrides
[Section titled “Overrides”](#overrides-2)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`start`](/openai-agents-js/openai/agents-core/classes/trace/#start)
***
### toJSON()
[Section titled “toJSON()”](#tojson)
```ts
toJSON(): object | null;
```
Serializes the trace for export or persistence. Set `includeTracingApiKey` to true only when you intentionally need to persist the exporter credentials (for example, when handing off a run to another process that cannot access the original environment). Defaults to false to avoid leaking secrets.
#### Returns
[Section titled “Returns”](#returns-4)
`object` | `null`
#### Overrides
[Section titled “Overrides”](#overrides-3)
[`Trace`](/openai-agents-js/openai/agents-core/classes/trace/).[`toJSON`](/openai-agents-js/openai/agents-core/classes/trace/#tojson)
# OutputGuardrailTripwireTriggered
Error thrown when an output guardrail tripwire is triggered.
## Extends
[Section titled “Extends”](#extends)
* [`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/)
## Type Parameters
[Section titled “Type Parameters”](#type-parameters)
| Type Parameter | Default type |
| ----------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------- |
| `TMeta` *extends* [`OutputGuardrailMetadata`](/openai-agents-js/openai/agents-core/interfaces/outputguardrailmetadata/) | ‐ |
| `TOutputType` *extends* [`AgentOutputType`](/openai-agents-js/openai/agents-core/type-aliases/agentoutputtype/) | [`TextOutput`](/openai-agents-js/openai/agents-core/type-aliases/textoutput/) |
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new OutputGuardrailTripwireTriggered(
message,
result,
state?): OutputGuardrailTripwireTriggered;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | ------------------------------------------------------------------------------------------------------------------------- |
| `message` | `string` |
| `result` | [`OutputGuardrailResult`](/openai-agents-js/openai/agents-core/interfaces/outputguardrailresult/)<`TMeta`, `TOutputType`> |
| `state?` | [`RunState`](/openai-agents-js/openai/agents-core/classes/runstate/)<`any`, `any`> |
#### Returns
[Section titled “Returns”](#returns)
`OutputGuardrailTripwireTriggered`<`TMeta`, `TOutputType`>
#### Overrides
[Section titled “Overrides”](#overrides)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`constructor`](/openai-agents-js/openai/agents-core/classes/agentserror/#constructor)
## Properties
[Section titled “Properties”](#properties)
### message
[Section titled “message”](#message)
```ts
message: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`message`](/openai-agents-js/openai/agents-core/classes/agentserror/#message)
***
### name
[Section titled “name”](#name)
```ts
name: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-1)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`name`](/openai-agents-js/openai/agents-core/classes/agentserror/#name)
***
### result
[Section titled “result”](#result)
```ts
result: OutputGuardrailResult;
```
***
### stack?
[Section titled “stack?”](#stack)
```ts
optional stack?: string;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-2)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stack`](/openai-agents-js/openai/agents-core/classes/agentserror/#stack)
***
### state?
[Section titled “state?”](#state)
```ts
optional state?: RunState>;
```
#### Inherited from
[Section titled “Inherited from”](#inherited-from-3)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`state`](/openai-agents-js/openai/agents-core/classes/agentserror/#state)
***
### stackTraceLimit
[Section titled “stackTraceLimit”](#stacktracelimit)
```ts
static stackTraceLimit: number;
```
The `Error.stackTraceLimit` property specifies the number of stack frames collected by a stack trace (whether generated by `new Error().stack` or `Error.captureStackTrace(obj)`).
The default value is `10` but may be set to any valid JavaScript number. Changes will affect any stack trace captured *after* the value has been changed.
If set to a non-number value, or set to a negative number, stack traces will not capture any frames.
#### Inherited from
[Section titled “Inherited from”](#inherited-from-4)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`stackTraceLimit`](/openai-agents-js/openai/agents-core/classes/agentserror/#stacktracelimit)
## Methods
[Section titled “Methods”](#methods)
### captureStackTrace()
[Section titled “captureStackTrace()”](#capturestacktrace)
```ts
static captureStackTrace(targetObject, constructorOpt?): void;
```
Creates a `.stack` property on `targetObject`, which when accessed returns a string representing the location in the code at which `Error.captureStackTrace()` was called.
```js
const myObject = {};
Error.captureStackTrace(myObject);
myObject.stack; // Similar to `new Error().stack`
```
The first line of the trace will be prefixed with `${myObject.name}: ${myObject.message}`.
The optional `constructorOpt` argument accepts a function. If given, all frames above `constructorOpt`, including `constructorOpt`, will be omitted from the generated stack trace.
The `constructorOpt` argument is useful for hiding implementation details of error generation from the user. For instance:
```js
function a() {
b();
}
function b() {
c();
}
function c() {
// Create an error without stack trace to avoid calculating the stack trace twice.
const { stackTraceLimit } = Error;
Error.stackTraceLimit = 0;
const error = new Error();
Error.stackTraceLimit = stackTraceLimit;
// Capture the stack trace above function b
Error.captureStackTrace(error, b); // Neither function c, nor b is included in the stack trace
throw error;
}
a();
```
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type |
| ----------------- | ---------- |
| `targetObject` | `object` |
| `constructorOpt?` | `Function` |
#### Returns
[Section titled “Returns”](#returns-1)
`void`
#### Inherited from
[Section titled “Inherited from”](#inherited-from-5)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`captureStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#capturestacktrace)
***
### prepareStackTrace()
[Section titled “prepareStackTrace()”](#preparestacktrace)
```ts
static prepareStackTrace(err, stackTraces): any;
```
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type |
| ------------- | ------------- |
| `err` | `Error` |
| `stackTraces` | `CallSite`\[] |
#### Returns
[Section titled “Returns”](#returns-2)
`any`
#### See
[Section titled “See”](#see)
#### Inherited from
[Section titled “Inherited from”](#inherited-from-6)
[`AgentsError`](/openai-agents-js/openai/agents-core/classes/agentserror/).[`prepareStackTrace`](/openai-agents-js/openai/agents-core/classes/agentserror/#preparestacktrace)
# RequestUsage
Usage details for a single API request.
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new RequestUsage(input?): RequestUsage;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | ------------------------------ |
| `input?` | `Partial`<`object` & `object`> |
#### Returns
[Section titled “Returns”](#returns)
`RequestUsage`
## Properties
[Section titled “Properties”](#properties)
### endpoint?
[Section titled “endpoint?”](#endpoint)
```ts
optional endpoint?: string & object | "responses.create" | "responses.compact";
```
The endpoint that produced this usage entry (e.g., responses.create, responses.compact).
***
### inputTokens
[Section titled “inputTokens”](#inputtokens)
```ts
inputTokens: number;
```
The number of input tokens used for this request.
***
### inputTokensDetails
[Section titled “inputTokensDetails”](#inputtokensdetails)
```ts
inputTokensDetails: Record;
```
Details about the input tokens used for this request.
***
### outputTokens
[Section titled “outputTokens”](#outputtokens)
```ts
outputTokens: number;
```
The number of output tokens used for this request.
***
### outputTokensDetails
[Section titled “outputTokensDetails”](#outputtokensdetails)
```ts
outputTokensDetails: Record;
```
Details about the output tokens used for this request.
***
### totalTokens
[Section titled “totalTokens”](#totaltokens)
```ts
totalTokens: number;
```
The total number of tokens sent and received for this request.
# RunAgentUpdatedStreamEvent
Event that notifies that there is a new agent running.
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new RunAgentUpdatedStreamEvent(agent): RunAgentUpdatedStreamEvent;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type | Description |
| --------- | ---------------------------------------------------------------------------- | ------------- |
| `agent` | [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`any`, `any`> | The new agent |
#### Returns
[Section titled “Returns”](#returns)
`RunAgentUpdatedStreamEvent`
## Properties
[Section titled “Properties”](#properties)
### agent
[Section titled “agent”](#agent)
```ts
agent: Agent;
```
The new agent
***
### type
[Section titled “type”](#type)
```ts
readonly type: "agent_updated_stream_event" = 'agent_updated_stream_event';
```
# RunContext
A context object that is passed to the `Runner.run()` method.
## Type Parameters
[Section titled “Type Parameters”](#type-parameters)
| Type Parameter | Default type |
| -------------- | ------------------------------------------------------------------------------------- |
| `TContext` | [`UnknownContext`](/openai-agents-js/openai/agents-core/type-aliases/unknowncontext/) |
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new RunContext(context?): RunContext;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type |
| --------- | ---------- |
| `context` | `TContext` |
#### Returns
[Section titled “Returns”](#returns)
`RunContext`<`TContext`>
## Properties
[Section titled “Properties”](#properties)
### context
[Section titled “context”](#context)
```ts
context: TContext;
```
The context object you passed to the `Runner.run()` method.
***
### toolInput?
[Section titled “toolInput?”](#toolinput)
```ts
optional toolInput?: unknown;
```
Structured input for the current agent tool run, when available.
***
### usage
[Section titled “usage”](#usage)
```ts
usage: Usage;
```
The usage of the agent run so far. For streamed responses, the usage will be updated in real-time
## Methods
[Section titled “Methods”](#methods)
### approveTool()
[Section titled “approveTool()”](#approvetool)
```ts
approveTool(approvalItem, options?): void;
```
Approve a tool call.
#### Parameters
[Section titled “Parameters”](#parameters-1)
| Parameter | Type | Description |
| ------------------------ | ------------------------------------------------------------------------------------------ | ------------------------------------- |
| `approvalItem` | [`RunToolApprovalItem`](/openai-agents-js/openai/agents-core/classes/runtoolapprovalitem/) | The tool approval item to approve. |
| `options` | { `alwaysApprove?`: `boolean`; } | Additional approval behavior options. |
| `options.alwaysApprove?` | `boolean` | ‐ |
#### Returns
[Section titled “Returns”](#returns-1)
`void`
***
### getRejectionMessage()
[Section titled “getRejectionMessage()”](#getrejectionmessage)
```ts
getRejectionMessage(toolName, callId): string | undefined;
```
Retrieve the caller-provided rejection message for a specific tool call.
#### Parameters
[Section titled “Parameters”](#parameters-2)
| Parameter | Type | Description |
| ---------- | -------- | ----------------------------------- |
| `toolName` | `string` | The name of the tool. |
| `callId` | `string` | The call ID of the tool invocation. |
#### Returns
[Section titled “Returns”](#returns-2)
`string` | `undefined`
The message string if one was provided, `undefined` otherwise.
***
### isToolApproved()
[Section titled “isToolApproved()”](#istoolapproved)
```ts
isToolApproved(approval): boolean | undefined;
```
Check if a tool call has been approved.
#### Parameters
[Section titled “Parameters”](#parameters-3)
| Parameter | Type | Description |
| ------------------- | --------------------------------------------- | -------------------------------------------- |
| `approval` | { `callId`: `string`; `toolName`: `string`; } | Details about the tool call being evaluated. |
| `approval.callId` | `string` | ‐ |
| `approval.toolName` | `string` | ‐ |
#### Returns
[Section titled “Returns”](#returns-3)
`boolean` | `undefined`
`true` if the tool call has been approved, `false` if blocked and `undefined` if not yet approved or rejected.
***
### rejectTool()
[Section titled “rejectTool()”](#rejecttool)
```ts
rejectTool(approvalItem, __namedParameters?): void;
```
Reject a tool call.
#### Parameters
[Section titled “Parameters”](#parameters-4)
| Parameter | Type | Description |
| --------------------------------- | ------------------------------------------------------------------------------------------ | --------------------------------- |
| `approvalItem` | [`RunToolApprovalItem`](/openai-agents-js/openai/agents-core/classes/runtoolapprovalitem/) | The tool approval item to reject. |
| `__namedParameters` | { `alwaysReject?`: `boolean`; `message?`: `string`; } | ‐ |
| `__namedParameters.alwaysReject?` | `boolean` | ‐ |
| `__namedParameters.message?` | `string` | ‐ |
#### Returns
[Section titled “Returns”](#returns-4)
`void`
***
### toJSON()
[Section titled “toJSON()”](#tojson)
```ts
toJSON(): RunContextJson;
```
#### Returns
[Section titled “Returns”](#returns-5)
`RunContextJson`
# RunHandoffCallItem
## Extends
[Section titled “Extends”](#extends)
* `RunItemBase`
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new RunHandoffCallItem(rawItem, agent): RunHandoffCallItem;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type | Description |
| ----------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `rawItem` | { `arguments`: `string`; `callId`: `string`; `id?`: `string`; `name`: `string`; `namespace?`: `string`; `providerData?`: `Record`<`string`, `any`>; `status?`: `"in_progress"` \| `"completed"` \| `"incomplete"`; `type`: `"function_call"`; } | ‐ |
| `rawItem.arguments` | `string` | The arguments of the function call. |
| `rawItem.callId` | `string` | The ID of the tool call. Required to match up the respective tool call result. |
| `rawItem.id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `rawItem.name` | `string` | The name of the function. |
| `rawItem.namespace?` | `string` | Optional namespace used to qualify the function name for tool search. |
| `rawItem.providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `rawItem.status?` | `"in_progress"` \| `"completed"` \| `"incomplete"` | The status of the function call. |
| `rawItem.type` | `"function_call"` | ‐ |
| `agent` | [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/) | ‐ |
#### Returns
[Section titled “Returns”](#returns)
`RunHandoffCallItem`
#### Overrides
[Section titled “Overrides”](#overrides)
```ts
RunItemBase.constructor
```
## Properties
[Section titled “Properties”](#properties)
### agent
[Section titled “agent”](#agent)
```ts
agent: Agent;
```
***
### rawItem
[Section titled “rawItem”](#rawitem)
```ts
rawItem: object;
```
| Name | Type | Description |
| --------------- | -------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `arguments` | `string` | The arguments of the function call. |
| `callId` | `string` | The ID of the tool call. Required to match up the respective tool call result. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `name` | `string` | The name of the function. |
| `namespace?` | `string` | Optional namespace used to qualify the function name for tool search. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status?` | `"in_progress"` \| `"completed"` \| `"incomplete"` | The status of the function call. |
| `type` | `"function_call"` | ‐ |
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
```ts
RunItemBase.rawItem
```
***
### type
[Section titled “type”](#type)
```ts
readonly type: "handoff_call_item";
```
#### Overrides
[Section titled “Overrides”](#overrides-1)
```ts
RunItemBase.type
```
## Methods
[Section titled “Methods”](#methods)
### toJSON()
[Section titled “toJSON()”](#tojson)
```ts
toJSON(): object;
```
#### Returns
[Section titled “Returns”](#returns-1)
`object`
##### agent
[Section titled “agent”](#agent-1)
```ts
agent: object;
```
###### agent.name
[Section titled “agent.name”](#agentname)
```ts
name: string;
```
##### rawItem
[Section titled “rawItem”](#rawitem-1)
```ts
rawItem:
| {
content: (
| {
providerData?: Record;
refusal: string;
type: "refusal";
}
| {
providerData?: Record;
text: string;
type: "output_text";
}
| {
audio: | string
| {
id: string;
};
format?: string | null;
providerData?: Record;
transcript?: string | null;
type: "audio";
}
| {
image: string;
providerData?: Record;
type: "image";
})[];
id?: string;
providerData?: Record;
role: "assistant";
status: "in_progress" | "completed" | "incomplete";
type?: "message";
}
| {
content: | string
| (
| {
providerData?: Record;
text: string;
type: "input_text";
}
| {
detail?: string;
image?: | string
| {
id: string;
};
providerData?: Record;
type: "input_image";
}
| {
file?: | string
| {
id: string;
}
| {
url: string;
};
filename?: string;
providerData?: Record;
type: "input_file";
}
| {
audio: | string
| {
id: string;
};
format?: string | null;
providerData?: Record;
transcript?: string | null;
type: "audio";
})[];
id?: string;
providerData?: Record;
role: "user";
type?: "message";
}
| {
content: string;
id?: string;
providerData?: Record;
role: "system";
type?: "message";
}
| {
arguments?: string;
id?: string;
name: string;
output?: string;
providerData?: Record;
status?: string;
type: "hosted_tool_call";
}
| {
arguments: string;
callId: string;
id?: string;
name: string;
namespace?: string;
providerData?: Record;
status?: "in_progress" | "completed" | "incomplete";
type: "function_call";
}
| {
arguments: unknown;
call_id?: string | null;
callId?: string | null;
execution?: "client" | "server";
id?: string;
providerData?: Record;
status?: string;
type: "tool_search_call";
}
| {
call_id?: string | null;
callId?: string | null;
execution?: "client" | "server";
id?: string;
providerData?: Record;
status?: string;
tools: Record[];
type: "tool_search_output";
}
| {
callId: string;
id?: string;
name: string;
namespace?: string;
output: | string
| {
providerData?: Record;
text: string;
type: "text";
}
| {
detail?: "low" | "high" | "auto" | string & object;
image?: | string
| {
data: string | Uint8Array;
mediaType?: string;
}
| {
url: string;
}
| {
fileId: string;
};
providerData?: Record;
type: "image";
}
| {
file: | string
| {
data: string | Uint8Array;
filename: string;
mediaType: string;
}
| {
filename?: string;
url: string;
}
| {
filename?: string;
id: string;
};
providerData?: Record;
type: "file";
}
| (
| {
providerData?: Record;
text: string;
type: "input_text";
}
| {
detail?: string;
image?: | string
| {
id: string;
};
providerData?: Record;
type: "input_image";
}
| {
file?: | string
| {
id: string;
}
| {
url: string;
};
filename?: string;
providerData?: Record;
type: "input_file";
})[];
providerData?: Record;
status: "in_progress" | "completed" | "incomplete";
type: "function_call_result";
}
| {
action?: | {
type: "screenshot";
}
| {
button: "left" | "right" | "wheel" | "back" | "forward";
type: "click";
x: number;
y: number;
}
| {
type: "double_click";
x: number;
y: number;
}
| {
scroll_x: number;
scroll_y: number;
type: "scroll";
x: number;
y: number;
}
| {
text: string;
type: "type";
}
| {
type: "wait";
}
| {
type: "move";
x: number;
y: number;
}
| {
keys: string[];
type: "keypress";
}
| {
path: object[];
type: "drag";
};
actions?: (
| {
type: "screenshot";
}
| {
button: "left" | "right" | "wheel" | "back" | "forward";
type: "click";
x: number;
y: number;
}
| {
type: "double_click";
x: number;
y: number;
}
| {
scroll_x: number;
scroll_y: number;
type: "scroll";
x: number;
y: number;
}
| {
text: string;
type: "type";
}
| {
type: "wait";
}
| {
type: "move";
x: number;
y: number;
}
| {
keys: string[];
type: "keypress";
}
| {
path: object[];
type: "drag";
})[];
callId: string;
id?: string;
providerData?: Record;
status: "in_progress" | "completed" | "incomplete";
type: "computer_call";
}
| {
callId: string;
id?: string;
output: {
data: string;
providerData?: Record;
type: "computer_screenshot";
};
providerData?: Record;
type: "computer_call_result";
}
| {
action: {
commands: string[];
maxOutputLength?: number;
timeoutMs?: number;
};
callId: string;
id?: string;
providerData?: Record;
status?: "in_progress" | "completed" | "incomplete";
type: "shell_call";
}
| {
callId: string;
id?: string;
maxOutputLength?: number;
output: object[];
providerData?: Record;
type: "shell_call_output";
}
| {
callId: string;
id?: string;
operation: | {
diff: string;
path: string;
type: "create_file";
}
| {
diff: string;
moveTo?: string;
path: string;
type: "update_file";
}
| {
path: string;
type: "delete_file";
};
providerData?: Record;
status: "in_progress" | "completed";
type: "apply_patch_call";
}
| {
callId: string;
id?: string;
output?: string;
providerData?: Record;
status: "completed" | "failed";
type: "apply_patch_call_output";
}
| {
content: object[];
id?: string;
providerData?: Record;
rawContent?: object[];
type: "reasoning";
}
| {
created_by?: string;
encrypted_content: string;
id?: string;
providerData?: Record;
type: "compaction";
}
| {
id?: string;
providerData?: Record;
type: "unknown";
}
| undefined;
```
###### Union Members
[Section titled “Union Members”](#union-members)
###### Type Literal
[Section titled “Type Literal”](#type-literal)
```ts
{
content: (
| {
providerData?: Record;
refusal: string;
type: "refusal";
}
| {
providerData?: Record;
text: string;
type: "output_text";
}
| {
audio: | string
| {
id: string;
};
format?: string | null;
providerData?: Record;
transcript?: string | null;
type: "audio";
}
| {
image: string;
providerData?: Record;
type: "image";
})[];
id?: string;
providerData?: Record;
role: "assistant";
status: "in_progress" | "completed" | "incomplete";
type?: "message";
}
```
| Name | Type | Description |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `content` | ( \| { `providerData?`: `Record`<`string`, `any`>; `refusal`: `string`; `type`: `"refusal"`; } \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"output_text"`; } \| { `audio`: \| `string` \| { `id`: `string`; }; `format?`: `string` \| `null`; `providerData?`: `Record`<`string`, `any`>; `transcript?`: `string` \| `null`; `type`: `"audio"`; } \| { `image`: `string`; `providerData?`: `Record`<`string`, `any`>; `type`: `"image"`; })\[] | The content of the message. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `role` | `"assistant"` | Representing a message from the assistant (i.e. the model) |
| `status` | `"in_progress"` \| `"completed"` \| `"incomplete"` | The status of the message. |
| `type?` | `"message"` | Any item without a type is treated as a message |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-1)
```ts
{
content: | string
| (
| {
providerData?: Record;
text: string;
type: "input_text";
}
| {
detail?: string;
image?: | string
| {
id: string;
};
providerData?: Record;
type: "input_image";
}
| {
file?: | string
| {
id: string;
}
| {
url: string;
};
filename?: string;
providerData?: Record;
type: "input_file";
}
| {
audio: | string
| {
id: string;
};
format?: string | null;
providerData?: Record;
transcript?: string | null;
type: "audio";
})[];
id?: string;
providerData?: Record;
role: "user";
type?: "message";
}
```
| Name | Type | Description |
| --------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `content` | \| `string` \| ( \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"input_text"`; } \| { `detail?`: `string`; `image?`: \| `string` \| { `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_image"`; } \| { `file?`: \| `string` \| { `id`: `string`; } \| { `url`: `string`; }; `filename?`: `string`; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_file"`; } \| { `audio`: \| `string` \| { `id`: `string`; }; `format?`: `string` \| `null`; `providerData?`: `Record`<`string`, `any`>; `transcript?`: `string` \| `null`; `type`: `"audio"`; })\[] | The content of the message. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `role` | `"user"` | Representing a message from the user |
| `type?` | `"message"` | Any item without a type is treated as a message |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-2)
```ts
{
content: string;
id?: string;
providerData?: Record;
role: "system";
type?: "message";
}
```
| Name | Type | Description |
| --------------- | ------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `content` | `string` | The content of the message. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `role` | `"system"` | Representing a system message to the user |
| `type?` | `"message"` | Any item without a type is treated as a message |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-3)
```ts
{
arguments?: string;
id?: string;
name: string;
output?: string;
providerData?: Record;
status?: string;
type: "hosted_tool_call";
}
```
| Name | Type | Description |
| --------------- | ------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `arguments?` | `string` | The arguments of the hosted tool call. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `name` | `string` | The name of the hosted tool. For example `web_search_call` or `file_search_call` |
| `output?` | `string` | The primary output of the tool call. Additional output might be in the `providerData` field. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status?` | `string` | The status of the tool call. |
| `type` | `"hosted_tool_call"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-4)
```ts
{
arguments: string;
callId: string;
id?: string;
name: string;
namespace?: string;
providerData?: Record;
status?: "in_progress" | "completed" | "incomplete";
type: "function_call";
}
```
| Name | Type | Description |
| --------------- | -------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `arguments` | `string` | The arguments of the function call. |
| `callId` | `string` | The ID of the tool call. Required to match up the respective tool call result. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `name` | `string` | The name of the function. |
| `namespace?` | `string` | Optional namespace used to qualify the function name for tool search. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status?` | `"in_progress"` \| `"completed"` \| `"incomplete"` | The status of the function call. |
| `type` | `"function_call"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-5)
```ts
{
arguments: unknown;
call_id?: string | null;
callId?: string | null;
execution?: "client" | "server";
id?: string;
providerData?: Record;
status?: string;
type: "tool_search_call";
}
```
| Name | Type | Default value | Description |
| --------------- | ------------------------- | ------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `arguments` | `unknown` | `ToolSearchCallArguments` | ‐ |
| `call_id?` | `string` \| `null` | ‐ | ‐ |
| `callId?` | `string` \| `null` | ‐ | ‐ |
| `execution?` | `"client"` \| `"server"` | ‐ | ‐ |
| `id?` | `string` | ‐ | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `providerData?` | `Record`<`string`, `any`> | ‐ | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status?` | `string` | ‐ | ‐ |
| `type` | `"tool_search_call"` | ‐ | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-6)
```ts
{
call_id?: string | null;
callId?: string | null;
execution?: "client" | "server";
id?: string;
providerData?: Record;
status?: string;
tools: Record[];
type: "tool_search_output";
}
```
| Name | Type | Description |
| --------------- | ---------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `call_id?` | `string` \| `null` | ‐ |
| `callId?` | `string` \| `null` | ‐ |
| `execution?` | `"client"` \| `"server"` | ‐ |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status?` | `string` | ‐ |
| `tools` | `Record`<`string`, `any`>\[] | ‐ |
| `type` | `"tool_search_output"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-7)
```ts
{
callId: string;
id?: string;
name: string;
namespace?: string;
output: | string
| {
providerData?: Record;
text: string;
type: "text";
}
| {
detail?: "low" | "high" | "auto" | string & object;
image?: | string
| {
data: string | Uint8Array;
mediaType?: string;
}
| {
url: string;
}
| {
fileId: string;
};
providerData?: Record;
type: "image";
}
| {
file: | string
| {
data: string | Uint8Array;
filename: string;
mediaType: string;
}
| {
filename?: string;
url: string;
}
| {
filename?: string;
id: string;
};
providerData?: Record;
type: "file";
}
| (
| {
providerData?: Record;
text: string;
type: "input_text";
}
| {
detail?: string;
image?: | string
| {
id: string;
};
providerData?: Record;
type: "input_image";
}
| {
file?: | string
| {
id: string;
}
| {
url: string;
};
filename?: string;
providerData?: Record;
type: "input_file";
})[];
providerData?: Record;
status: "in_progress" | "completed" | "incomplete";
type: "function_call_result";
}
```
| Name | Type | Description |
| --------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `callId` | `string` | The ID of the tool call. Required to match up the respective tool call result. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `name` | `string` | The name of the tool that was called |
| `namespace?` | `string` | Optional namespace preserved from the originating function call. |
| `output` | \| `string` \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"text"`; } \| { `detail?`: `"low"` \| `"high"` \| `"auto"` \| `string` & `object`; `image?`: \| `string` \| { `data`: `string` \| `Uint8Array`<`ArrayBuffer`>; `mediaType?`: `string`; } \| { `url`: `string`; } \| { `fileId`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"image"`; } \| { `file`: \| `string` \| { `data`: `string` \| `Uint8Array`<`ArrayBuffer`>; `filename`: `string`; `mediaType`: `string`; } \| { `filename?`: `string`; `url`: `string`; } \| { `filename?`: `string`; `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"file"`; } \| ( \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"input_text"`; } \| { `detail?`: `string`; `image?`: \| `string` \| { `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_image"`; } \| { `file?`: \| `string` \| { `id`: `string`; } \| { `url`: `string`; }; `filename?`: `string`; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_file"`; })\[] | The output of the tool call. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status` | `"in_progress"` \| `"completed"` \| `"incomplete"` | The status of the tool call. |
| `type` | `"function_call_result"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-8)
```ts
{
action?: | {
type: "screenshot";
}
| {
button: "left" | "right" | "wheel" | "back" | "forward";
type: "click";
x: number;
y: number;
}
| {
type: "double_click";
x: number;
y: number;
}
| {
scroll_x: number;
scroll_y: number;
type: "scroll";
x: number;
y: number;
}
| {
text: string;
type: "type";
}
| {
type: "wait";
}
| {
type: "move";
x: number;
y: number;
}
| {
keys: string[];
type: "keypress";
}
| {
path: object[];
type: "drag";
};
actions?: (
| {
type: "screenshot";
}
| {
button: "left" | "right" | "wheel" | "back" | "forward";
type: "click";
x: number;
y: number;
}
| {
type: "double_click";
x: number;
y: number;
}
| {
scroll_x: number;
scroll_y: number;
type: "scroll";
x: number;
y: number;
}
| {
text: string;
type: "type";
}
| {
type: "wait";
}
| {
type: "move";
x: number;
y: number;
}
| {
keys: string[];
type: "keypress";
}
| {
path: object[];
type: "drag";
})[];
callId: string;
id?: string;
providerData?: Record;
status: "in_progress" | "completed" | "incomplete";
type: "computer_call";
}
```
| Name | Type | Description |
| --------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `action?` | \| { `type`: `"screenshot"`; } \| { `button`: `"left"` \| `"right"` \| `"wheel"` \| `"back"` \| `"forward"`; `type`: `"click"`; `x`: `number`; `y`: `number`; } \| { `type`: `"double_click"`; `x`: `number`; `y`: `number`; } \| { `scroll_x`: `number`; `scroll_y`: `number`; `type`: `"scroll"`; `x`: `number`; `y`: `number`; } \| { `text`: `string`; `type`: `"type"`; } \| { `type`: `"wait"`; } \| { `type`: `"move"`; `x`: `number`; `y`: `number`; } \| { `keys`: `string`\[]; `type`: `"keypress"`; } \| { `path`: `object`\[]; `type`: `"drag"`; } | The legacy single action to be performed by the computer. |
| `actions?` | ( \| { `type`: `"screenshot"`; } \| { `button`: `"left"` \| `"right"` \| `"wheel"` \| `"back"` \| `"forward"`; `type`: `"click"`; `x`: `number`; `y`: `number`; } \| { `type`: `"double_click"`; `x`: `number`; `y`: `number`; } \| { `scroll_x`: `number`; `scroll_y`: `number`; `type`: `"scroll"`; `x`: `number`; `y`: `number`; } \| { `text`: `string`; `type`: `"type"`; } \| { `type`: `"wait"`; } \| { `type`: `"move"`; `x`: `number`; `y`: `number`; } \| { `keys`: `string`\[]; `type`: `"keypress"`; } \| { `path`: `object`\[]; `type`: `"drag"`; })\[] | Batched actions returned by the GA computer tool. |
| `callId` | `string` | The ID of the computer call. Required to match up the respective computer call result. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status` | `"in_progress"` \| `"completed"` \| `"incomplete"` | The status of the computer call. |
| `type` | `"computer_call"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-9)
```ts
{
callId: string;
id?: string;
output: {
data: string;
providerData?: Record;
type: "computer_screenshot";
};
providerData?: Record;
type: "computer_call_result";
}
```
| Name | Type | Default value | Description |
| ---------------------- | ------------------------- | -------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `callId` | `string` | ‐ | The ID of the computer call. Required to match up the respective computer call result. |
| `id?` | `string` | ‐ | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `output` | `object` | `ComputerToolOutput` | The output of the computer call. |
| `output.data` | `string` | ‐ | A base64 encoded image data or a URL representing the screenshot. |
| `output.providerData?` | `Record`<`string`, `any`> | ‐ | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `output.type` | `"computer_screenshot"` | ‐ | ‐ |
| `providerData?` | `Record`<`string`, `any`> | ‐ | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `type` | `"computer_call_result"` | ‐ | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-10)
```ts
{
action: {
commands: string[];
maxOutputLength?: number;
timeoutMs?: number;
};
callId: string;
id?: string;
providerData?: Record;
status?: "in_progress" | "completed" | "incomplete";
type: "shell_call";
}
```
| Name | Type | Default value | Description |
| ------------------------- | -------------------------------------------------- | ------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `action` | `object` | `ShellAction` | ‐ |
| `action.commands` | `string`\[] | ‐ | ‐ |
| `action.maxOutputLength?` | `number` | ‐ | ‐ |
| `action.timeoutMs?` | `number` | ‐ | ‐ |
| `callId` | `string` | ‐ | ‐ |
| `id?` | `string` | ‐ | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `providerData?` | `Record`<`string`, `any`> | ‐ | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status?` | `"in_progress"` \| `"completed"` \| `"incomplete"` | ‐ | ‐ |
| `type` | `"shell_call"` | ‐ | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-11)
```ts
{
callId: string;
id?: string;
maxOutputLength?: number;
output: object[];
providerData?: Record;
type: "shell_call_output";
}
```
| Name | Type | Description |
| ------------------ | ------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `callId` | `string` | ‐ |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `maxOutputLength?` | `number` | ‐ |
| `output` | `object`\[] | ‐ |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `type` | `"shell_call_output"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-12)
```ts
{
callId: string;
id?: string;
operation: | {
diff: string;
path: string;
type: "create_file";
}
| {
diff: string;
moveTo?: string;
path: string;
type: "update_file";
}
| {
path: string;
type: "delete_file";
};
providerData?: Record;
status: "in_progress" | "completed";
type: "apply_patch_call";
}
```
| Name | Type | Default value | Description |
| --------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `callId` | `string` | ‐ | ‐ |
| `id?` | `string` | ‐ | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `operation` | \| { `diff`: `string`; `path`: `string`; `type`: `"create_file"`; } \| { `diff`: `string`; `moveTo?`: `string`; `path`: `string`; `type`: `"update_file"`; } \| { `path`: `string`; `type`: `"delete_file"`; } | `ApplyPatchOperation` | ‐ |
| `providerData?` | `Record`<`string`, `any`> | ‐ | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status` | `"in_progress"` \| `"completed"` | ‐ | ‐ |
| `type` | `"apply_patch_call"` | ‐ | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-13)
```ts
{
callId: string;
id?: string;
output?: string;
providerData?: Record;
status: "completed" | "failed";
type: "apply_patch_call_output";
}
```
| Name | Type | Description |
| --------------- | --------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `callId` | `string` | ‐ |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `output?` | `string` | ‐ |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status` | `"completed"` \| `"failed"` | ‐ |
| `type` | `"apply_patch_call_output"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-14)
```ts
{
content: object[];
id?: string;
providerData?: Record;
rawContent?: object[];
type: "reasoning";
}
```
| Name | Type | Description |
| --------------- | ------------------------- | ------------------------------------------------------------------------------------------------------------- |
| `content` | `object`\[] | The user facing representation of the reasoning. Additional information might be in the `providerData` field. |
| `id?` | `string` | ‐ |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `rawContent?` | `object`\[] | The raw reasoning text from the model. |
| `type` | `"reasoning"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-15)
```ts
{
created_by?: string;
encrypted_content: string;
id?: string;
providerData?: Record;
type: "compaction";
}
```
| Name | Type | Description |
| ------------------- | ------------------------- | ------------------------------------------------------------------------------------------------------------ |
| `created_by?` | `string` | Identifier for the generator of this compaction item. |
| `encrypted_content` | `string` | Encrypted payload returned by the compaction endpoint. |
| `id?` | `string` | Identifier for the compaction item. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `type` | `"compaction"` | ‐ |
***
###### Type Literal
[Section titled “Type Literal”](#type-literal-16)
```ts
{
id?: string;
providerData?: Record;
type: "unknown";
}
```
| Name | Type | Description |
| --------------- | ------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `type` | `"unknown"` | ‐ |
***
`undefined`
##### type
[Section titled “type”](#type-1)
```ts
type: string;
```
#### Overrides
[Section titled “Overrides”](#overrides-2)
```ts
RunItemBase.toJSON
```
# RunHandoffOutputItem
## Extends
[Section titled “Extends”](#extends)
* `RunItemBase`
## Constructors
[Section titled “Constructors”](#constructors)
### Constructor
[Section titled “Constructor”](#constructor)
```ts
new RunHandoffOutputItem(
rawItem,
sourceAgent,
targetAgent): RunHandoffOutputItem;
```
#### Parameters
[Section titled “Parameters”](#parameters)
| Parameter | Type | Description |
| ----------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `rawItem` | { `callId`: `string`; `id?`: `string`; `name`: `string`; `namespace?`: `string`; `output`: \| `string` \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"text"`; } \| { `detail?`: `"low"` \| `"high"` \| `"auto"` \| `string` & `object`; `image?`: \| `string` \| { `data`: `string` \| `Uint8Array`<`ArrayBuffer`>; `mediaType?`: `string`; } \| { `url`: `string`; } \| { `fileId`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"image"`; } \| { `file`: \| `string` \| { `data`: `string` \| `Uint8Array`<`ArrayBuffer`>; `filename`: `string`; `mediaType`: `string`; } \| { `filename?`: `string`; `url`: `string`; } \| { `filename?`: `string`; `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"file"`; } \| ( \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"input_text"`; } \| { `detail?`: `string`; `image?`: \| `string` \| { `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_image"`; } \| { `file?`: \| `string` \| { `id`: `string`; } \| { `url`: `string`; }; `filename?`: `string`; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_file"`; })\[]; `providerData?`: `Record`<`string`, `any`>; `status`: `"in_progress"` \| `"completed"` \| `"incomplete"`; `type`: `"function_call_result"`; } | ‐ |
| `rawItem.callId` | `string` | The ID of the tool call. Required to match up the respective tool call result. |
| `rawItem.id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `rawItem.name` | `string` | The name of the tool that was called |
| `rawItem.namespace?` | `string` | Optional namespace preserved from the originating function call. |
| `rawItem.output` | \| `string` \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"text"`; } \| { `detail?`: `"low"` \| `"high"` \| `"auto"` \| `string` & `object`; `image?`: \| `string` \| { `data`: `string` \| `Uint8Array`<`ArrayBuffer`>; `mediaType?`: `string`; } \| { `url`: `string`; } \| { `fileId`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"image"`; } \| { `file`: \| `string` \| { `data`: `string` \| `Uint8Array`<`ArrayBuffer`>; `filename`: `string`; `mediaType`: `string`; } \| { `filename?`: `string`; `url`: `string`; } \| { `filename?`: `string`; `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"file"`; } \| ( \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"input_text"`; } \| { `detail?`: `string`; `image?`: \| `string` \| { `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_image"`; } \| { `file?`: \| `string` \| { `id`: `string`; } \| { `url`: `string`; }; `filename?`: `string`; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_file"`; })\[] | The output of the tool call. |
| `rawItem.providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `rawItem.status` | `"in_progress"` \| `"completed"` \| `"incomplete"` | The status of the tool call. |
| `rawItem.type` | `"function_call_result"` | ‐ |
| `sourceAgent` | [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`any`, `any`> | ‐ |
| `targetAgent` | [`Agent`](/openai-agents-js/openai/agents-core/classes/agent/)<`any`, `any`> | ‐ |
#### Returns
[Section titled “Returns”](#returns)
`RunHandoffOutputItem`
#### Overrides
[Section titled “Overrides”](#overrides)
```ts
RunItemBase.constructor
```
## Properties
[Section titled “Properties”](#properties)
### rawItem
[Section titled “rawItem”](#rawitem)
```ts
rawItem: object;
```
| Name | Type | Description |
| --------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `callId` | `string` | The ID of the tool call. Required to match up the respective tool call result. |
| `id?` | `string` | An ID to identify the item. This is optional by default. If a model provider absolutely requires this field, it will be validated on the model level. |
| `name` | `string` | The name of the tool that was called |
| `namespace?` | `string` | Optional namespace preserved from the originating function call. |
| `output` | \| `string` \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"text"`; } \| { `detail?`: `"low"` \| `"high"` \| `"auto"` \| `string` & `object`; `image?`: \| `string` \| { `data`: `string` \| `Uint8Array`<`ArrayBuffer`>; `mediaType?`: `string`; } \| { `url`: `string`; } \| { `fileId`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"image"`; } \| { `file`: \| `string` \| { `data`: `string` \| `Uint8Array`<`ArrayBuffer`>; `filename`: `string`; `mediaType`: `string`; } \| { `filename?`: `string`; `url`: `string`; } \| { `filename?`: `string`; `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"file"`; } \| ( \| { `providerData?`: `Record`<`string`, `any`>; `text`: `string`; `type`: `"input_text"`; } \| { `detail?`: `string`; `image?`: \| `string` \| { `id`: `string`; }; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_image"`; } \| { `file?`: \| `string` \| { `id`: `string`; } \| { `url`: `string`; }; `filename?`: `string`; `providerData?`: `Record`<`string`, `any`>; `type`: `"input_file"`; })\[] | The output of the tool call. |
| `providerData?` | `Record`<`string`, `any`> | Additional optional provider specific data. Used for custom functionality or model provider specific fields. |
| `status` | `"in_progress"` \| `"completed"` \| `"incomplete"` | The status of the tool call. |
| `type` | `"function_call_result"` | ‐ |
#### Inherited from
[Section titled “Inherited from”](#inherited-from)
```ts
RunItemBase.rawItem
```
***
### sourceAgent
[Section titled “sourceAgent”](#sourceagent)
```ts
sourceAgent: Agent;
```
***
### targetAgent
[Section titled “targetAgent”](#targetagent)
```ts
targetAgent: Agent;
```
***
### type
[Section titled “type”](#type)
```ts
readonly type: "handoff_output_item";
```
#### Overrides
[Section titled “Overrides”](#overrides-1)
```ts
RunItemBase.type
```
## Methods
[Section titled “Methods”](#methods)
### toJSON()
[Section titled “toJSON()”](#tojson)
```ts
toJSON(): object;
```
#### Returns
[Section titled “Returns”](#returns-1)
`object`
##### rawItem
[Section titled “rawItem”](#rawitem-1)
```ts
rawItem:
| {
content: (
| {
providerData?: Record;
refusal: string;
type: "refusal";
}
| {
providerData?: Record;
text: string;
type: "output_text";
}
| {
audio: | string
| {
id: string;
};
format?: string | null;
providerData?: Record;
transcript?: string | null;
type: "audio";
}
| {
image: string;
providerData?: Record